




 本文介绍了一种利用无约束照片集进行自适应三维人脸重建的方法,适用于低质量和少量图像的情况。通过形变模型生成个性化模板,结合光度立体技术估计法线,进而重建精细人脸模型。实验表明该方法在重建精度上优于以往工作。
本文介绍了一种利用无约束照片集进行自适应三维人脸重建的方法,适用于低质量和少量图像的情况。通过形变模型生成个性化模板,结合光度立体技术估计法线,进而重建精细人脸模型。实验表明该方法在重建精度上优于以往工作。
基于无约束照片集的自适应三维人脸重建
《Adaptive 3D Face Reconstruction from Unconstrained Photo Collections》
文章来源:IEEE Computer Vision and Pattern Recognition (CVPR 2016)
文章链接:http://openaccess.thecvf.com/content_cvpr_2016/papers/Roth_Adaptive_3D_Face_CVPR_2016_paper.pdf
文章引用:Roth J , Tong Y , Liu X . Adaptive 3D Face Reconstruction from Unconstrained Photo Collections[C]// Proc. IEEE Computer Vision and Pattern Recognition (CVPR 2016). IEEE, 2016.
目录
本文提出了一种利用反照率信息重建三维人脸模型的方法,即使在较少图像的低质量照片集中,该方法也能适用。本文通过拟合3D变形模型以形成个性化模板,并在从粗到细的方案下开发新的光度立体公式来实现这一点。该方法的核心步骤:1)利用形变模型模板生成初始粗糙的人脸模板;2)使用光度立体技术(Photometric Stereo)为基础的方法估计个体的表面法线;3)使用估计的法线重建一个精细的人脸模型。
算法流程图:

一、数据准备和预处理
1、照片集合是包含个人面部的一组n张图像,并且可以用多种方式获得,例如,搜索名人的Google图像或个人照片集合。
2、从图像中检测和裁剪面部。本文使用Bob(一个用来信号处理和机器学习的工具箱)中内置的人脸检测模型,该模型在多种人脸数据集(如CMU-PIE)上训练,包括轮廓视图人脸。
3、给定人脸边界框,我们将图像转换为强度通道,并在人脸边界框之外裁剪,以确保包括整个人脸。为了估算二维坐标,我们采用最新的回归器级联方法将68个坐标自动拟合到每个图像上。
二、生成初始人脸模板
通过形变模型库生成一个初始的粗糙人脸模型:
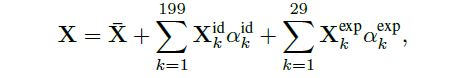
其中 是平均模型,
和
分别为形状和表情分量,通过矩阵奇异值分解获取;
和
分别为形状系数和表情系数。
为了将形变模型拟合到人脸图像,我们假设弱透视投影 ,其中
是尺度,
是旋转矩阵的前两行,
是图像平面上的平移。采用最小化以下能量函数来使投影误差最小化:
![]()
其中 是图像上的特征点坐标。将模型
代入能量方程求解:
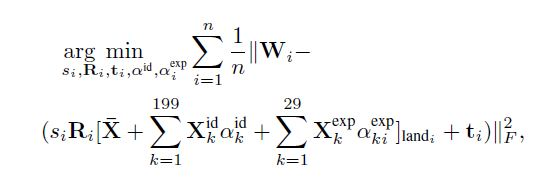
这个极小化函数不是联合凸的,但是由于它对于每个变量都是线性的,所以可以通过交替估计来解决。一旦学习了参数,我们就使用形状系数和表情系数的平均值来生成个性化模板
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1287
1287





 到【灌水乐园】发言
到【灌水乐园】发言







