



点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
论文作者 | WorldBench
编辑 | 自动驾驶之心
现有世界模型在视觉生成上已经相当逼真,但在几何一致性、时序稳定性和行为合理性上仍存在明显缺陷,而这些问题往往难以通过传统的视频质量指标被发现。针对这个问题WorldBech团队提出了WorldLens。
这一全方位基准用于评估模型构建、理解其生成世界并在其中行为的能力。它涵盖五个核心维度:生成质量、重建性能、指令跟随、下游任务适配性和人类偏好,全面覆盖视觉真实性、几何一致性、物理合理性和功能可靠性。评估结果显示,现有世界模型均无法实现全维度最优:部分模型纹理表现出色但违背物理规律,而几何稳定的模型则缺乏行为可信度。为使客观指标与人类对齐,WorldLens进一步构建了WorldLens-26K数据集——包含大规模人类标注视频,附带量化评分和文本说明,并开发了WorldLens-Agent评估模型,通过蒸馏这些标注数据实现可扩展、可解释的评分。基准、数据集与智能评估代理共同构成统一生态系统,用于衡量世界模型的保真度,为未来模型的评估提供标准化依据——不仅关注视觉真实感,更重视行为合理性。
论文标题:WorldLens: Full-Spectrum Evaluations of Driving World Models in Real World
项目主页:https://worldbench.github.io/worldlens
论文链接:https://arxiv.org/abs/2512.10958
汇总链接:https://github.com/worldbench/WorldLens
数据集:https://huggingface.co/datasets/worldbench/videogen
参与机构:新国立、中科院、澳门大学、中科大、浙大、地平线、南洋理工、华科、慕尼黑工大、复旦、上海人工智能实验室

一、背景回顾
生成式世界模型已彻底改变人工智能与仿真领域。从文本驱动的4D合成到可控驾驶环境生成,现代系统能够生成类似行车记录仪视角的序列,视觉真实感令人瞩目。然而,评估方法的发展却未能同步跟进:目前缺乏标准化手段来衡量生成世界是否保持几何结构、遵循物理规律,以及支持可靠的决策制定。
现有广泛使用的指标多侧重于帧质量和美学表现,但难以反映物理因果关系、多视角几何一致性或控制场景下的功能可靠性。近期多个综述已明确指出这一缺口,导致领域进展分散,研究结果缺乏可比性。尽管结构化成熟度量表(如SAE自动驾驶分级标准)已为自动驾驶基准测试提供清晰指引,但适用于驾驶世界模型评估、可直接落地的类似协议仍尚未出现。
为填补这一空白,我们构建了WorldLens——全方位基准,用于评估世界模型构建、理解其生成世界并在其中行为的能力。如图1所示,现有模型均无法实现全维度最优:部分模型实现了出色的纹理真实感但违背物理规律,而另一些模型虽能保持几何一致性,却在行为表现上存在缺陷。
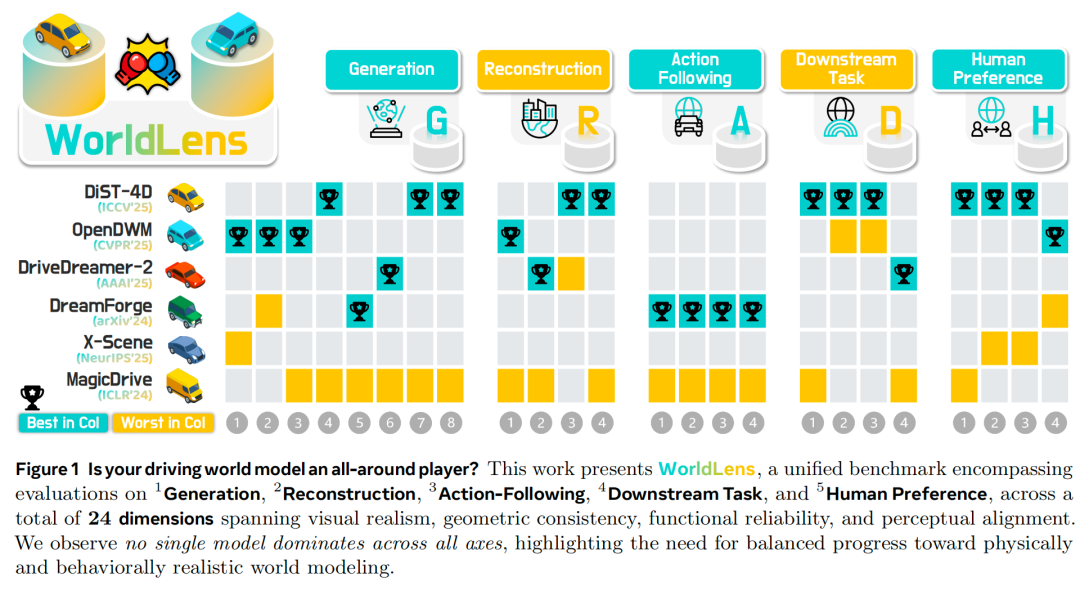
为揭示世界建模中的权衡关系,我们将评估拆解为五个互补维度:
生成质量:衡量模型能否合成视觉真实、时间稳定且语义一致的场景。即使是感知误差较低的最先进模型(如基于LPIPS、FVD指标),也常存在视角闪烁或运动不稳定问题,凸显当前扩散模型架构的局限性。
重建性能:考察生成视频能否通过可微分渲染重建成连贯的4D场景。许多在2D视角下表现清晰的模型,在重建过程中会出现几何“漂浮物”,表明多数模型的时间一致性与空间结构耦合较弱。
指令跟随:测试预训练动作规划器能否在生成世界中安全运行。高开环真实感并不意味着闭环控制的安全性,几乎所有现有世界模型都会导致碰撞或偏离车道等问题,说明仅靠 photometric真实感无法实现功能可靠性。
下游任务适配性:评估合成数据能否支持基于真实数据集训练的下游感知模型。即使视觉效果出色的生成世界,也可能导致检测或分割精度下降30%-50%,这表明与任务分布的对齐度(而非单纯图像质量)对实际应用至关重要。
人类偏好:通过大规模人类标注捕捉世界真实感、物理合理性和行为安全性等主观评分。研究发现,几何一致性强的模型通常被评为更“真实”,证实感知保真度与结构一致性密不可分。
为衔接算法指标与人类感知,我们构建了WorldLens-26K数据集——包含大规模人类标注视频,覆盖感知质量、物理规律和安全性等多个维度。每个样本均包含量化评分和文本说明,捕捉评估者对真实感、物理合理性和行为安全性的判断逻辑。通过将人类判断与结构化说明相结合,我们旨在将主观评估转化为可学习的监督信号,实现对生成式世界模型的感知对齐与可解释评估。
基于上述资源,我们开发了WorldLens-Agent——从人类偏好中蒸馏得到的反馈对齐自动评估器。该智能体能够预测感知和物理相关评分,同时生成与人类推理逻辑一致的自然语言说明。它对未见过的模型具有良好的泛化能力,无需重复人工标注即可实现生成世界的可扩展自动评估。
综上,我们的基准、数据集和评估代理共同构成统一生态系统,衔接客观测量与人类解读。我们将开源工具包、数据集和模型,推动标准化、可解释且与人类对齐的评估方法发展,引导未来世界模型不仅“看起来”真实,更能“表现”得合理。
二、WorldLens:全方位基准
生成式世界模型需超越视觉真实感,实现几何一致性、物理合理性与功能可靠性。我们提出WorldLens这一统一基准,从低层次外观保真度到高层次行为真实感,通过五个互补维度评估这些核心能力。如图2所示,每个维度均拆解为细粒度、可解释的子维度,形成衔接人类感知、物理推理与下游实用性的综合框架。
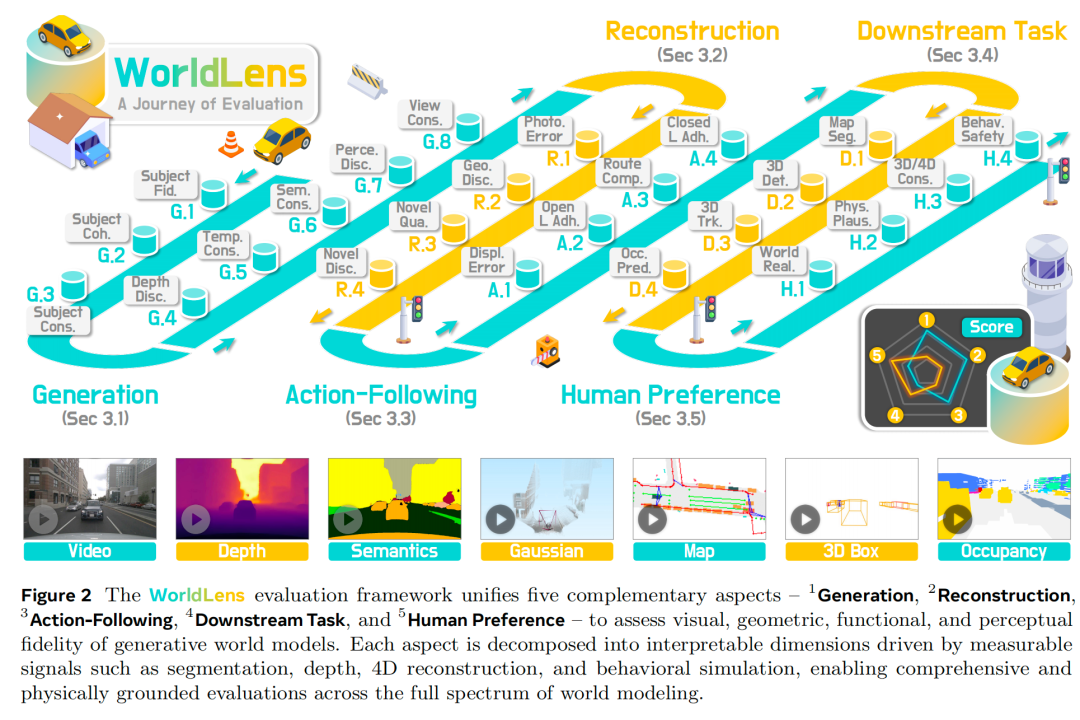
生成质量
该维度将整体生成质量拆解为八个互补子维度,评估外观保真度、时间稳定性、几何正确性与语义流畅性,量化模型在不同时间与视角下构建视觉及感知一致驾驶场景的“忠实度”。
目标保真度(Subject Fidelity):衡量车辆、行人等单个目标实例的感知真实感与语义正确性。对生成帧中的目标区域进行边界框裁剪,采用基于真实数据训练的类别专用二分类器评估,高置信度表明生成目标在视觉上与真实世界类别对齐,聚焦实例级保真度,补充全局指标的不足。
目标连贯性(Subject Coherence):评估目标在生成序列中的时间稳定性。通过已知跟踪ID,利用预训练ReID模型提取视觉嵌入并计算帧间相似度,高连贯性分数意味着目标在运动过程中保持形状、颜色和纹理一致,反映外观稳定性与身份持续性。
目标一致性(Subject Consistency):借助DINO特征捕捉目标的纹理与空间细节,评估目标级语义与几何的细粒度时间稳定性,确保目标在运动中结构与语义不变形、无闪烁,体现目标时间演化的可靠性与外观平滑变化特性。
深度差异度(Depth Discrepancy):通过Depth Anything V2估计单目深度并编码为彩色图,利用DINO v2提取嵌入,计算连续帧间特征平均距离,量化深度感知的连续性,数值越低表明场景运动的几何稳定性与物理合理性越强。
时间一致性(Temporal Consistency):在CLIP视觉编码器学习的外观空间中,量化帧间全局平滑度。通过相邻帧相似度、抖动抑制及与真实视频的运动速率对齐,评估动态过程的时间稳定性,高分数对应无突变、自然的动态演化。
语义一致性(Semantic Consistency):采用预训练SegFormer预测帧级掩码,计算标签、区域及类别分布的稳定性,确保生成视频的目标语义与场景结构无边界闪烁或标签不一致,维持语义布局的时间流畅性。
感知差异度(Perceptual Discrepancy):利用预训练I3D提取时空嵌入,计算真实与生成视频分布间的弗雷歇视频距离(FVD),量化两者的整体感知差距,数值越低表明外观与运动统计特性越相近,感知真实感与时间连贯性越强。
跨视角一致性(Cross-View Consistency):通过LoFTR检测同步相机对的特征对应关系并聚合置信度,评估相邻相机重叠区域的几何与光度对齐程度,高一致性确保多视角驾驶系统的3D一致生成,体现多视角下的结构对齐与视觉连续性。
重建性能
该维度聚焦生成视频恢复连贯4D场景的能力。将每个序列映射为高斯场,在原始与新视角轨迹下重新渲染,测试空间插值、视差效果及新视角路径的泛化能力。
光度误差(Photometric Error):衡量重建场景还原输入帧的准确性。将生成视频重建为可微分4D表示,在原始相机姿态下重新渲染,计算LPIPS、PSNR、SSIM等像素级相似度,反映外观与光照的时间稳定性,数值越低越利于实现忠实的4D重建。
几何差异度(Geometric Discrepancy):评估重建几何与真实世界结构的对齐程度。在相同相机姿态下,分别从生成序列与真实序列重建4D场景,对比渲染深度图,在Grounded-SAM 2筛选的区域内计算绝对相对误差(AbsRel),数值越低表明深度与表面几何越贴近真实场景。
新视角质量(Novel-View Quality):采用MUSIQ模型评估新视角轨迹下重建渲染帧的感知真实感。新视角轨迹包括前向中心插值、S形轨迹、横向偏移三种,高分数意味着新视角下的渲染帧清晰、无伪影、视觉连贯,体现模型在训练视角外的外观与光照一致性保持能力。
新视角差异度(Novel-View Discrepancy):在相同新视角轨迹下,计算生成重建与真实重建渲染视频的FVD,量化两者的感知差距,数值越低表明模型在未见过的视角下,仍能维持4D空间中几何、外观与时间动态的连贯性。
指令跟随
该维度评估生成世界支持预训练规划器做出合理驾驶决策的能力,检验合成场景是否提供与真实世界一致的视觉及运动线索。所有评估在生成式模拟器中进行,采用基于真实世界地图设计的自定义路线,对标标准基准。
位移误差(Displacement Error):评估生成视频在运动规划下游任务中的功能一致性。利用预训练端到端规划器(UniAD或VAD)分别从生成视频与真实视频预测未来路径点,计算平均L2距离,数值越低表明生成场景保留了准确轨迹预测所需的运动线索,功能保真度越高。
开环适配度(Open-Loop Adherence):在非反应式仿真环境中,采用预测驾驶模型分数(PDMS)评估预训练策略的性能。PDMS聚合安全性、进度、舒适度等子分数,高分数意味着仅基于生成视觉输入,策略仍能展现真实、稳定、安全的驾驶行为,反映短期功能真实感。
路线完成率(Route Completion):在闭环仿真中,计算车辆在碰撞、偏离车道或超时终止前完成预定义路线的百分比,高完成率表明生成环境支持长期、物理一致的控制,保障目标导向运动的持续性。
闭环适配度(Closed-Loop Adherence):通过场地驾驶分数(ADS)整合运动质量与任务完成度,由PDMS与路线完成率相乘得到。高ADS分数表明规划器在闭环仿真中既能安全驾驶,又能有效完成路线,证实生成世界不仅“看起来真实”,且在自主控制闭环中“驾驶起来真实”。
下游任务适配性
该维度通过评估预训练3D感知模型在合成数据上的性能,衡量生成视频的下游实用性。任务性能下降程度反映生成场景的真实感、保真度与迁移能力,具体涵盖四个代表性下游任务:
地图分割(Map Segmentation):评估生成数据是否包含足够的空间与语义线索,支持鸟瞰图(BEV)映射。采用预训练BEV地图分割网络预测语义地图,以平均交并比(mIoU)衡量性能,高mIoU表明场景结构布局与语义利于准确BEV重建。
3D目标检测(3D Object Detection):测试生成数据是否保留感知交通参与者所需的几何线索。将预训练BEVFusion应用于生成帧,采用nuScenes检测分数(NDS)评估,高分数意味着生成场景支持更精准的3D目标定位。
3D目标跟踪(3D Object Tracking):评估生成视频中目标运动一致性与身份信息保留能力。利用预训练3D跟踪器预测3D轨迹,以nuScenes协议下的平均多目标跟踪精度(AMOTA)衡量,高AMOTA反映3D场景中运动目标的时间动态稳定性与数据关联准确性。
占用预测(Occupancy Prediction):采用RayIoU指标,对比相机光线上的语义一致性(而非体素重叠),评估生成场景支持3D几何与语义重建的准确性。高RayIoU表明生成视频保留了下游场景理解所需的3D结构完整性,实现深度一致的占用估计。
人类偏好
该维度通过大规模人类标注,评估生成视频在视觉真实性、物理连贯性与行为安全性上与人类判断的对齐程度,各子维度采用1-10分评分制,分数越高表明人类感知保真度越强。
世界真实感(World Realism):从整体场景连贯性、车辆几何与运动稳定性、行人身体比例与行走一致性三个子维度,评估纹理、光照、运动与真实驾驶画面的贴近程度,高分数意味着场景在视觉上与真实录制难以区分。
物理合理性(Physical Plausibility):聚焦运动连续性、遮挡顺序正确性、目标接触稳定性与光照时间一致性,评估场景是否遵循直观物理定律与因果关系。存在瞬移、穿透、反射不一致等现象的场景得分较低,而动态过程平滑、物理连贯的场景得分更高。
3D与4D一致性(3D & 4D Consistency):评估重建3D结构的时间稳定性,以及目标相对位置、姿态与轨迹的持续性,高一致性表明生成视频形成符合真实世界动态的合理4D场景,维持空间-时间维度的几何与外观连贯性。
行为安全性(Behavioral Safety):评估交通参与者行为的可预测性与安全性,聚焦车辆、行人与环境线索的短期交互,如交通信号遵守、碰撞规避、车道保持等。突发碰撞、违规穿越等不安全行为会降低分数,平滑、合法、可控的运动对应更高分数,体现行为的可信度与合规性。
人类标注与评估代理
标注流程
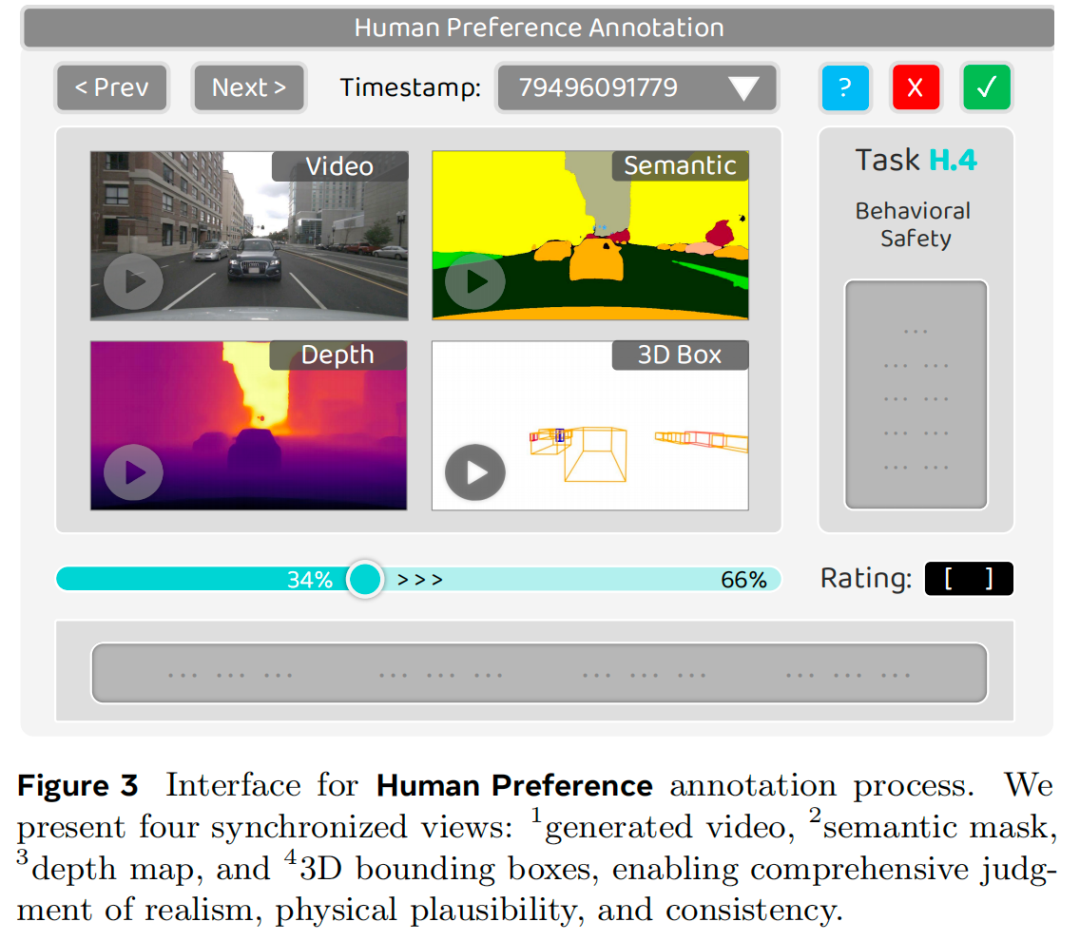
为给基准建立可靠的人类监督,我们设计了结构化多阶段标注流程。10名标注员分为两组,独立对3.5节定义的四个维度进行全视频评分;当两组评分存在分歧时,重新评估样本以确保一致性。标注界面同步展示四个视图:生成视频、语义掩码、深度图与3D边界框(如图3所示)。所有标注员均获得含评分等级示例的详细文档,以提升一致性与领域理解。平均每条标注耗时约2分8秒,总耗时超930小时。更多实现细节、文档与示例见附录。
WorldLens-26K:多样化偏好数据集
为衔接人类判断与自动化评估,我们构建了包含26,808条生成视频评分记录的大规模人类标注数据集。每条记录均含离散分数与标注员撰写的简洁文本说明,同时涵盖感知质量的多个互补维度,均衡覆盖世界模型真实感的空间、时间与行为层面。如图4所示,文本说明的词云与对应目标维度高度契合,证实标注标签的有效性与可解释性。我们期望WorldLens-26K成为训练评估代理、构建人类对齐奖励函数或优势函数的基础资源,助力生成式世界模型的强化微调。
WorldLens-Agent:基于人类反馈的监督微调评估器
生成世界的评估依赖物理合理性等人类中心准则与感知真实感等主观偏好,这些是量化指标难以捕捉的,因此亟需人类对齐的评估工具。为此,我们提出WorldLens-Agent,一种基于WorldLens-26K训练的视觉-语言评论代理。通过LoRA-based监督微调,将人类的感知与物理判断蒸馏到Qwen3-VL-8B模型中,使其内化真实感、合理性、行为安全性等评估准则,提供一致、人类对齐的评估结果,为未来世界模型基准测试提供可扩展的偏好基准。更多分布外视频的自动评分与说明生成示例,见图8及附录。

四、实验结果分析
我们在WorldLens定义的所有五个维度上,对代表性驾驶世界模型进行了全面评估,涵盖定量评估与人类参与评估。
各维度评估
生成质量:如表1所示,所有现有模型的表现均显著低于“经验最大值”,表明驾驶世界模型的视觉与时间真实感仍有巨大提升空间。尽管DiST-4D实现了最低的感知差异度,但在目标保真度和跨视角一致性上不如OpenDWM,这表明仅靠感知指标不足以评估物理连贯的场景生成能力。OpenDWM的整体表现最为均衡,这很大程度上得益于大规模多数据集训练;而MagicDrive、X-Scene等单数据集模型在所有指标上的泛化能力有限。值得注意的是,DiST-4D、DriveDreamer-2等基于条件输入的方法通过利用真实帧,将深度一致性和跨视角一致性提升了20%-30%,部分克服了上述局限性。这些结果表明,对于实现可靠、时间一致的世界建模,数据集多样性和条件输入策略比感知保真度更为关键。
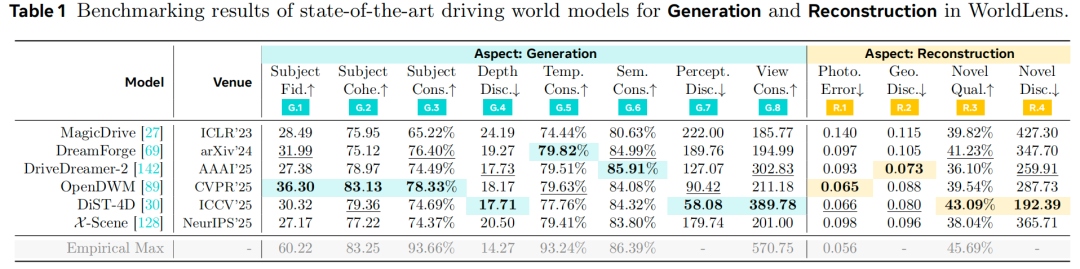
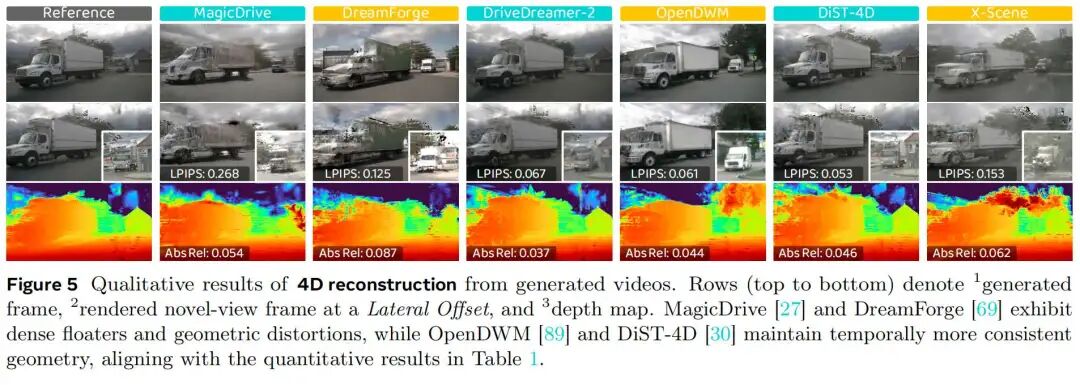
重建性能:我们通过将生成视频重建为4D高斯场来评估时空3D连贯性,其中“漂浮物”和几何不稳定性直接反映时间不一致性。如表1所示,MagicDrive的重建性能最差,其光度误差和几何差异度均比OpenDWM高出两倍以上。DreamForge也存在类似缺陷,表明其3D一致性有限。相比之下,OpenDWM和DiST-4D的重建效果显著更优,将光度误差和几何误差降低了约55%,生成的序列结构更连贯。DiST-4D的新视角质量表现最佳,这可能得益于其RGB-D生成设计,能更好地长期保留深度信息。如图5所示,MagicDrive和DreamForge在侧视视角下会产生大量漂浮物和畸变,而OpenDWM和DiST-4D则能保持清晰、稳定的几何结构。综上,时间稳定性和几何一致性是生成物理真实、可重建世界模型的关键要素。
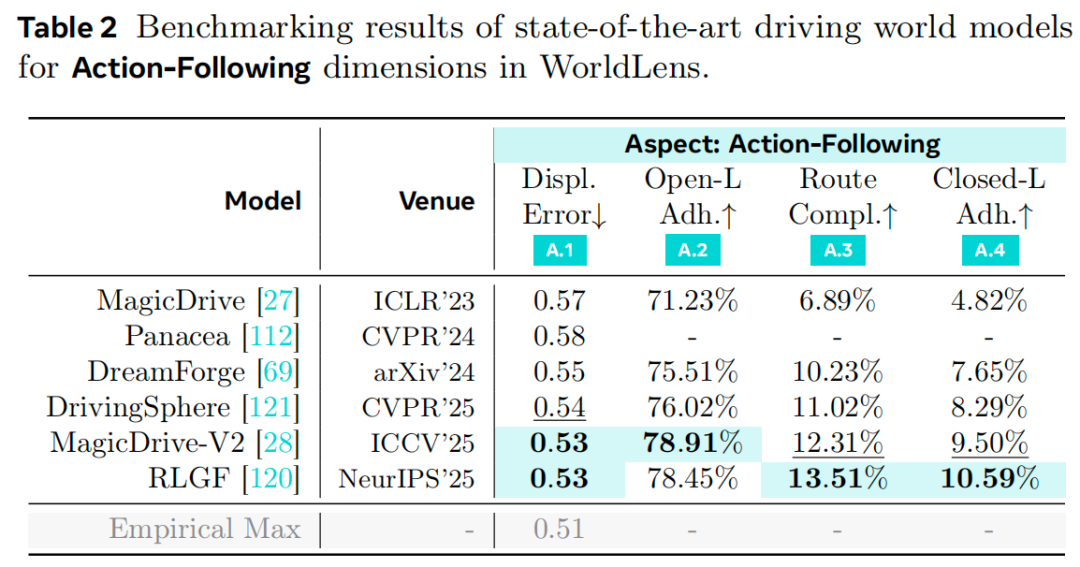
指令跟随:如表2所示,我们通过闭环仿真评估合成环境的功能可行性——预训练规划器在各模型生成的“世界”中运行。时间连贯性被证明至关重要:规划代理依赖多帧历史和自车状态线索,时间稳定性较弱的模型路线完成率最低。一个显著发现是开环与闭环性能存在巨大差距:尽管所有方法在位移误差和PDMS上的开环表现良好,但在闭环条件下均表现不佳,路线完成率极低。频繁的失败(如碰撞、偏离车道)表明,当前合成数据仍无法在高级控制任务中替代真实世界数据。这一结果凸显核心洞见:提升生成式世界模型的物理真实性和因果真实性,对于有效部署闭环系统不可或缺。
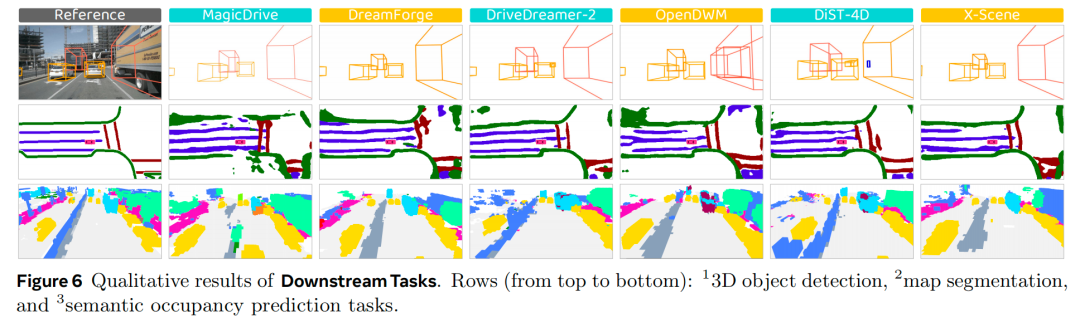
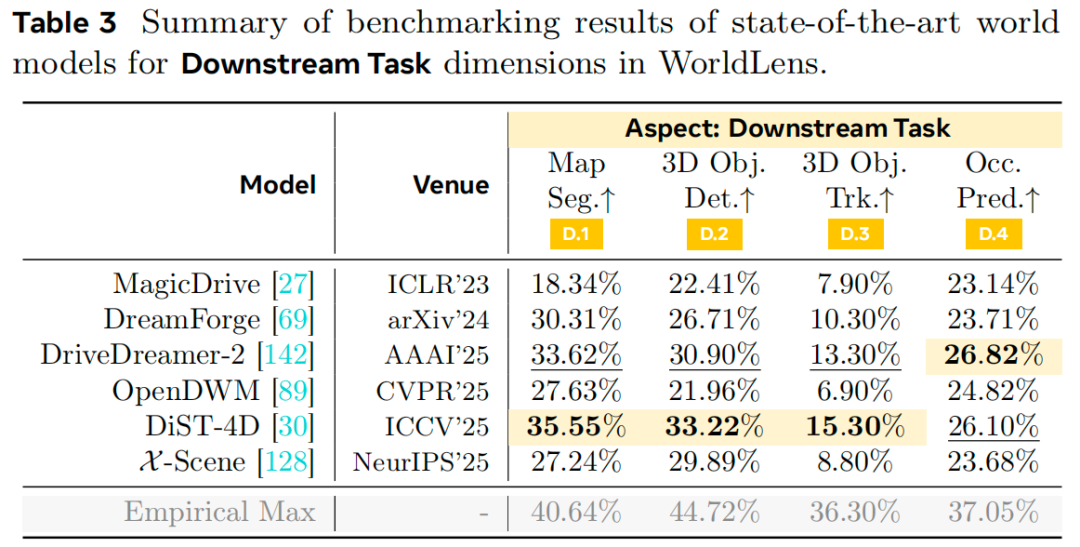
下游任务适配性:该维度直接反映世界模型超越视觉真实感的实际效用。如表3和图1所示,DiST-4D在所有任务(地图分割、3D检测、跟踪)中均大幅领先,平均比第二名模型高出30%-40%。DriveDreamer-2排名第二,尤其在占用预测任务中表现突出,彰显了时间条件输入对连贯视频生成的优势。相比之下,MagicDrive在所有任务中表现最差,证实其时空连贯性有限。有趣的是,尽管OpenDWM的感知质量出色,但在检测(21.9%)和跟踪(6.9%)任务中表现不佳,这表明大规模多域训练可能会阻碍模型对特定数据集分布的适配。图6的定性评估进一步验证了上述观察。综上,时间条件输入和数据集对齐对于提升实际应用中的任务特异性效果至关重要。
人类偏好对齐
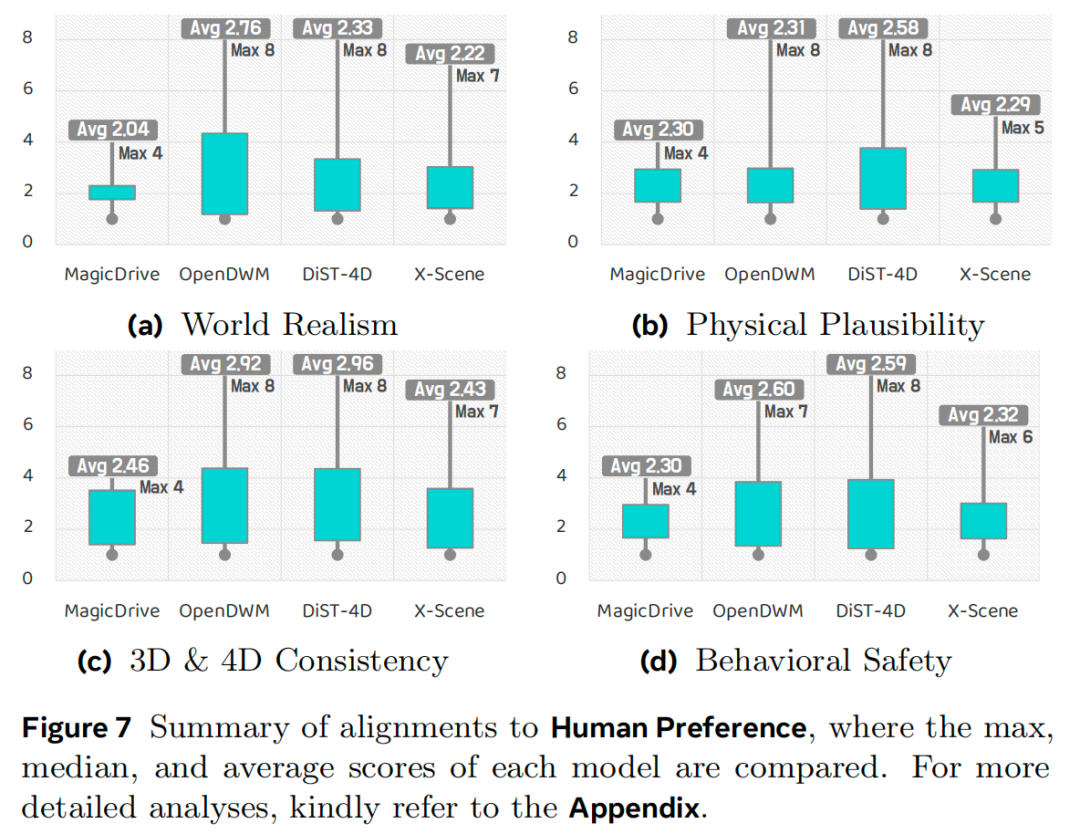
主观评估:由于定量指标无法捕捉世界建模的所有方面,我们针对世界真实感、物理合理性、3D与4D一致性及行为安全性开展了人类评估。如图7所示,所有模型的整体得分均较为温和(10分制中的2到3分),表明当前世界模型与人类级真实感仍有较大差距。DiST-4D在所有维度上的得分最为均衡,在物理合理性(2.58分)和行为安全性(2.59分)上领先;OpenDWM的真实感得分最高(2.76分),但物理一致性略低;MagicDrive的整体排名最低,反映其连贯性较差。值得注意的是,世界真实感与一致性得分高度相关,表明人类感知的真实感与几何及时间稳定性紧密耦合。综上,这些结果凸显了人类参与评估的必要性——它能补充定量基准的不足,为世界模型质量提供全面评估。
人机代理对齐:为评估自动评估器WorldLens-Agent的泛化能力,我们在Gen3C生成的视频上进行了零样本测试(如图8所示)。该代理的预测得分与人类标注在所有评估维度上均表现出强对齐性,证实其能够捕捉细微的主观偏好。除数值一致性外,代理生成的文本说明与人类标注者的表述高度相似,既实现了得分层面的一致性,又保证了解释层面的连贯性。这些结果表明,利用人类标注的感知数据训练评估代理,能够为未来世界模型基准测试提供可扩展、可解释且可复现的评估工具。
Insight与讨论
全面评估至关重要:没有任何单一世界模型能在所有方面表现最优(图1):DiST-4D在几何和新视角指标上表现最佳,OpenDWM在光度保真度上领先,DriveDreamer-2的深度准确性最高。这种差异表明,视觉真实感、几何一致性和下游可用性是互补而非可替代的,凸显了多维度基准测试的必要性。
感知质量不代表可用性:感知得分优异的模型(如OpenDWM)可能在下游任务中表现不佳。尽管OpenDWM的视觉保真度出色,但其3D检测得分比DiST-4D低30%,这表明大规模多域训练可能阻碍模型对任务特异性分布的适配。因此,对于有效下游应用而言,生成数据与目标域的对齐比感知真实感更为关键。
几何感知赋能物理连贯性:DiST-4D在重建和新视角任务中的优异表现,源于其RGB-D生成设计和解耦时空扩散架构——两者共同建模时间预测和空间合成。这表明,几何感知监督能显著提升生成场景的物理真实性和可重建性。
外观与几何的联合优化:光度指标(LPIPS/PSNR)与几何指标(AbsRel)之间的差异表明,当前模型常将纹理和结构视为独立优化目标:几何感知监督能稳定深度但会模糊细节,而外观驱动训练能锐化纹理却会破坏空间一致性。通过时空正则化联合优化外观与几何的统一框架,才能实现连贯的重建效果。
未来世界模型设计指南:基于实验结果,我们提炼出物理接地世界模型的核心设计原则:1)将几何作为核心优化目标:显式深度预测或监督能同时提升重建保真度和下游感知性能;2)稳定前景动态:一致的几何结构是可靠运动解纠缠的关键;3)确保自回归鲁棒性:强化跨视角和时间一致性以减少漂移和结构伪影,同时通过自强制训练或流式扩散提升闭环生成中对累积误差的鲁棒性——这对长时程稳定性至关重要。综上,稳健的世界模型源于外观、几何与任务适配性的联合优化,需从视觉真实感向物理可靠性进阶。
五、结论
我们提出了WorldLens——一款全方位基准,从感知、几何、功能和人类对齐四个视角评估生成式世界模型。通过五个互补评估维度和二十余项标准化指标,该基准提供了衡量物理真实感与感知真实感的统一协议。结合WorldLens-26K数据集和WorldLens-Agent智能评估器,我们的框架为未来世界模型基准测试建立了可扩展、可解释的基础——引导研究向“不仅看起来真实,更能表现得合理”的系统迈进。
自动驾驶之心
世界模型与自动驾驶小班课来了!


















 210
210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









