



作者 | 量子位
原文链接:https://mp.weixin.qq.com/s/x0X481MgH_8ujjB0_XL4SQ
点击下方卡片,关注“大模型之心Tech”公众号
>>点击进入→大模型没那么大Tech技术交流群
本文只做学术分享,如有侵权,联系删文,自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
DeepSeek V3.1和V3相比,到底有什么不同?
官方说的模模糊糊,就提到了上下文长度拓展至128K和支持多种张量格式,但别急,我们已经上手实测,为你奉上更多新鲜信息。
我们比较了V3.1和V3,注意到它在编程表现、创意写作、翻译水平、回答语气等方面都出现了不同程度的变化。
不过要说最明显的更新,大概是DeepSeek网页端界面的【深度思考(R1)】悄悄变成了【深度思考】。
手机端还在慢慢对齐(笑)
当前DeepSeek V3.1 Base可在抱抱脸上下载,也可通过网页、APP和小程序使用完整版本。
开学考试现在开始
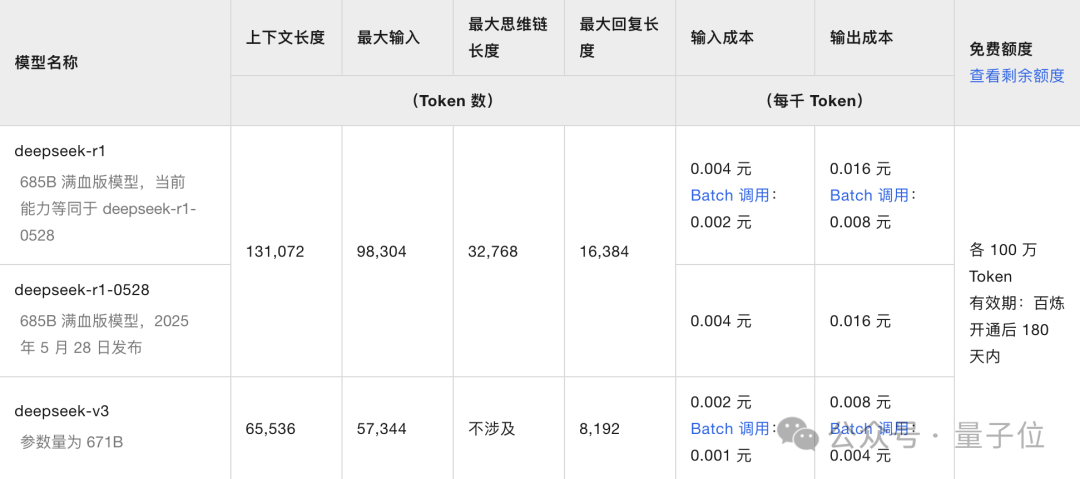
鉴于现在网页端已全部替换成了V3.1,我们通过阿里云调用了DeepSeek V3的API(最大上下文长度还是65K)作为对比。
马上就是开学季,我们给二个版本的模型出了一套“试卷”,从以下五个“学科”进行测试:
计算机:编程能力
语文:情境写作
数学:理解应用
外语:翻译水平
拓展:冷门知识
让我们一起看看它们表现如何~

编程能力
在更新前,我曾向DeepSeek V3问过这样的问题:
帮我用python写一段代码,把输入的gif图压缩到10M以下。
它的回答如下(图片可上下滑动)。

更新后,问V3.1同样的问题,则得到了这样的结果:

很直观地就能感受到,相比起V3,V3.1要更加全面,考虑到了更多的可能性(比如使用更激进的压缩策略,以及检查原文件是否是GIF格式)。
还“手把手”地给出了这段代码的使用说明,需要提前安装必要的依赖库,怎么使用命令行……甚至还有工作原理。
没有优化建议,大概是因为它觉得已经足够了吧(?)
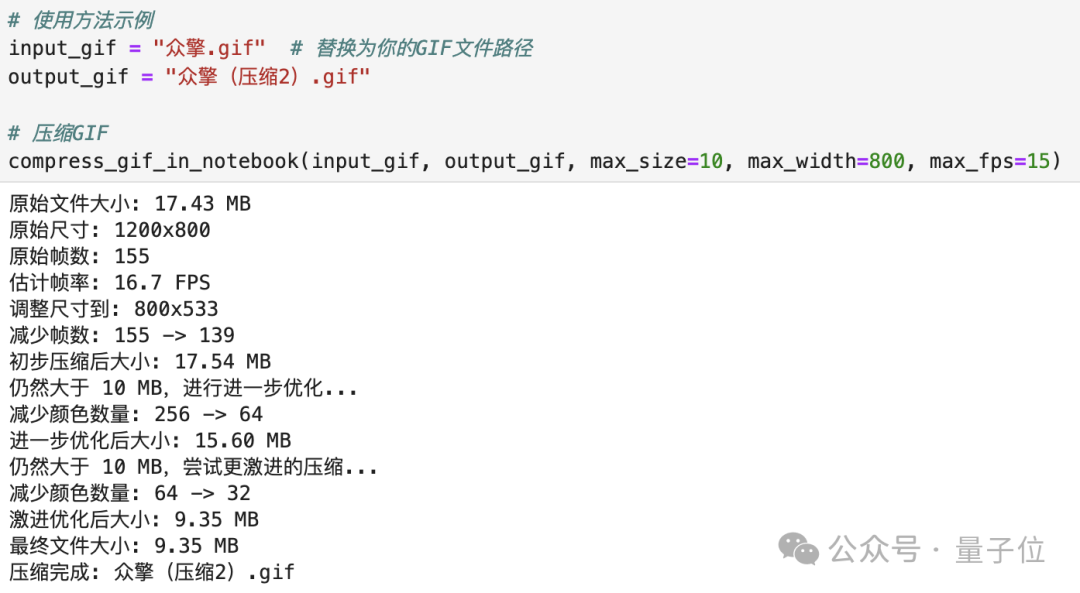
拿之前在世界机器人大会上拍摄的众擎机器人作为示例,原文件大小为18.3MB,用V3给出的代码,压缩后依然大于10MB,如果要满足条件的话还需要再压缩一次。


而V3.1给出的结果则直接“一步到位”(代码针对Jupyter环境进行了一点小调整,逻辑不变),并输出了处理步骤:
最后的两张GIF图如下(上为V3,下为V3.1):


可以看到上图的速度比下图要快一些。
情境写作
我们选择了今年上海卷高考作文的题目:
有学者用“专”“转”“传”概括当下三类文章:“专”指专业文章;“转”指被转发的通俗文章;“传”指获得广泛传播的佳作,甚至是传世文章。他提出,专业文章可以变成被转发的通俗文章,而面对大量“转”文,读者又不免期待可传世的文章。由“专”到“传”,必定要经过“转”吗?请联系社会生活,写一篇文章,谈谈你的认识与思考。要求:(1)自拟题目;(2)不少于800字。
输出结果如下,可左右滑动对比,左边为V3,右边为V3.1:


两个版本在文字风格上具有很大的不同,从V3理性(人机味)的平铺直叙,到V3.1文艺(情绪化)的诗意表达,看起来像理科生和文科生的区别。
如果你是主考官,会更喜欢哪一篇呢?
理解应用
考验模型的数学能力,光问“9.11和9.8哪个大”这种对于实际用户没什么帮助的题目还是有点不够看。
高考数学题按理来讲应该是能做对的吧?
以下是今年数学全国一卷的第3题,考的是双曲线。
若双曲线C的虚轴长为实轴长的√7倍,则C的离心率为?
答案是2√2,两个版本的模型都得到了正确结果,但在呈现上有所不同。


翻译水平
我们向V3和V3.1输入了同一篇生物学论文的摘要(含专有名词),并要求它们将其翻译成中文。
摘要选自Nature最新研究:《独特毛颚动物体型的基因组起源》。
两个版本模型的输出结果如下:


可以看出,相比起V3喜欢用括号来补充说明,V3.1对长难句的理解程度更高;但V3.1出现了没有翻译出several这种简单词的情况。
冷门知识
结合同事的专业和最近在小红书上刷到的内容,我们问了一个比较“偏门”的问题:
构树的单个果实(不是由花序组成的聚花果)是核果还是瘦果?
这个问题的答案在不同教材上存在分歧,V3和V3.1分别给出了以下回答,均认为其属于核果:


神奇的是V3.1依然存在使用conclusion替代“结论”这样的表述,以及对于“为什么会想到瘦果”这个问题的回答偏题到该果实属于聚花果的方向了。
顺便一提,小红书的博主通过解剖实验,认为其属于瘦果。
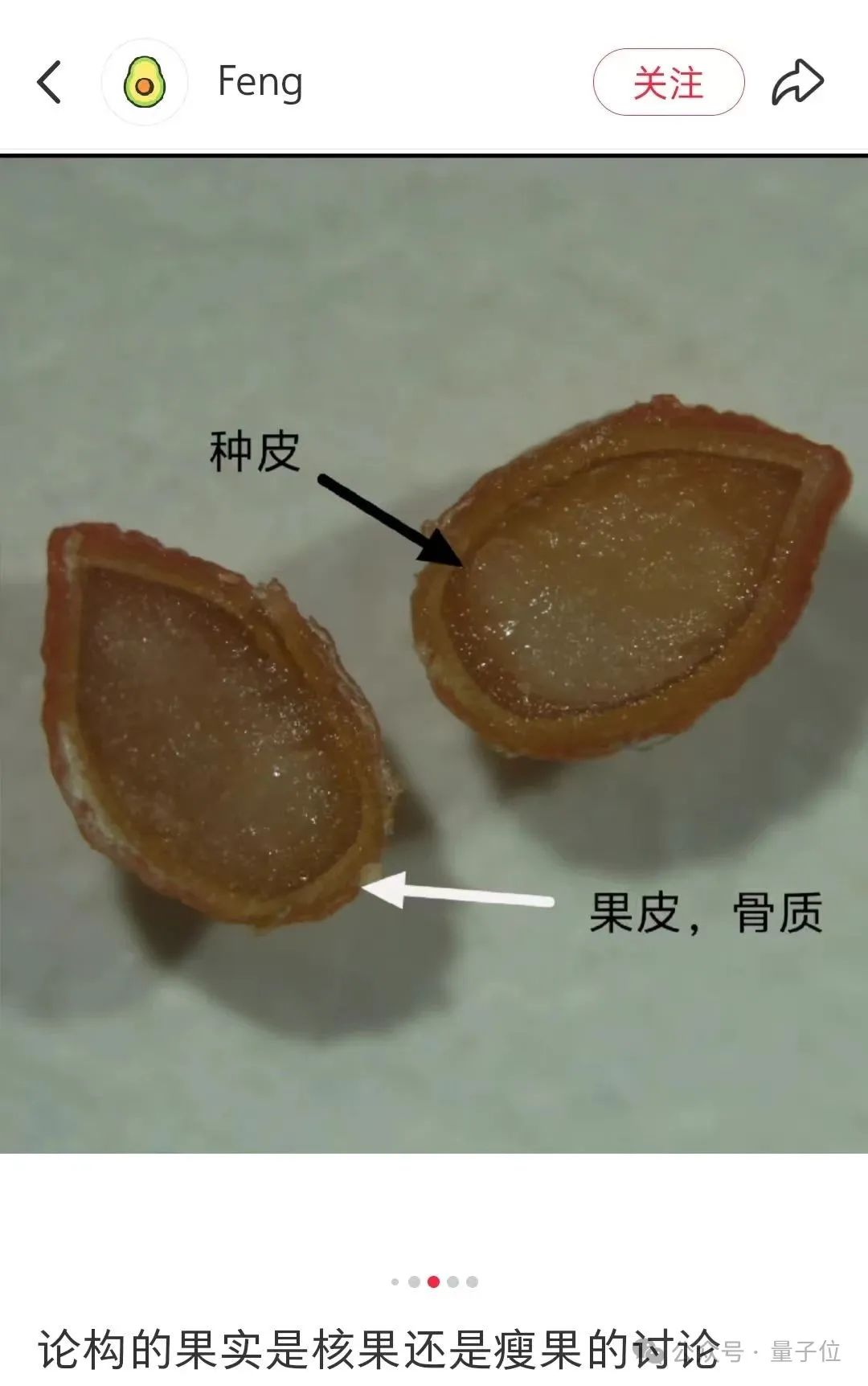
对这个结论感兴趣的朋友可以去小红书上搜索一下。
非推理模型SOTA
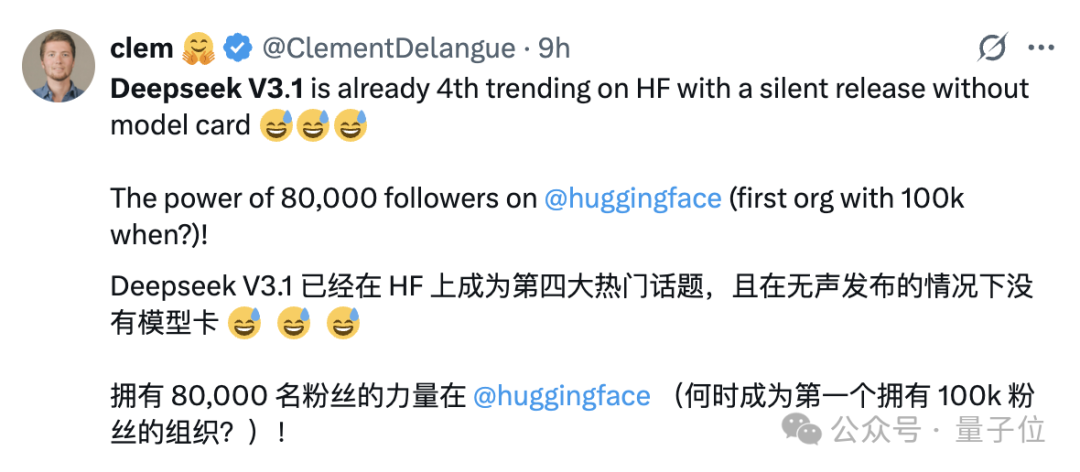
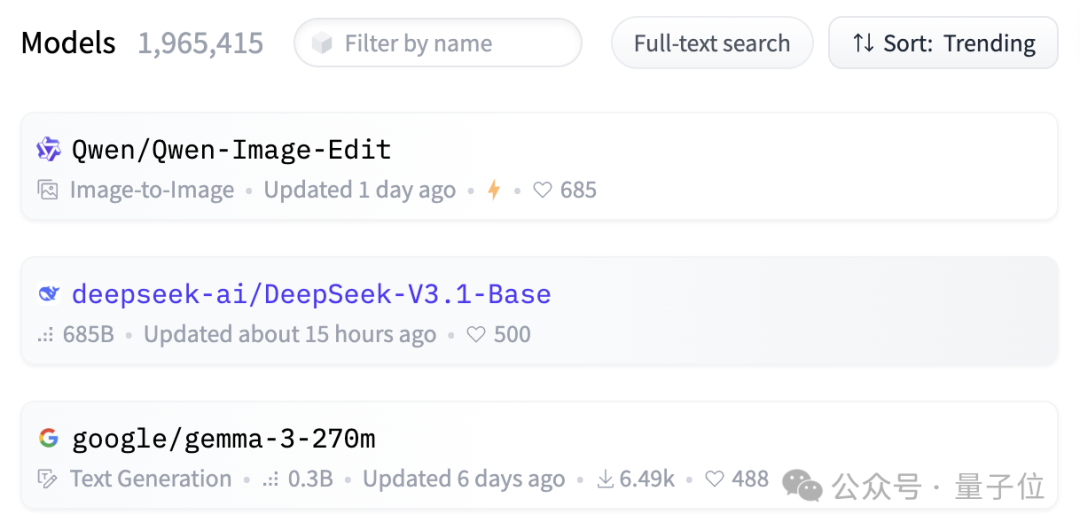
网友们对这次更新颇为关心,即使还未发布模型卡,就在抱抱脸上成为了第四的热门话题。
截至发稿已荣登第二。
网友们也在使用后得到了一些有趣的发现。
Reddit就有人测试,DeepSeek V3.1在aider上得分71.6%,拿下了非推理模型的SOTA。

这是什么概念——有网友解释到,这意味着它比Claude Opus 4得分多1%,但价格便宜68倍。

也有人在SVGBench基准上发现:V3.1的表现>V3.1(思考)>R1 0528。
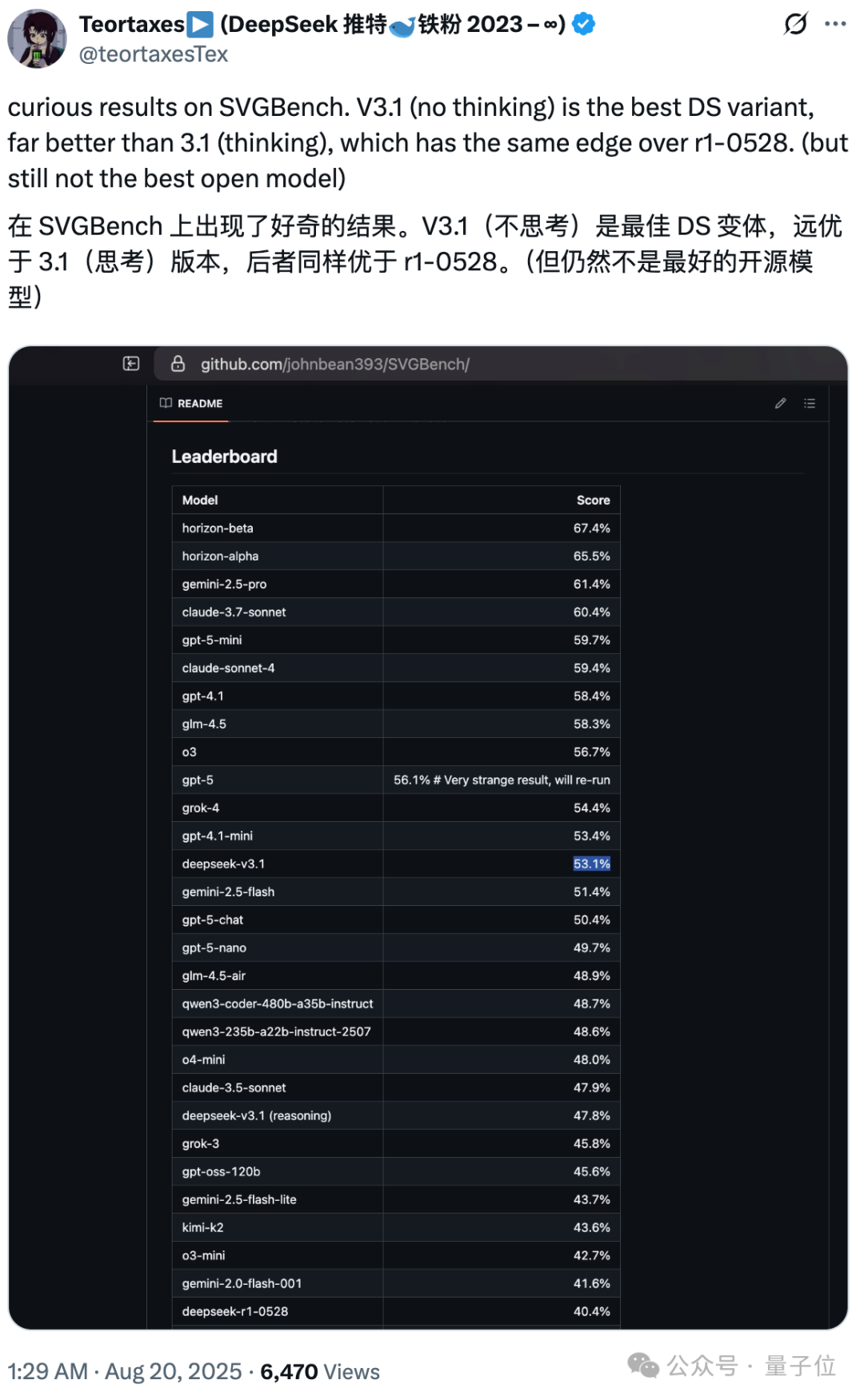
这可能和V3.1的配置有关?
有网友察觉到它增加了四个特殊的token,并注意到现版本的V3.1在关闭搜索状态下也会自动搜索。

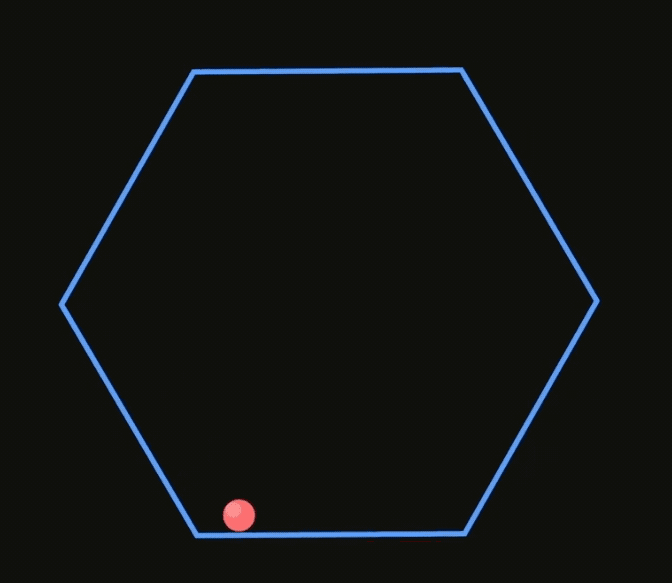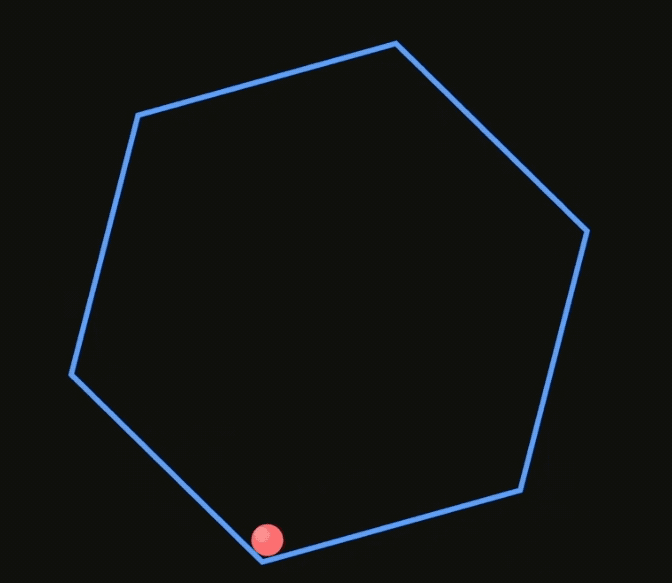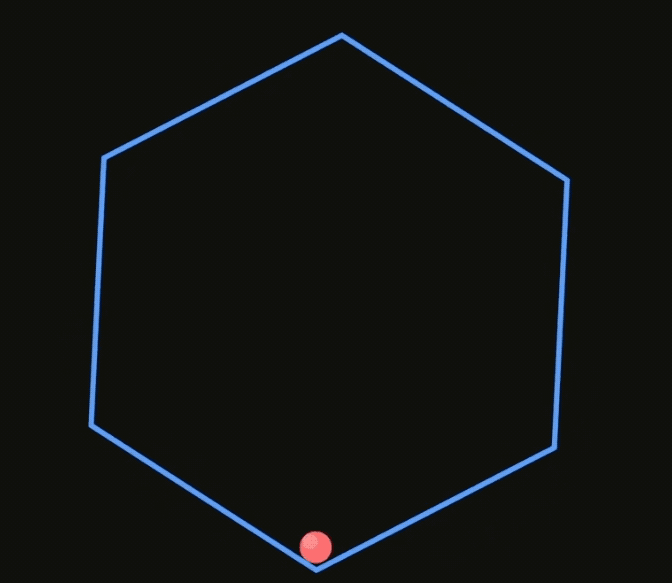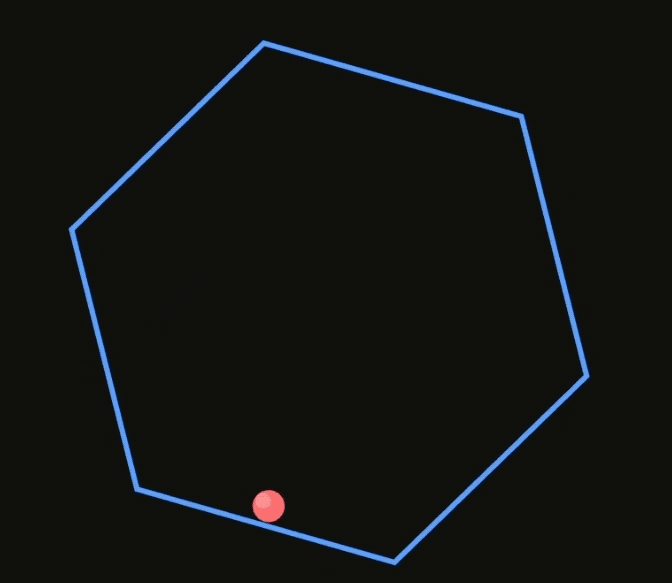
此外,它的物理理解能力似乎有所提升,下面两个GIF图分别是V3.1和V3对于”在旋转六边形内弹跳的球“的呈现。

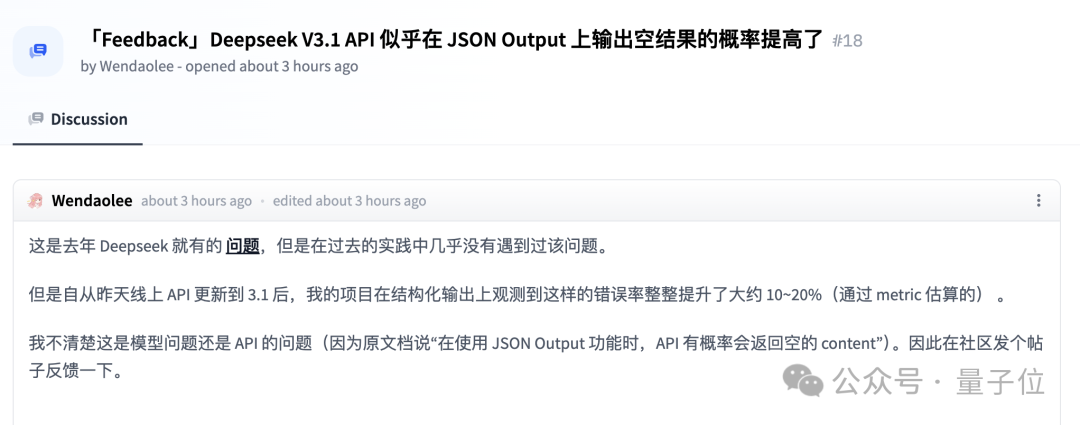
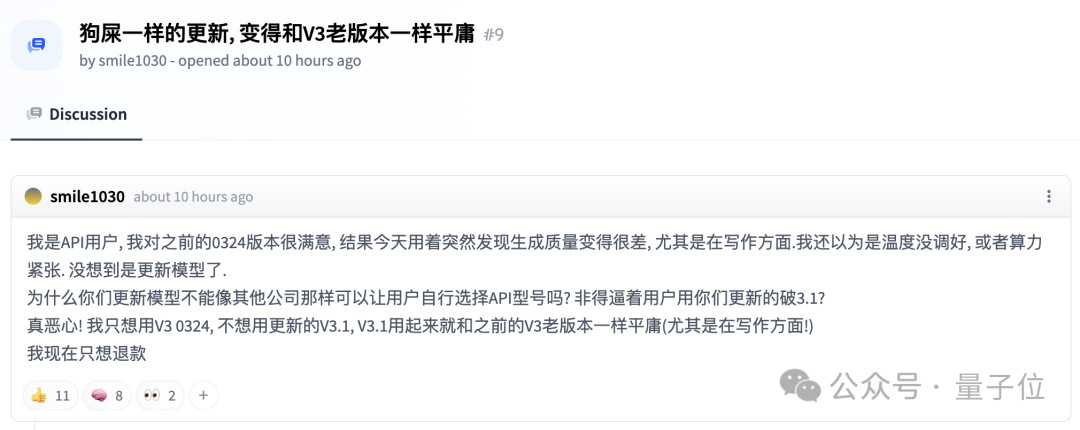
但也有人发现了一些问题,多与线上API相关……嗯,已经有人开骂了。
不过,最让人好奇的是,V3.1发布了,R2呢?
参考链接:
[1]https://x.com/deepsseek/status/1957886077047566613
[2]https://huggingface.co/deepseek-ai/DeepSeek-V3.1-Base
[3]https://venturebeat.com/ai/deepseek-v3-1-just-dropped-and-it-might-be-the-most-powerful-open-ai-yet/
[4]https://old.reddit.com/r/LocalLLaMA/comments/1muq72y/deepseek_v31_scores_716_on_aider_nonreasoning_sota/
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
大模型之心Tech知识星球交流社区
我们创建了一个全新的学习社区 —— “大模型之心Tech”知识星球,希望能够帮你把复杂的东西拆开,揉碎,整合,帮你快速打通从0到1的技术路径。
星球内容包含:每日大模型相关论文/技术报告更新、分类汇总(开源repo、大模型预训练、后训练、知识蒸馏、量化、推理模型、MoE、强化学习、RAG、提示工程等多个版块)、科研/办公助手、AI创作工具/产品测评、升学&求职&岗位推荐,等等。
星球成员平均每天花费不到0.3元,加入后3天内不满意可随时退款,欢迎扫码加入一起学习一起卷!


















 1726
1726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









