



点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
作为国际Tier1巨头的博世,今年也被国内智驾的飞速发展卷到了。根据最新的信息,博世汽车电子猛抓预研和量产两条线。量产方面博世投入更多的资源落地一段式端到端,近期也招聘到不少技术专家加入。自动驾驶之心也期待博世后续的量产车型,并会在第一时间跟进。
预研方面,我们看到了很多优秀的算法工作,其中不少自动驾驶之心都首发报道过。在这些已经公开的工作中,有几位值得大家留意:Ren Liu,Yao Yuhan,Sun Hao,Zhang frank,Jiang Anqing,Zhang Youjian等等。整体上来看,博世在自驾以下几个方向投入较大:
端到端和VLA:打榜的DiffVLA、Diffuson改进AnchDrive、FlowDrive、闭环强化学习框架IRL-VLA、纯血Impromptu VLA等等;
静态感知:中稿IROS的SparseMeXT和在线地图工作DiffSemanticFusion;
此外还有一些闭环仿真方面的工作D GS(NeurIPS 2025)和视觉基础模型DINO-R1等。作为一家近140年的老牌企业,博世的工程师文化非常浓厚。柱哥有幸和博世的几位技术专家交流过,更能切身感受到他们务实的精神。相比去年,博世可谓成果颇丰,大方向上博世跟上了前沿的脚步并开始打造自己的特色。本文精选了博世汽车业务近期的优秀工作,为大家一窥其最新的研究图景。
PS. 推荐阅读
D GS(NeurIPS 2025)
论文标题:D GS: Dense Depth Regularization for LiDAR-free Urban Scene Reconstruction
论文链接:https://arxiv.org/abs/2510.25173
提出机构:武汉大学, 上海交通大学, 同济大学, 博世, 南洋理工大学
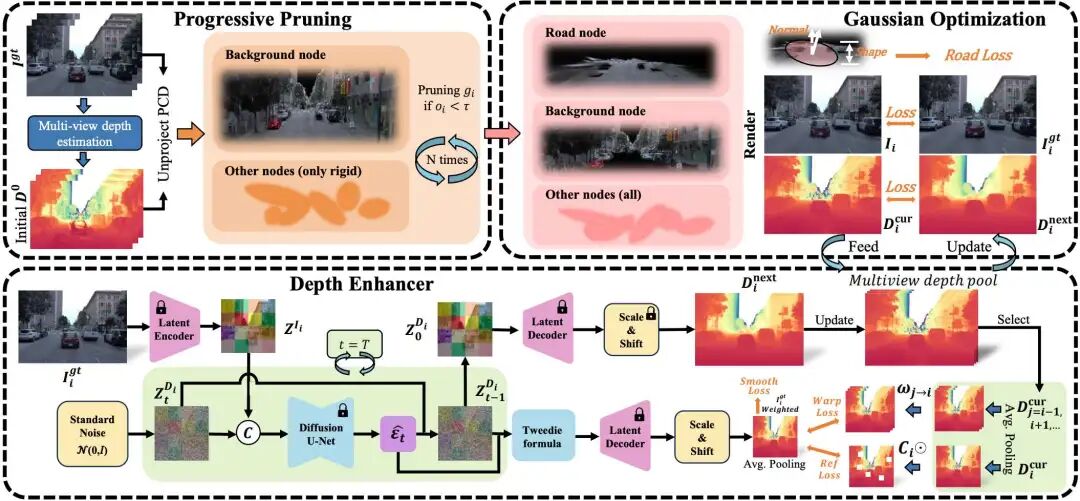
一句话总结:D²GS是一种仅依赖相机输入的动态城市街景重建框架,通过多视角深度估计初始化、渐进式剪枝策略、扩散增强的深度优化模块以及道路几何强先验建模,在无需LiDAR的情况下实现了与LiDAR监督方法相媲美甚至更优的几何重建与深度估计质量。
核心贡献:
提出了一种完全LiDAR-free的动态城市街景重建流水线,避免了实际应用中LiDAR与相机之间的标定误差、时空不同步和数据稀疏性问题,显著降低了数据采集与系统部署的复杂度与成本。
设计了渐进式剪枝策略,从密集的多视角深度点云中高效筛选出具有全局几何一致性的高斯点集,实现了从冗余初始化到紧凑、高质量几何表示的平稳过渡,兼顾了计算效率与重建精度。
创新性地引入了基于扩散先验的深度增强模块,通过参考损失、多视角扭曲损失与平滑损失的联合优化,迭代地利用当前高斯几何引导深度扩散过程,生成密集、准确且多视角一致的度量深度图,为高斯训练提供了强有力的几何监督。
在场景图表示中集成了专用道路节点,通过对高斯的位置、法向和平坦性施加强几何约束,显式建模地平面先验,显著提升了道路区域的几何重建与深度估计精度。
在Waymo Dynamic32数据集上的大量实验表明,D²GS在图像重建(PSNR/SSIM/LPIPS)和深度估计(L1/RMSE/Abs Rel)指标上均超越现有LiDAR监督及LiDAR-free方法,验证了其有效性与先进性。
FlowDrive
论文标题:FlowDrive: Energy Flow Field for End-to-End Autonomous Driving
论文链接:https://arxiv.org/abs/2509.14303
项目主页:https://astrixdrive.github.io/FlowDrive.github.io/
提出机构:上海交通大学,博世,清华大学(AIR),上海大学
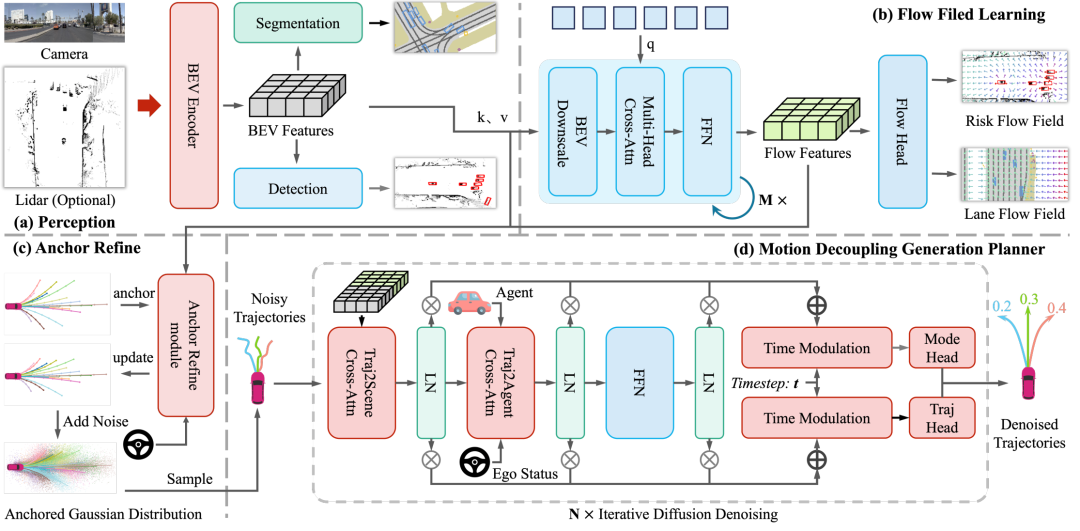
一句话总结:针对现有端到端自动驾驶规划方法在BEV特征中缺乏显式、可解释的安全与语义先验建模,以及运动意图预测与轨迹生成任务耦合导致的梯度冲突问题,FlowDrive 提出了一种融合能量流场表示、流感知锚点细化与任务解耦扩散规划的创新框架,通过物理可解释的流场显式编码风险与车道先验,实现更安全、可解释且符合交规的轨迹生成。
核心贡献:
提出了基于能量的流场表示法,在BEV空间中显式建模风险势能场与车道吸引场,将几何约束与规则语义编码为连续的空间能量分布,为规划提供结构化、可解释的安全与引导先验。
设计了流感知锚点细化模块,利用流场梯度动态调整初始轨迹锚点,使其与能量最低(即最安全、最符合车道引导)的区域对齐,从而提升轨迹初始化的空间合理性与意图一致性。
提出了任务解耦的运动生成规划器,通过特征级门控机制将高层运动意图预测与底层轨迹去噪生成分离,缓解了多任务学习的梯度干扰,并利用条件扩散模型生成多样且目标一致的轨迹分布。
在NAVSIM v2基准测试上取得了最先进的性能(EPDMS: 86.3),在安全性、轨迹质量、交通规则遵守等多个指标上超越现有基线,验证了流场引导与任务解耦设计对提升自动驾驶规划安全性、可解释性与鲁棒性的有效性。
AnchDrive
论文标题:AnchDrive: Bootstrapping Diffusion Policies with Hybrid Trajectory Anchors for End-to-End Driving
论文链接:https://arxiv.org/abs/2509.20253
提出机构:上海大学、博世、上海交通大学、西交利物浦大学
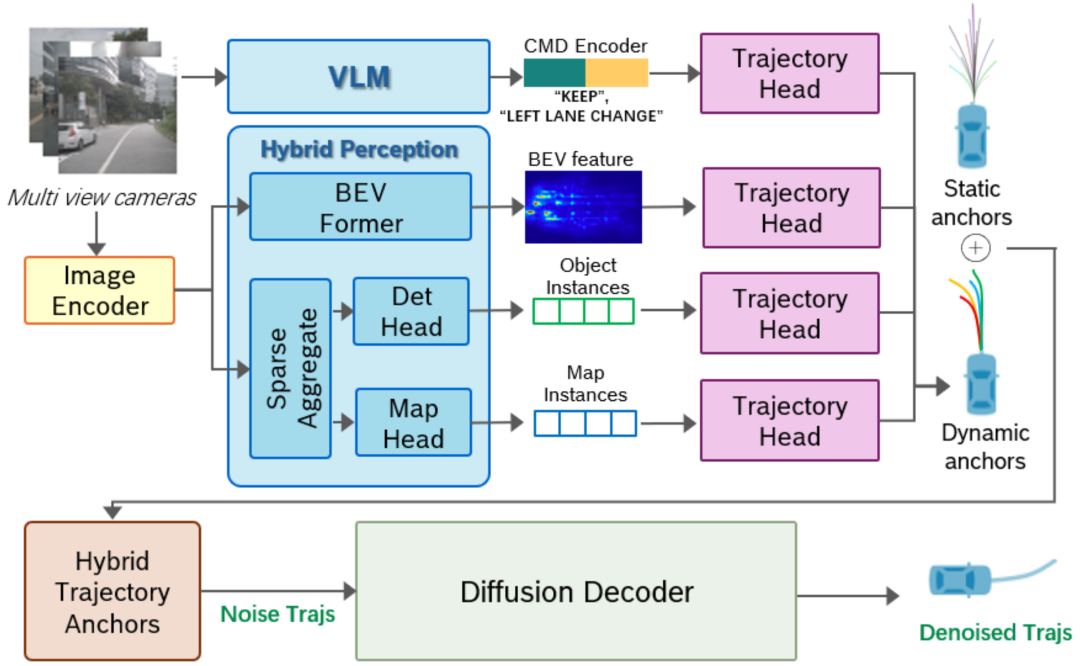
一句话总结:AnchDrive提出一种基于混合轨迹锚点初始化的截断扩散策略,通过动态生成与静态先验相结合的锚点集合,显著提升了扩散模型在端到端自动驾驶轨迹生成中的效率与性能,实现了在少量去噪步骤下生成高质量、多样化的安全轨迹。
核心贡献:
提出混合轨迹锚点机制,首次将动态锚点(由实时感知特征生成)与静态锚点(从大规模人类驾驶数据中预采样)融合,为扩散过程提供高质量初始化,既保留场景适应性,又具备跨场景泛化能力。
设计双分支感知架构,结合密集BEV特征与稀疏实例级特征(如障碍物、车道线等),为规划模块提供兼具全局语境与局部结构信息的丰富表征,增强了对复杂交通场景的理解能力。
引入锚点引导的截断扩散策略,将扩散过程从纯噪声初始化改为从锚点开始,大幅减少去噪步数(仅需2步),在保持生成质量的同时显著降低推理延迟,满足实时规划需求。
在NAVSIM v2闭环仿真基准上取得SOTA性能(EPDMS: 85.5),显著超越基于固定轨迹词表的方法(如VADv2、Hydra-MDP)及其他扩散基线(如DiffusionDrive),验证了方法在多样化、长尾场景下的鲁棒性与泛化能力。
DiffSemanticFusion
论文标题:DiffSemanticFusion: Semantic Raster BEV Fusion for Autonomous Driving via Online HD Map Diffusion
论文链接:https://arxiv.org/abs/2508.01778
项目主页:https://github.com/SunZhigang7/DiffSemanticFusion
提出机构:博世、上海大学、上海交通大学、清华大学AIR等
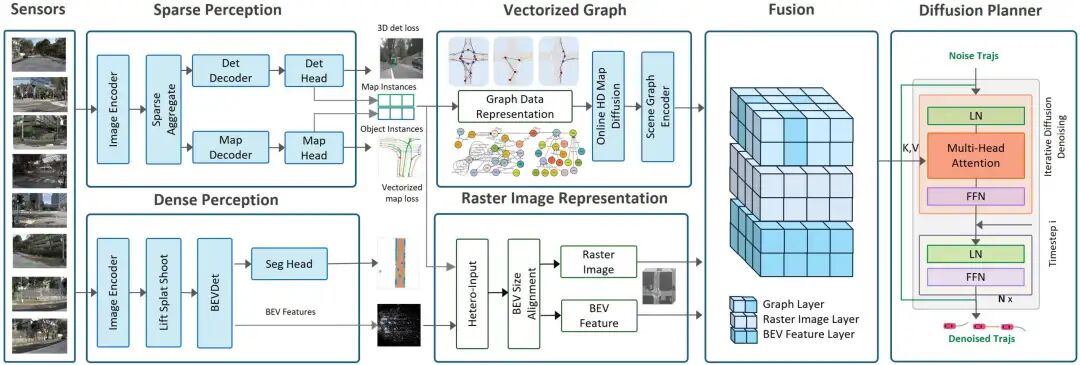
一句话总结:针对在线高精地图在噪声、不完整场景下的不稳定问题,提出DiffSemanticFusion框架,通过地图扩散模块增强地图表达的稳定性与语义丰富性,并结合栅格、图结构与BEV特征的多模态融合,显著提升轨迹预测与规划任务的鲁棒性与性能。
核心贡献:
在线HD地图扩散模块:首次在轨迹预测与规划任务中引入地图扩散机制,通过可学习的去噪过程提升在线地图在噪声、缺失情况下的可靠性与一致性,增强下游任务的鲁棒性。
语义栅格BEV融合架构:设计了一种统一的BEV空间融合方法,有效整合栅格图像、图结构表示与密集BEV特征,充分发挥各模态在几何结构、语义关系与空间连续性方面的互补优势。
多任务SOTA性能验证:在nuScenes轨迹预测任务中,将QCNet性能提升5.1%;在NAVSIM端到端自动驾驶规划任务中,尤其在NavHard复杂场景下取得15%的性能提升,展现了方法的强泛化能力与场景适应性。
模块兼容性与可扩展性:地图扩散模块与多种矢量式方法(如VectorNet、QCNet)兼容,可灵活集成于现有预测与规划流程,具备良好的工程落地潜力。
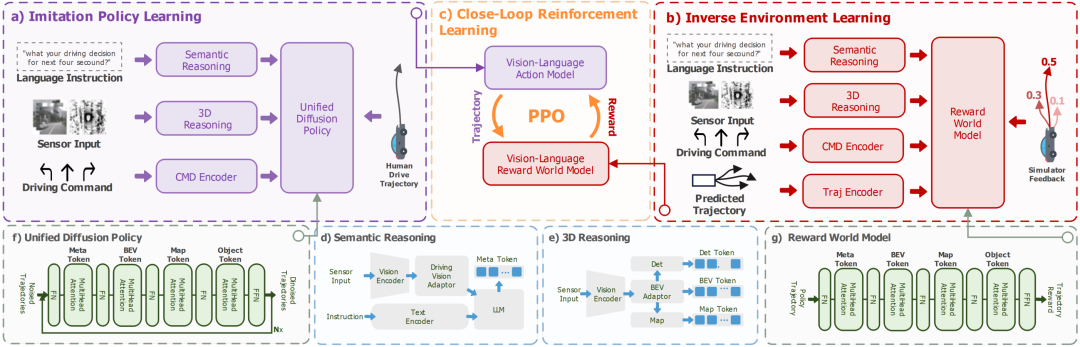
IRL-VLA
论文标题:IRL-VLA: Training an Vision-Language-Action Policy via Reward World Model
论文链接:https://arxiv.org/abs/2508.06571
项目主页:https://github.com/IRL-VLA/IRL-VLA
提出机构:博世、上海大学、上海交通大学、清华大学等
一句话总结:针对当前视觉-语言-动作模型在自动驾驶中存在的开环模仿学习性能受限、闭环训练依赖高仿真模拟器且计算效率低两大挑战,IRL-VLA提出一种基于奖励世界模型的闭环强化学习框架,通过三阶段训练(模仿预训练→逆环境学习奖励模型→奖励引导的强化学习微调),在不依赖高保真仿真的情况下实现安全、舒适与效率均衡的端到端驾驶策略优化,在NAVSIM v2基准上取得领先性能。
核心贡献:
提出IRL-VLA框架,首次实现了不依赖仿真器的、基于传感器输入的闭环VLA强化学习,通过逆强化学习构建轻量级奖励世界模型,替代传统高计算成本的仿真器奖励计算,实现了可扩展、高效的闭环训练。
设计了分层推理的VLA模型架构,融合语义推理、三维几何推理与扩散规划器,在模仿学习阶段即表现出优秀的性能基础,为后续强化学习微调奠定坚实基础。
构建了基于EPDMS的奖励世界模型,利用多目标驾驶指标(如无责碰撞、可行驶区域合规、交通灯合规、舒适度等)进行逆强化学习,实现了对驾驶行为多维度、细粒度的奖励建模。
在NAVSIM v2端到端驾驶基准上取得先进性能,EPDMS得分达74.9,在CVPR2025自动驾驶大奖赛中获得亚军,验证了框架在安全、舒适和效率方面的综合优势,为闭环自动驾驶VLA研究提供了新范式。
SparseMeXT(IROS 2025)
论文标题:SparseMeXT Unlocking the Potential of Sparse Representations for HD Map Construction
论文链接:https://arxiv.org/abs/2505.08808
提出机构:博世、上海大学、清华大学AIR、西交利物浦大学
一句话总结:本文系统性地重新设计并优化了基于稀疏表示的在线高精地图构建方法SparseMeXT,首次在nuScenes数据集上使稀疏方法的精度和效率全面超越现有密集BEV方法,实现了稀疏表示在HD地图构建任务中的突破性进展。
核心贡献:
针对地图任务优化的稀疏网络架构:提出专门为地图特征提取设计的网络结构,通过优化特征聚合与表示学习,解决现有基于3D检测的稀疏架构在地图任务中覆盖范围大、空间一致性要求高的不适应问题,显著提升了特征提取效率与表达能力。
稀疏-密集辅助分割监督机制:设计了一种基于查询的稀疏-密集实例到分割辅助任务,弥补了稀疏范式中缺少显式BEV特征网格的不足,使模型能够有效利用全局语义与几何信息,增强了地图重建的完整性与准确性。
基于物理先验的查询去噪策略(PPDN):针对地图元素的曲线结构特点,设计了包含旋转、平移、缩放和曲率调整四种物理噪声模式的去噪训练模块,通过引入符合真实几何约束的噪声扰动,显著提升了模型训练的稳定性与预测鲁棒性。
全面的性能优势验证:在nuScenes数据集上,SparseMeXT系列模型在保持高效率(最高32.9 FPS)的同时,mAP显著领先于现有稀疏与密集方法,其中SparseMeXT-Large达到68.9% mAP,长距离感知(90m范围)任务上亦大幅领先,证明了稀疏方法在高精地图构建中的强大竞争力与实用潜力。
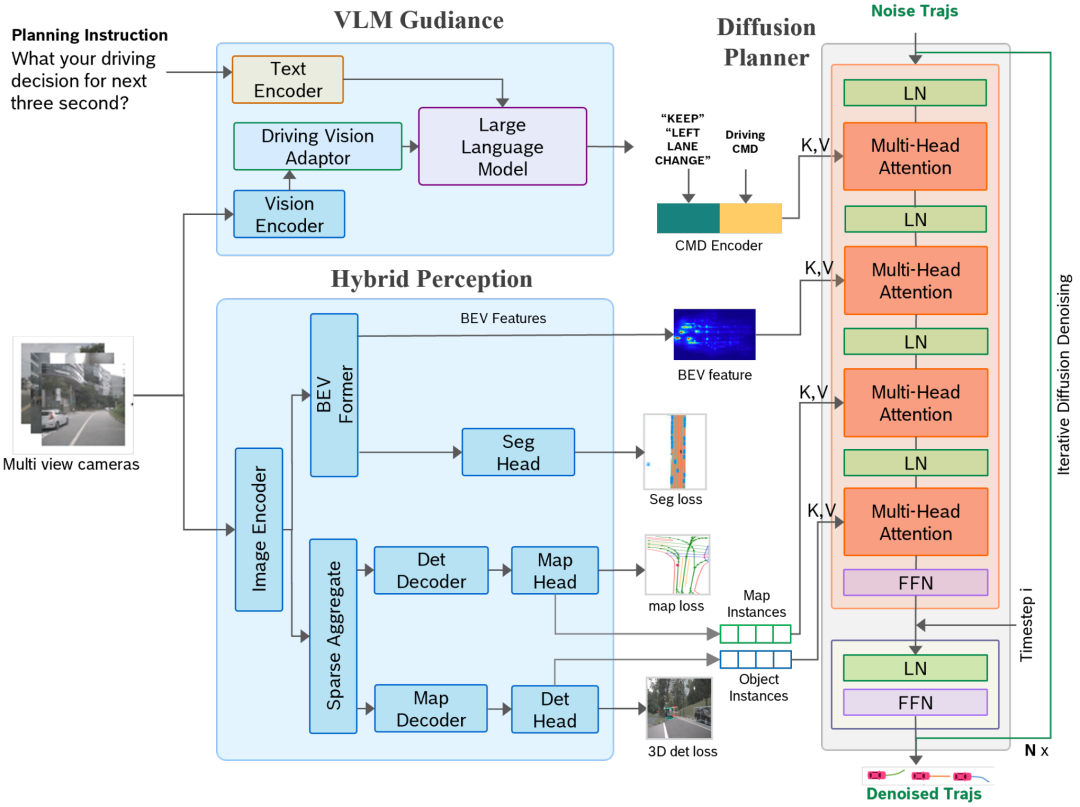
Impromptu VLA
论文标题:Impromptu VLA: Open Weights and Open Data for Driving Vision-Language-Action Models
论文链接:https://arxiv.org/abs/2505.23757
项目主页:http://impromptu-vla.c7w.tech/
提出机构:清华大学 AIR,博世
一句话总结:为解决自动驾驶模型在“长尾”非结构化道路场景(如模糊路界、临时交通规则、非常规障碍物等)中性能不足的问题,本研究提出并构建了大规模、高质量、多任务标注的Impromptu VLA 数据集,该数据集从超 200 万原始片段中精选约 8 万段,并系统定义了四类非结构化场景分类体系;实验表明,基于该数据集训练的 VLA 模型在闭环安全评估与开环轨迹预测任务上均取得显著性能提升,同时其规划导向的问答体系可作为诊断工具,精准评估模型在感知、预测与规划等维度的能力演进。
核心贡献:
Impromptu VLA 数据集:首个大规模、公开可访问、专注于多样化非结构化驾驶场景的数据集,包含约 8 万段视频片段,覆盖“边界不清道路”“临时交通规则变化”“非常规动态障碍物”“恶劣道路条件”四大挑战类别,并提供了丰富的多任务问答注释及动作轨迹,有效填补了现有自动驾驶数据在非结构化场景上的空白。
系统化非结构化场景分类学与自动化数据构建流水线:提出了一套数据驱动的非结构化道路场景分类体系,并设计了一个以视觉语言模型(VLM)为核心的自动化数据筛选、分类与标注流程,结合链式思维(CoT)推理与人工验证,实现了高质量、可扩展的多任务标注生成。
全面的实验验证与诊断能力证明:通过闭环(NeuroNCAP)与开环(nuScenes 轨迹预测)基准测试,实证了使用 Impromptu VLA 数据集训练的 VLA 模型在安全评分、碰撞率及轨迹精度上均有显著提升;同时,数据集自带的规划导向问答验证集被证明是一个有效的诊断工具,能够清晰量化模型在感知、预测与规划等关键能力上的进步。

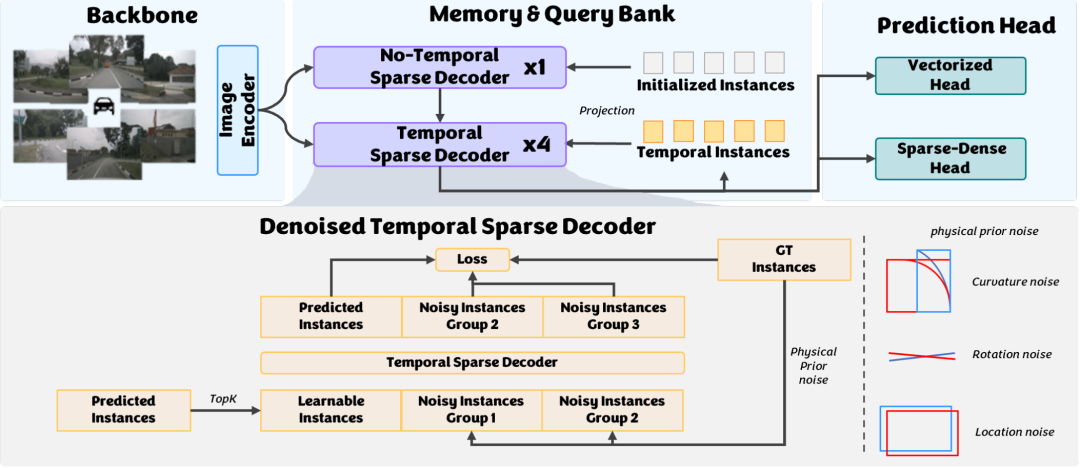
DiffVLA
论文标题:DiffVLA: Vision-Language Guided Diffusion Planning for Autonomous Driving
论文链接:https://arxiv.org/abs/2505.19381
提出机构:博世(RIX),清华大学(AIR),上海大学,上海交通大学,东南大学
一句话总结:本文提出DiffVLA,一种面向自动驾驶的视觉-语言引导扩散规划框架,通过结合视觉语言模型的语义引导、混合稀疏-稠密感知以及高效的扩散轨迹生成,在复杂闭环场景中实现安全、多样且拟人的驾驶行为生成,显著提升端到端自动驾驶系统的决策鲁棒性与泛化性能。
核心贡献:
提出一种新颖的混合稀疏-稠密扩散策略,将稠密BEV特征与稀疏实例级感知(如障碍物、车道线)相结合,增强对动态场景的结构化理解与碰撞规避能力。
引入VLM命令引导模块,基于Senna-VLM架构实现多视角图像与导航指令的融合理解,输出高层驾驶决策(横向/纵向控制),为扩散规划提供语义层面的行为引导。
设计基于轨迹词汇的离散化扩散规划器,通过构建轨迹词汇表并结合截断扩散策略与层次化信息编码,实现高效、多模态的轨迹生成与优化。
在NAVSIM v2闭环评测基准上取得领先性能,综合指标EPDMS达到45.0,并在碰撞率、可行驶区域合规性、交通信号遵守等多个子任务上表现优异,验证了框架在真实与合成复杂场景中的有效性与鲁棒性。
提出两阶段训练策略,分阶段优化VLM、稀疏感知、稠密感知与规划模块,并在训练中冻结部分模块以提升稳定性和收敛效率,为大规模端到端自动驾驶系统训练提供了可行方案。
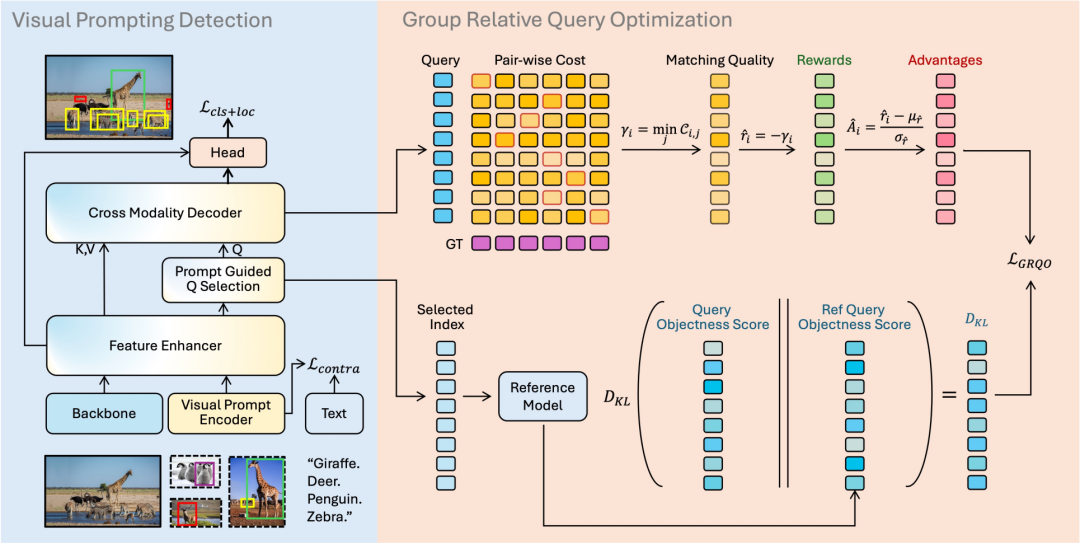
DINO-R1
论文标题:DINO-R1: Incentivizing Reasoning Capability in Vision Foundation Models
论文链接:https://arxiv.org/abs/2505.24025
项目主页:https://christinepan881.github.io/DINO-R1
提出机构:博世北美研究中心,博世人工智能中心,得克萨斯农工大学
一句话总结:受语言模型中强化学习推动推理能力进步的启发,本研究首次将类似思想引入视觉基础模型,提出Group Relative Query Optimization训练策略,通过查询级相对奖励与KL正则化,显著提升了视觉提示检测中的泛化与推理能力,为视觉模型的“思考式”训练开辟了新路径。
核心贡献:
提出Group Relative Query Optimization,首个面向视觉提示检测的强化式训练范式,通过组内查询的相对奖励机制,实现对高方差视觉样例的鲁棒对齐与泛化。
设计了查询级相对奖励模块与KL散度正则化策略,前者通过组归一化优势信号增强查询表达与监督密度,后者通过约束目标分布稳定性防止训练漂移与灾难性遗忘。
构建了VIS-G-DINO视觉提示检测框架及其强化训练版本DINO-R1,实现了从文本提示到视觉提示的无缝扩展,并在训练中融入了视觉引导的查询选择机制。
在COCO、LVIS和ODinW等多个数据集上系统验证了DINO-R1的优越性,其在零样本与微调设置下均显著优于传统监督微调基线,展现出更强的跨域泛化与视觉上下文推理能力。
自动驾驶之心
知识星球交流社区


















 1491
1491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









