



作者 | Sakura 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/716867464
点击下方卡片,关注“自动驾驶之心”公众号

>>自动驾驶前沿信息获取→自动驾驶之心知识星球
本文只做学术分享,如有侵权,联系删文
VisionTrap: Vision-Augmented Trajectory Prediction Guided by Textual Descriptions
来源
ECCV 2024
开源数据集
https://moonseokha.github.io/VisionTrap
moonseokha.github.io/VisionTrap
摘要
预测其他道路代理的未来轨迹是自动驾驶汽车的一项重要任务。已建立的轨迹预测方法主要使用检测和跟踪系统生成的代理轨迹和HD地图作为输入。
在这项工作中,我们提出了一种新方法,该方法还结合了来自环视摄像头的视觉输入,使模型能够利用视觉线索,如人类的凝视和手势、道路状况、车辆转向信号等,这些线索在现有方法中通常对模型隐藏。此外,我们使用视觉语言模型(VLM)生成并由大型语言模型(LLM)细化的文本描述作为训练期间的监督,以指导模型从输入数据中学习特征。尽管使用了这些额外的输入,但我们的方法实现了53毫秒的延迟,使其可用于实时处理,这比之前具有类似性能的单代理预测方法快得多。
我们的实验表明,视觉输入和文本描述都有助于提高轨迹预测性能,我们的定性分析突出了模型如何利用这些额外的输入。最后,在这项工作中,我们创建并发布了nuScenes文本数据集,该数据集为每个场景添加了丰富的文本注释,从而增强了已建立的nuScenes数据集,展示了利用VLM对轨迹预测的积极影响
问题
目前的轨迹预测方法依赖于检测跟踪系统的输出以及 HD 地图,传统方法中模型利用视觉线索,如人类的凝视和手势、道路状况、车辆转向信号等,这些线索在现有方法中并没有很好利用
方法
本文在传统轨迹预测方法的输入基础上引入了环视摄像头的视觉输入,使用视觉语言模型(VLM)生成并由大型语言模型(LLM)细化的文本描述作为训练期间的监督,以指导模型从输入数据中学习什么
Introduction
传统轨迹预测的输入的缺陷——信息不足
传统轨迹预测方法中只使用检测跟踪结果+HD地图,其存在以下缺点
HD高清地图是静态的,只能提供预先定义好的信息,限制了他们对于变化环境的适应性,如施工区域以及天气条件。同时HD地图不能提供理解agent行为的视觉数据
传统的轨迹预测中输入只有HD地图和agent的历史轨迹,这些信息是不足的;周围环境中agent的转向灯、行人的朝向、天气情况等信息都是丢失的;而且HD地图成本很高且是静态的,假设场景中存在施工区域,这都是无法在HD地图中体现的。
而视觉图像中包含了周围环境中绝大多数信息,将图像引入轨迹预测中辅助预测自然可以提高轨迹预测的精度。这一点之前的很多工作也都进行了考虑,并提出了自己的方法。
以往引入视觉的轨迹预测方法的不足——图像处理方式不好 & 仅使用正面图像
有些工作使用了视觉信息,但同时也存在以下问题
现有的利用视觉语义信息的的轨迹预测方法中要么使用agent所在区域的图像,要么整个图像,同时没有显式的指示要提取什么信息。导致这些方法只能关注于最显式的特征,导致了次优;
此外这些方法只使用正面图像,导致充分认识周围的驾驶环境变得具有挑战性。
针对上面提到的两个问题,本文提出了自己的解决方案。首先肯定要引入图像信息参与到轨迹预测中,第一个问题得到了解决;
其次,第二个问题的本质就在于如何更好地利用图像信息,从图像中提取出有效地信息进行轨迹预测。第二个问题实际上是由于图像中的信息是稠密的,模型不知道提取哪些有用的信息
本文针对第二个问题,对每个图像进行文本描述,将每个视觉特征同文本描述对齐,利用文本引导Text-driven作为监督,让模型能够更好地利用丰富的视觉语义信息。
在这个过程中,本文顺势提出了nuScenee-Text数据集,包含了nuScenes数据集中每个场景中每个agent的文本描述的数据集。在创建该数据集的过程中,使用了VLM和LLM进行标注
文章中此处描述
“Automating this annotation process, we utilize both a Vision-Language Model (VLM) and a Large-Language Model (LLM)” (Moon 等, 2024, p. 3)
上述描述中提到,为了自动化标注过程,使用VLM。按照此描述,VLM实际上没有参与到训练和推理过程,只是在数据集的标注过程中应用了VLM
Related work
本文在描述相关工作时并没有介绍到近期一些将LLM同轨迹预测结合起来的工作,有些不足
Method
接下来介绍本文提出方法的具体做法。本文提出的模型中包含四个重要部分,Per-agent State Encoder,Visual Semantic Encoder, Text-driven Guidance Module, Trajectory Decoder
下图为模型的主要结构图
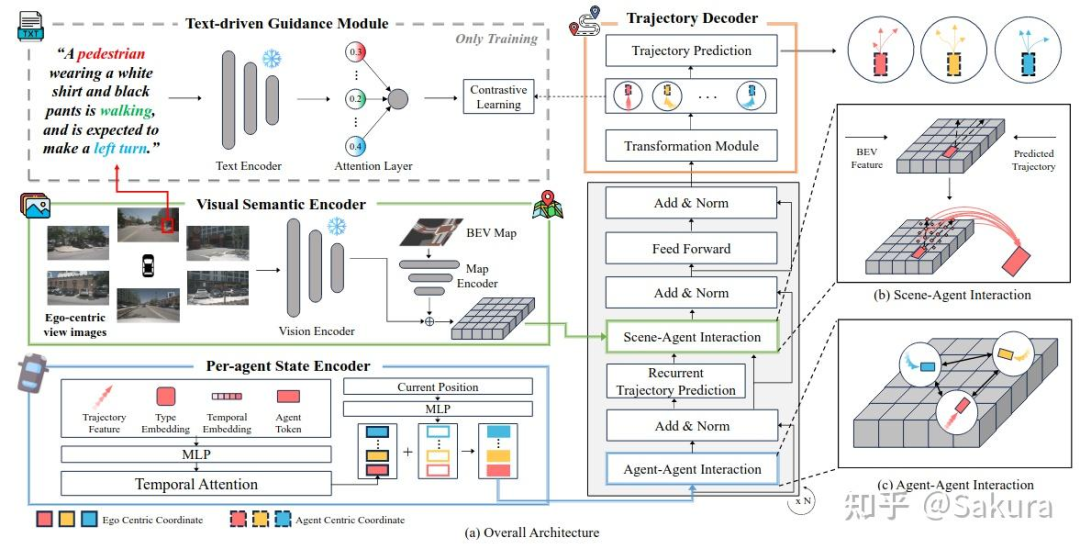
下面详细介绍agent的状态编码器
提取agent时间特征和agent之间的空间交互特征——Per-agent State Encoder
状态编码器的结构如下所示
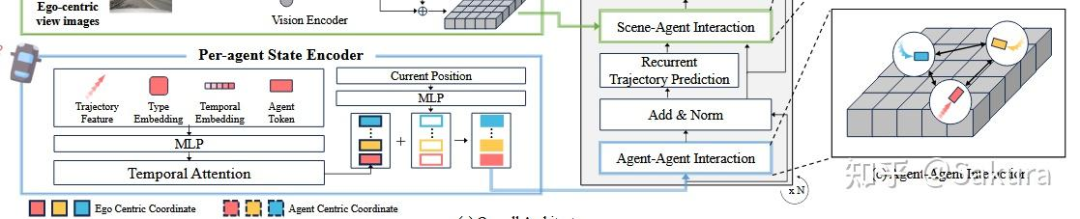
场景中的agent中的坐标均在自车坐标系(以自车位置及方向为坐标轴)下,使用相对位移,agent i的特征通过以下表达式获得
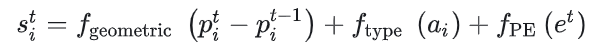
是可学习位置嵌入,用于学习并利用到时间信息的顺序
时间维度自注意力+时间维度可学习token编码时间信息

空间维度自注意力——建模agent之间的空间交互
为了让得到的每个agent的特征中具有spatially aware,将时间特征同位置特征相加,如下所示
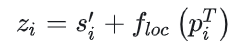
其中 是agent i在自车坐标系下的坐标,并没有使用相对坐标来计算
通过上式得到各个agent的特征,然后在作为query,同当前agent周围的其他agent的特征进行cross attn
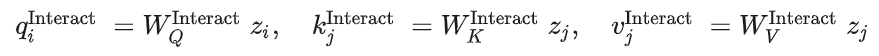
每个agent的状态编码器中使用了常见了空间和时间维度的注意力操作来提取特征,值得一提的是此处在时间维度自注意力操作之后,对最新时间的位置进行编码后叠加到特征上,此处的思想依旧是在What-if一文中说到的”残差连接“的思想。
基于Bev特征和初步预测轨迹,利用Deformable attn实现Scene-Agent交互——Visual Semantic Encoder
视觉语义编码器的主要结构如下
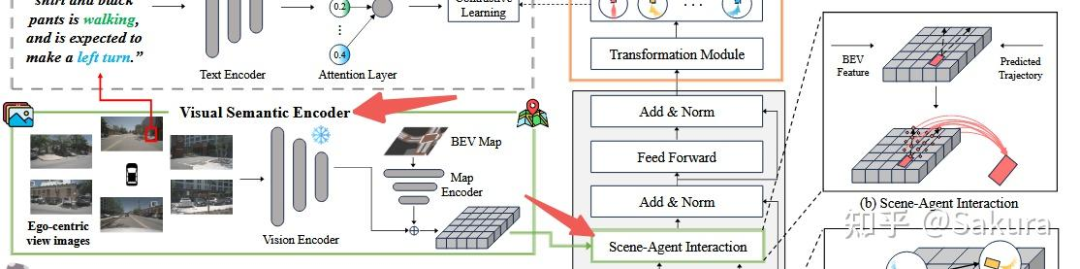
视觉语义编码器的作用就是提取自车周围环境的图像特征。
bev特征的获取——BevDepth+rasterized BEV map

接下来的问题是,如何将代表环境信息的bev特征同上一步得到的agent特征结合,从而让每个agent的特征能够包含环境信息。本文利用deformable attn机制来实现此目标
初步轨迹的获取——Recurrent Trajectory Prediction
agent状态编码器得到的agent特征,通过Recurrent Trajectory Prediciton后得到初步的agent未来轨迹,该未来轨迹用于后续步骤中scene-agent的交互建模中,作为deformable attn的参考点
★备注:此处Recurrent Trajectory Prediciton具体做法笔者尚不清楚,论文中阐述道,此处的解码器结构同Section 3.4中描述的解码器结构相同“utilizes the same architecture as the main trajectory decoder(explained in Sec. 3.4)” (Moon 等, 2024, p. 7)
deformable attn机制实现scene-agent交互
将agent的未来初步轨迹作为deformable attn的参考点,将agent特征同reference point + offset处的bev特征进行交互,将环境信息注入此特征中,计算公式如下
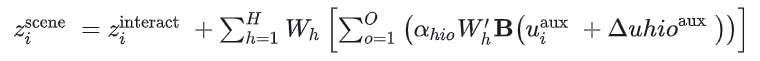
★笔者注:这种方式降低的计算的复杂度,只需要关注初步未来轨迹附近一定范围内的bev 特征,避免了同全局bev特征之间进行注意力计算,是一种可取的思想。同时,笔者也注意到一些工作着力于此处,见后文中的联系一节中
通过多模态对比学习让agent的state embedding关注更加细节的语义细节——Text-driven Guidance Module
通过前文的描述可知,本文希望通过文本描述使模型能够更好地提取来自图像中的特征,从而提高轨迹预测的精度。现在的问题是如何利用文本描述来增强特征学习?
下图为此部分结构图
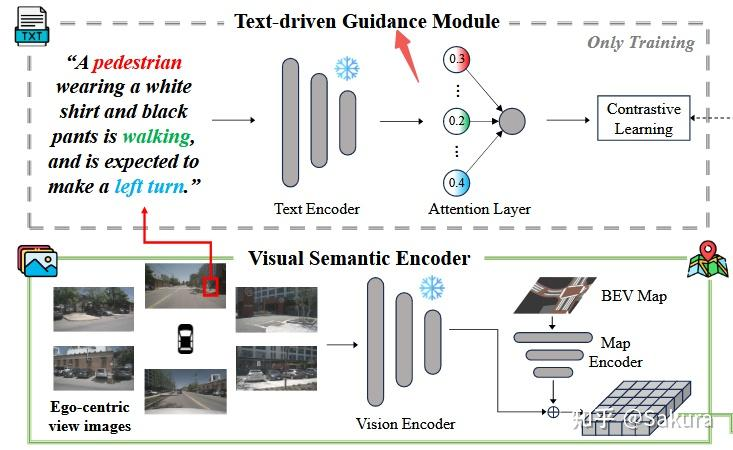
本文利用多模态对比学习,文本描述编码得到的特征 和通过时空间注意力得到的agent特征嵌入并不在一个特征空间中,因此使用对比学习。对比学习的理解可见以下链接
https://blog.youkuaiyun.com/qq_42018521/article/details/128867539
https://blog.youkuaiyun.com/jcfszxc/article/details/135381129
对于来自于同一个agent的文本特征和编码特征,此两个特征的组合称之为正对 。我们希望正对中两个特征的相似度高,追求的训练目标是正对中的特征相似度高。这就相当于通过文本特征引导(guide) 编码特征 捕获到更加丰富的视觉语义特征以区别不同的agent行为。
同时我们还希望负对之间的特征相似度低,负对就是不同agent之间的文本特征和编码特征组成的特征对,例如agent i 的文本特征和agent j 的编码特征,即可称之为负对。追求负对相似度低的原因在于,希望模型能够学习到不同agent特有的视觉语义特征,区分不同的situation。
论文中提到,为了能够在一个batch中稳定优化,因此需要限制每个batch中负对的数量。
那么此时引发一个新问题,如何确定需要考虑的负对特征?/如何找到最需要被“关注”的负对?
此外,由于文本的描述是多样的,因此各个agent的文本特征也是多样的,这也给如何确定负对带来了困难。
本文的具体做法,通过BERT对agent的文本描述进行编码,得到word-level的embedding,然后在word-level embedding之间进行注意力操作,得到sentence-level embedding,然后求解此embedding之间的cosine相似度,筛选出小于阈值 ( )< 的嵌入,其中 代表阈值,本文取0.8。
按照升序进行排序,从前往后依次得到相似度逐渐递增的嵌入列表。选择前k个相似度最低的嵌入{ }代表的agent,取出这些agent的编码特征,组成负对
此部分的训练目标——正对足够接近,负对足够远离
将agent 的状态嵌入 和对应的文本描述嵌入 作为正对,agent 的状态嵌入和 top-k 的其他agent的嵌入 作为负对,使用 InfoNCE 损失来指导agent的状态嵌入和文本描述。
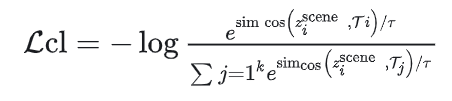
下图为具体的对比学习过程
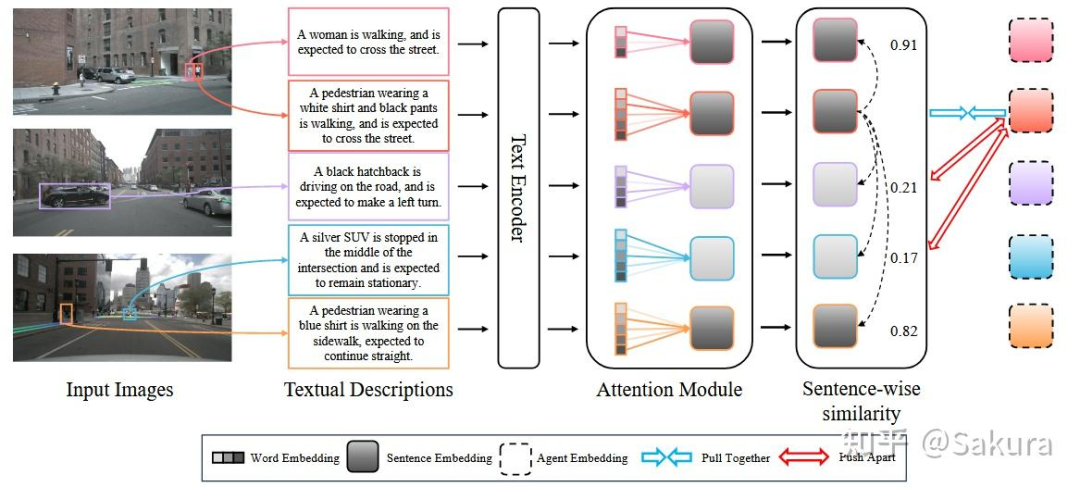
由上图可以看到,每张图片中的agent都对应一个句子描述,首先使用BERT对sentence中的word进行编码,即上图中的Text Encoder,得到word-level的embedding,然后使用attention,得到上图中灰黑色方框的sentence-level的embedding。计算各个sentence-level embedding之间的cos相似度,由相似度确定负对。
★笔者注:笔者先前也未了解对比学习,如有概念或理解上有偏差,请务必指出
此外,值得注意的是,此对比学习过程只会在训练的时候存在,该模块的作用就是为了让视觉语义特征编码器能够关注到更多有用的细节,故在推理阶段时,该对比学习过程是不存在的。
考虑旋转不变性的GMM参数学习网络——Trajectory Decoder
为什么需要Transformation Module?
根据HiVT等众多研究发现,场景元素之间的平移和旋转不变性对于轨迹预测网络的性能非常重要。
由于本文使用的是过去历史轨迹的相对位移,平移不变性得到了保证。但由于本文中agent坐标都是在自车坐标系下的,旋转不变性并没有得到保证。
在以往的工作HiVT中,平移不变形和旋转不变性是直接通过数据预处理实现的,在将数据输入进神经网络之前,处理原始历史轨迹时,转换为相对位移,以及按照各个local region的中心agent的坐标系进行旋转,从输入数据上保证了平移不变性和旋转不变性。
但现在输入的数据都是自车坐标系下的,自车的环视摄像头以及自车周围其他agent的位置及方向
★笔者注:理论上,此处其他agent的坐标完全可以表示为各自坐标系下的形式,类似于Hivt中的做法。笔者推测,由于本文使用自车上的环视摄像头图像,为了和图像特征对齐,就只能使用自车坐标系下的其他agent的坐标和方向。
既然没办法从输入数据入手解决旋转不变性,那就只能让模型学习到隐含在数据中的旋转不变性。因此本文提出了一个Transformation模块,该模块就是为了降低与学习旋转不变性的复杂度。
★笔者注:端到端自动驾驶的轨迹预测中的对称性是一个需要解决的问题,目前尚未看到较好的解决方案。受制于感知环节中的特征都是基于自车坐标系下的,轨迹预测无法很好地利用对称性。本文虽然提出用学习的方式学习旋转不变性缓解此问题,但是在端到端的过程中,agent的旋转方向该如何获得呢?只能通过接head输出吗?
基于前馈神经网络和门控单元的Transformation Module
通过简单的前馈神经网络将此agent的方向信息编码为特征,通过Gate单元将信息注入前述步骤中得到的agent特征中,希望模型能够学习到旋转不变性。
★笔者注:遗憾的是后文实验中并没有单独对此模块进行消融实验,尚不知此模块的真实效果如何
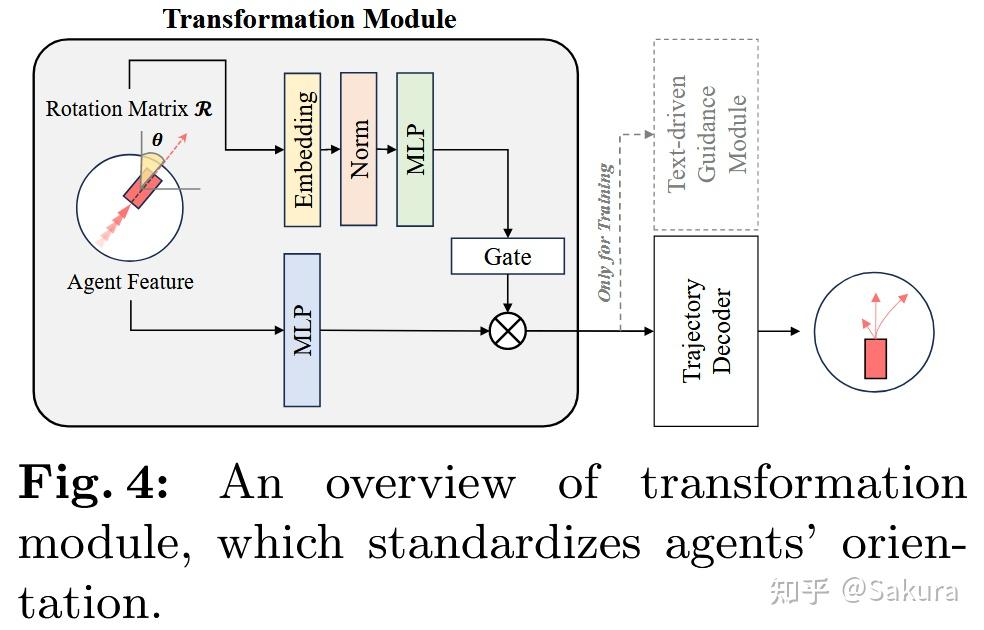
注入了agent方向信息的特征一方面输入至解码器中产生未来轨迹;另一方面输入至Text-driven Guidance Module中进行对比学习
将未来轨迹点分布建模为高斯混合模型——Trajectory Decoder

本文的解码器优化一个GMM,概率密度函数如下
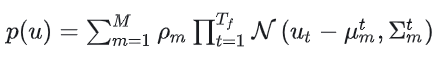

损失函数
损失函数为负对数似然概率
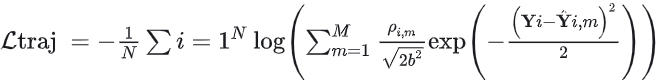
笔者注:形式上确实同GMM的负对数似然概率计算公式差不多,但是细节上对不上啊。原文中提到b为scale parameter,应该指的是标准差。系数的分母中的 为何没有?指数系数分母中的 为何没有?下面是一个一维GMM的负对数似然概率公式。
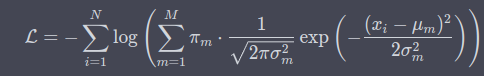
同时还优化一个辅助损失,该损失也是类似于上式中的负对数似然概率,是基于Recurrent Trajectory Prediction模块预测的初步轨迹计算的负对数似然概率,表示为 。此外,损失中还包含对比学习的损失infoNCE。
最终损失的计算公式如下
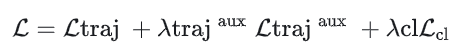
利用Fine-tuned VLM和LLM refine生成轨迹预测文本数据集——nuScenes-Text Dataset
DRAMA数据集不适用于预测任务——该数据集对每个场景中只有一个agent的描述,不符合预测任务
DRAMA数据集中只提供了不充分的文本描述,针对每个场景中每个agent只有一个单独的标题。这种文本描述适合检测任务,但是不适合预测任务
基于DRAMA对VLM进行fine-tuned+GPT细化文本描述
最初,论文采用预训练之后的VLM产生每个图片中的文本描述,但是发现效果不佳;后使用DRAMA数据集对VLM进行微调;将感兴趣agent的边界框区域同原始图像concat。然后利用微调之后的VLM为场景中每个agent单独生成一个标题caption
但是生成的描述通常缺乏正确的动作相关的细节,以及提供很多不必要信息。为了解决此问题,本文采用GPT细化VLM产生的文本
将产生的文本,agent类型以及机动作为输入,其中agent的机动是通过规则的方式判断的;使用提示词来纠正不合理的描述,希望经过GPT产生的文本能够提供预测相关的信息,包括agent类型,动作以及逻辑依据。下图为产生nuScenes-Text数据集的流程。
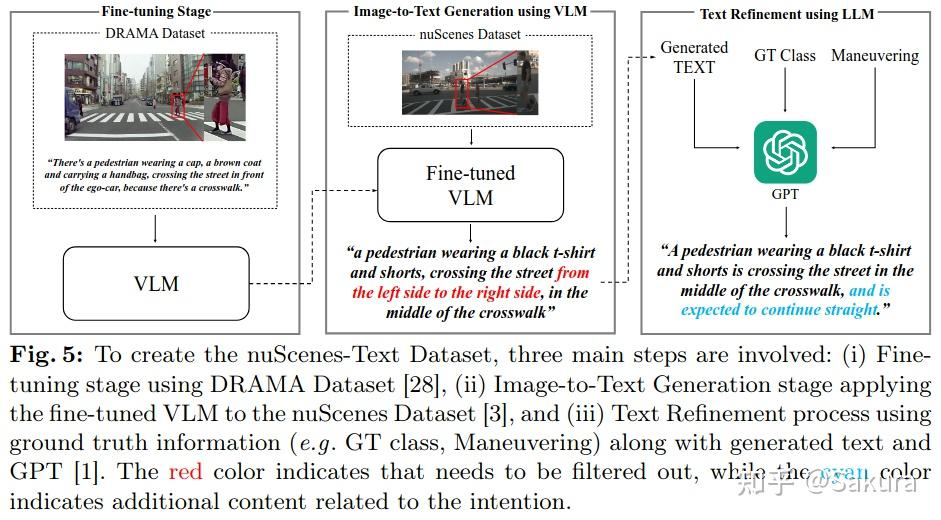
★笔者注:本文是通过规则的方式判断agent的机动类型,规则算法的具体描述详见本文后的补充材料中Fig3
nuScenes-Text数据集中样例分析及分析
本文在此处展示了该数据集中典型场景下的文本描述,以及分析数据集,用于说明本文提出的数据集的优势
下图展示了agent的行为随时间变化时,文本描述的变化

下图展示了生成的文本描述的多样性以及LLM对文本的细化

实验
下图展示了本文提出的轨迹预测方法在不同场景下的表现

上图展示了视觉语义编码器+文本驱动模块对轨迹预测的帮助
★笔者注:遗憾的是没有展示视觉语义编码器和文本驱动模块单独分别生效时的可视化表现,但后文的消融实验中包含了两者的消融实验结果
下面列举本文对上述实验结果的一些定性分析
视觉信息对轨迹预测有帮助;通过视觉信息输入,(a)图中由于红灯和相互交谈的行人未来的轨迹被预测为保持静止
行人的注视和身体朝向可以帮助预测行人穿越人行横道时的意图;
视觉信息可以提高现有预测的精度;(d)图中所示
视觉信息可以利用转向灯的信息;如(e)图所示
下表为实验指标的量化结果
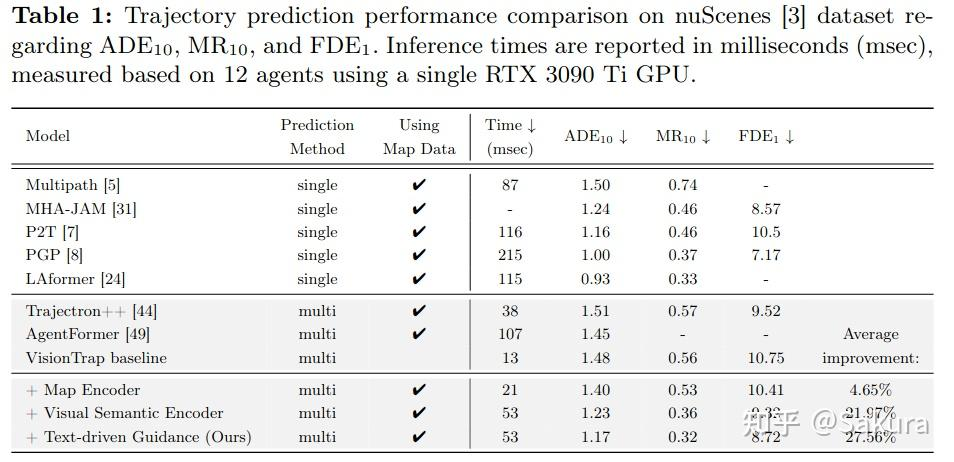
上表中可以发现视觉语义编码器和文本引导模块对于轨迹预测的精度提升是巨大的,两者对于结果的提升都是在20%以上,尤其是文本引导模块。
此外,本文还在整个nuScenes数据集上进行了测试,验证所提出的各个组件的有效性
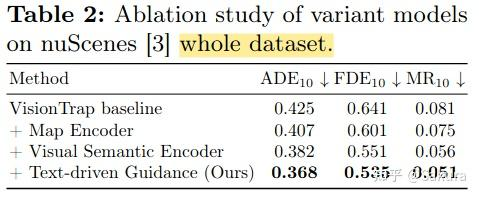
为了验证视觉信息引入和文本描述引导模块的作用,本文使用UMAP可视化了每个agent的状态嵌入,可视结果如下所示。可视结果证明了视觉信息和文本语义信息的引入改变了每个agent的状态嵌入。
当使用视觉和文本语义时,从UMAP图上可以看到agent状态嵌入之间的聚合程度得到了提升。在相同cluster中的agent具有相似的文本描述。
★笔者注:text-driven模块的作用之一就在于让处于类似情况的agent状态嵌入聚合在一起?

补充 下图为用于判断未来机动类型的规则算法

下图为LLM提示词样例

总结
本文提出的方法的关键创新点在于,利用文本描述”引导“模型学习图像语义特征,提高轨迹预测精度。本文的主要内容主要为以下几个方面:
图像信息对于轨迹预测很重要;利用BEV编码器提取bev特征,通过scene-agent交互向agent嵌入中注入来自图像特征的信息。
基于多模态对比学习,利用文本描述”引导“轨迹预测模型更好地利用图像信息,提高轨迹预测精度
基于fine-tuned的VLM和LLM创建适用于本文所提方法的text-nuScenes数据集
联系
近期涌现了很多将LLM同自动驾驶或轨迹预测相结合的工作
On the Road with GPT-4V(ision): Early Explorations of Visual-Language Model on Autonomous Driving——Arxiv 2023
Traj-LLM: A New Exploration for Empowering Trajectory Prediction with Pre-trained Large Language Models——IEEE TIV 2024
iMotion-LLM: Motion Prediction Instruction Tuning——Arxiv 2024
自动驾驶之心
论文辅导来啦

自驾交流群来啦!
自动驾驶之心创建了近百个技术交流群,涉及大模型、VLA、端到端、数据闭环、自动标注、BEV、Occupancy、多模态融合感知、传感器标定、3DGS、世界模型、在线地图、轨迹预测、规划控制等方向!欢迎添加小助理微信邀请进群。

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 810
810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









