



点击下方卡片,关注“大模型之心Tech”公众号
>>点击进入→大模型技术交流群
本文只做学术分享,如有侵权,联系删文
写在前面
当 Segment Anything Model(SAM) 以分割万物的能力震撼计算机视觉领域时,研究者们很快发现了它的局限:
无法同时处理多任务、难以应对类别特异性分割、更无法融入统一的多模态框架。
如今,来自中山大学、鹏城实验室和美团的团队提出了 X-SAM,一个将分割范式从分割任何事物推向任何分割的突破性框架。

在超过 20 个分割数据集、7 大核心任务上,X-SAM 全面超越现有模型,不仅能处理文本指令驱动的分割任务,还能理解点、框、涂鸦等视觉提示,甚至能在跨图像场景中实现精准分割。这一成果不仅刷新了像素级视觉理解的基准,更让多模态大模型真正具备了「看懂像素」的能力。
从 SAM 的局限到 X-SAM 的突破:为什么需要统一分割框架?
SAM 的出现曾被视为视觉分割的「万能钥匙」,它能通过点、框等视觉提示精准分割图像中的任意对象。但在实际应用中,研究者们逐渐发现了它的「短板」:
任务单一性:SAM 仅擅长基于视觉提示的单对象分割,无法同时处理语义分割(区分类别)、实例分割(区分个体)、全景分割(语义+实例)等复杂任务。
模态割裂:作为纯视觉模型,SAM 无法理解文本指令,例如「分割图中的红色汽车」这类自然语言查询对它而言如同天书。
多任务壁垒:现有分割模型往往针对单一任务设计,例如专门做交互式分割的模型无法处理开放词汇分割(分割训练中未见过的类别),工程落地时需要部署多个模型,效率极低。
与此同时,多模态大语言模型(MLLMs)如 LLaVA、GLaMM 虽然能理解文本与图像的关联,却止步于生成文本描述,无法输出精确的像素级分割结果。「能看懂图像却画不出边界,能分割像素却听不懂指令」,成为横亘在视觉分割与多模态理解之间的巨大鸿沟。

X-SAM 的诞生正是为了填补这一鸿沟。正如论文中所强调的:
任务制定:将SAM转变为一种具有跨任务适用性的通用分割架构。
模态增强:赋予大语言模型多模态输入处理能力。
统一框架:开发一种连贯的方法,以有效地促进跨不同领域的综合分割应用。
本文首发于大模型之心Tech知识星球,硬核资料在星球置顶:加入后可以获取大模型视频课程、代码学习资料及各细分领域学习路线~

技术解析:X-SAM 如何实现「万物可分」?
X-SAM 的核心创新在于将 SAM 的视觉分割能力与大语言模型的多模态理解能力深度融合,通过「统一输入格式」「双编码器架构」和「多阶段训练」三大支柱,实现了真正的「一站式」分割解决方案。
支柱一:统一输入格式,让所有任务「用同一种语言说话」
不同分割任务的输入形式千差万别:语义分割需要类别标签, referring 分割需要文本描述,交互式分割需要点或框。X-SAM 设计了一套统一的输入规则,让所有任务都能被模型「理解」:
文本查询输入:用
<p>和</p>标记需要分割的对象,例如「分割红色外套的女人
」。对于需要生成描述并同步分割的任务(如 GCG 分割),模型会自动在输出文本中插入<p>标签,再用<SEG>标记分割结果的位置。视觉查询输入:引入
<region>标签代表视觉提示(点、框、涂鸦等),格式为\<p>\<region>\</p>。模型会自动将视觉提示转换为特征,与文本指令融合处理。
通过这种设计,无论是「分割图中的猫」(文本指令)还是「分割这个框里的物体」(视觉提示),最终都会被转化为模型可统一处理的格式,为多任务融合奠定了基础。
支柱二:双编码器架构,兼顾全局理解与像素级细节
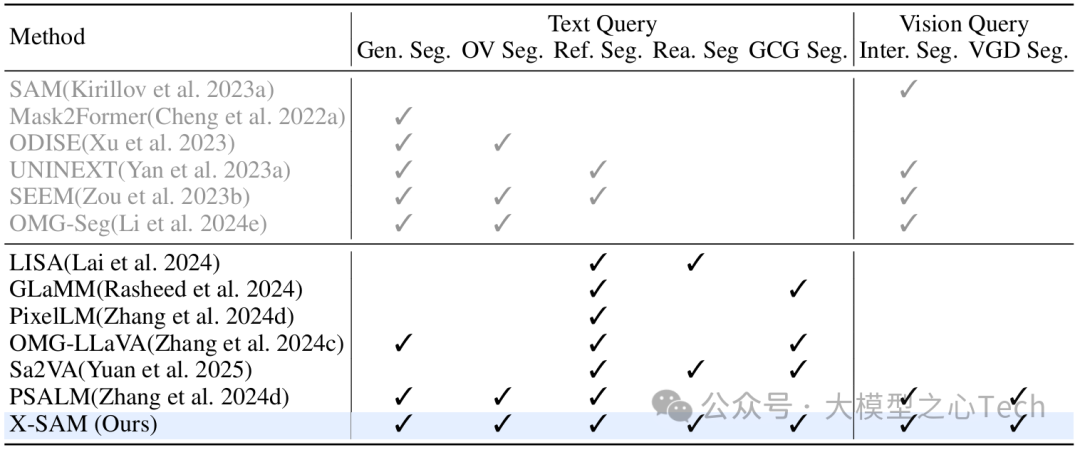
X-SAM 的架构堪称「视觉-语言」融合的典范,它包含五大核心模块:双编码器、双投影器、大语言模型(LLM)、分割连接器和分割解码器(如图 2 所示)。
双编码器:
图像编码器(采用 SigLIP2-so400m)负责提取全局图像特征,帮助模型理解整体场景(如「这是一张街景图」)。
分割编码器(基于 SAM-L)专注于细粒度像素特征,捕捉物体的边界细节(如「汽车的轮廓」)。
双投影器: 由于视觉特征与语言特征的维度不同,X-SAM 用两个 MLP 投影器将图像特征和分割特征转换为与语言模型匹配的维度。其中,分割特征通过「像素洗牌」(pixel shuffle)操作缩减空间尺寸,确保高效处理。
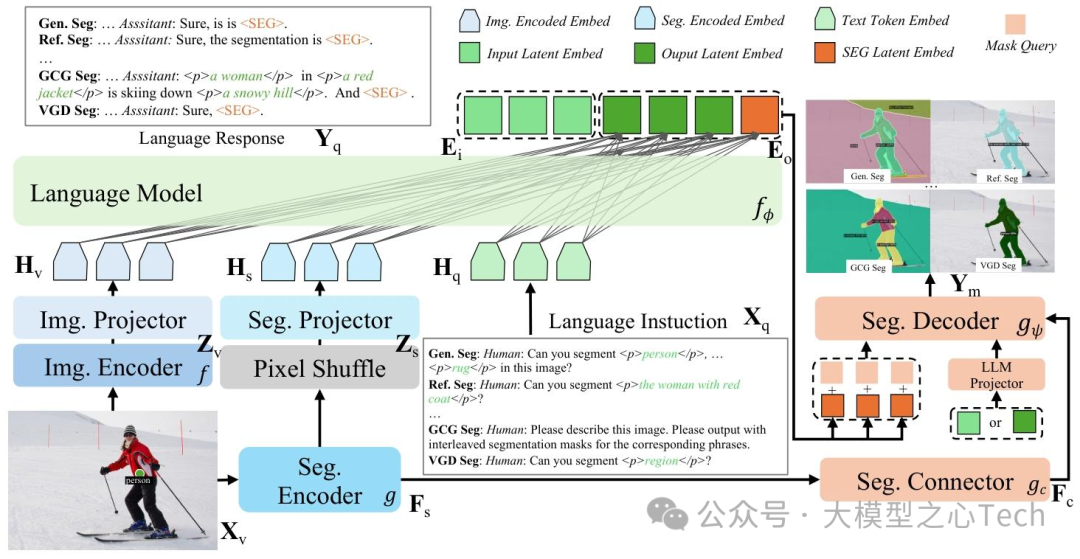
分割连接器(图3): SAM 输出的特征是单一尺度(1/16 分辨率),难以满足精细分割需求。X-SAM 设计了一个「分割连接器」,通过「补丁合并」(patch merge)和「补丁扩展」(patch expand)操作,生成 1/8、1/16、1/32 三种尺度的特征,让分割解码器能同时关注不同大小的物体。
分割解码器: 这是 X-SAM 突破 SAM 局限的关键。不同于 SAM 一次只能分割一个对象,X-SAM 的解码器基于 Mask2Former 架构,能一次性输出多个分割掩码,并通过 LLM 生成的
<SEG>标签关联对应的类别或描述。大语言模型(LLM): 采用 Phi-3-mini-4k-instruct 作为语言核心,负责解析文本指令、生成回答,并通过
<p><SEG>等标签与视觉模块交互。例如,当用户提问「描述图片并分割所有车辆」时,LLM 会生成包含<p> 汽车 </p><p> 卡车 </p><SEG>的输出,指导分割解码器生成对应掩码。
支柱三:多阶段训练,让模型「学透」所有任务
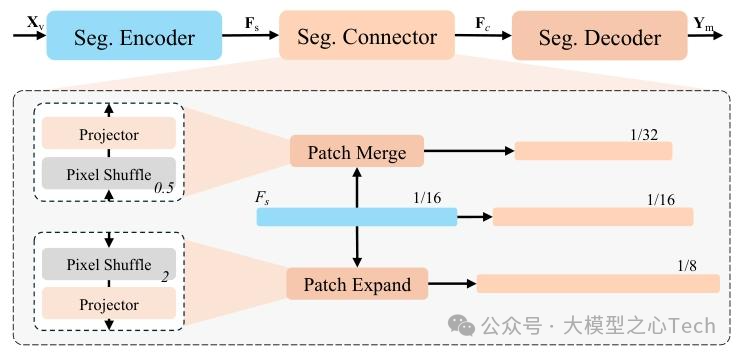
为了让 X-SAM 在多任务上同时达到最优,研究团队设计了三步走的训练策略:
分割器微调: 在 COCO 全景分割数据集上训练分割编码器和解码器,目标是让模型学会一次性分割多个对象。损失函数包括分类损失(区分类别)、掩码损失(匹配像素边界)和 dice 损失(衡量掩码重叠度),确保分割精度。
对齐预训练: 在 LLaVA-558K 数据集上训练双投影器,冻结图像编码器、分割编码器和 LLM 的参数。这一步的核心是让视觉特征(图像和分割)与语言模型的词嵌入空间对齐,例如让「猫」的文本嵌入与图像中猫的视觉特征距离更近。
混合微调: 将多种任务的数据集(包括语义分割、referring 分割、VGD 分割、图像对话等)混合训练,同时更新所有模块参数。对于对话任务,采用自回归损失;对于分割任务,则同时使用自回归损失和分割损失。这种「一锅烩」的训练方式,让模型在不同任务间互相促进,而非互相干扰。
特别值得一提的是,团队还提出了「数据集平衡重采样」策略。由于不同任务的数据集大小差异极大(从 0.2K 到 665K 样本),他们通过动态调整采样频率,确保小数据集(如推理分割)不会被大数据集(如图像对话)淹没,最终在 t=0.1 的参数设置下取得最优平衡。
任务拓展:VGD 分割让模型「看懂视觉提示」
X-SAM 最亮眼的创新之一,是提出了「视觉定位(VGD)分割」这一新任务。传统的交互式分割只能根据视觉提示分割单个对象,而 VGD 分割要求模型根据点、框、涂鸦或掩码等视觉提示,分割图像中所有同类实例。
例如,当用户用一个点标记图中的一只狗时,VGD 分割不仅要分割这只狗,还要自动找出并分割图中所有其他狗。更强大的是,X-SAM 还支持「跨图像 VGD 分割」:用一张图中的视觉提示,在另一张图中分割同类对象。
在 COCO-VGD 数据集上的实验显示,X-SAM 在点、涂鸦、框、掩码四种提示形式上的 AP(平均精度)分别达到 47.9、48.7、49.5、49.7,远超 PSALM 模型(仅 2.0-3.7)。这意味着 X-SAM 真正理解了视觉提示的「含义」,而不是简单地对提示区域进行分割。
全面霸榜:20+ 数据集验证「最强分割模型」
研究团队在 7 大核心任务、20 多个数据集上对 X-SAM 进行了全面测试,结果显示它在所有任务中均达到或超越当前最佳水平:

通用分割:在 COCO 全景分割中,X-SAM 的 PQ(全景质量)为 54.7,接近 Mask2Former(57.8),远超 OMG-LLaVA(53.8),证明其在基础分割任务上的稳健性。
开放词汇分割:在 A150-OV 数据集上,X-SAM 的 AP(平均精度)达到 16.2,远超 ODISE(14.4)和 PSALM(9.0),展现出分割「未见过的类别」的强大泛化能力。
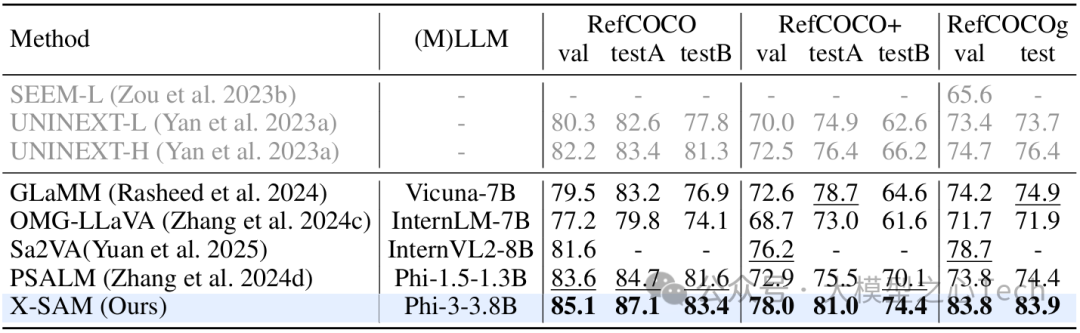
Referring 分割:在 RefCOCO、RefCOCO+、RefCOCOg 三大数据集上,X-SAM 的 cIoU(修正交并比)分别为 85.1、78.0、83.8,大幅领先 PSALM(83.6、72.9、73.8)和 Sa2VA(81.6、76.2、78.7),即使模型参数更小(3.8B vs 8B),仍能实现反超。
推理分割:在需要逻辑推理的分割任务中(如「分割用来播放音乐的东西」),X-SAM 的 gIoU(广义交并比)达到 56.6,超过专门优化推理能力的 LISA-7B(52.9),证明其融合语言推理与视觉分割的能力。
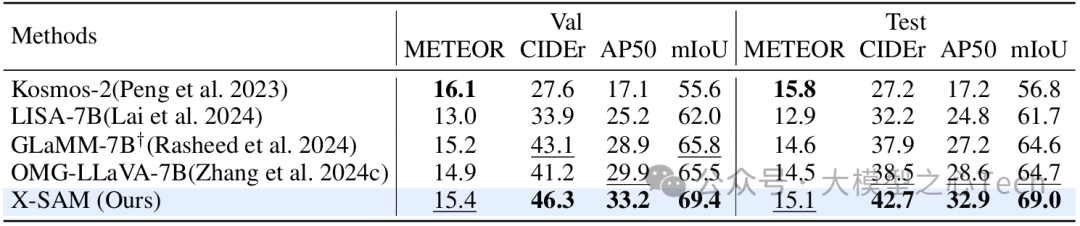
GCG 分割:在「描述图像并同步分割」任务中,X-SAM 的 mIoU(平均交并比)为 69.4,远超 GLaMM(65.8)和 OMG-LLaVA(65.5),既能生成准确的文本描述,又能输出精确的掩码。
交互式分割:在点、框提示下,X-SAM 的 mIoU 分别为 65.4 和 70.0,超过 SAM-L(51.8、76.6)和 PSALM(64.3、67.3),在未专门训练的情况下仍表现优异。

VGD 分割:如前文所述,X-SAM 以 47.9-49.7 的 AP 成绩大幅领先现有模型,验证了新任务设计的价值。
更令人惊叹的是,这些成绩均由同一个模型实现。无需针对不同任务调整架构或参数,X-SAM 就能在像素级理解的「全场景」中保持顶尖水准。
消融实验:揭秘 X-SAM 性能背后的关键设计
为了验证各模块的必要性,团队进行了细致的消融实验,结果揭示了几个关键发现:

混合微调的价值:仅用单一任务微调时,模型在开放词汇分割(A150-OV)的 AP 为 16.4,而混合微调后提升至 22.4,推理分割的 gIoU 从 48.2 跃升至 57.1。这证明多任务联合训练能显著提升模型的泛化能力,尽管会导致通用分割的 PQ 小幅下降(0.8),但整体收益远超损失。
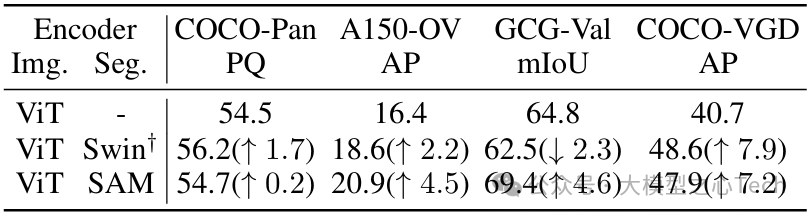
双编码器的优势:对比仅用图像编码器(ViT)、仅用分割编码器(Swin 或 SAM)的方案,双编码器组合能同时优化分割精度和语言理解。其中,SAM 作为分割编码器时,GCG 分割的 mIoU 达到 69.4,远超 Swin 编码器(62.5),证明 SAM 的视觉特征对分割任务至关重要。
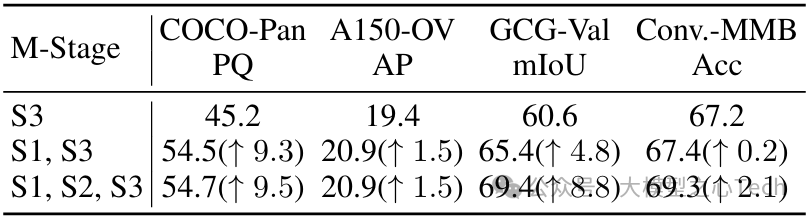
多阶段训练的作用:跳过分割器微调(仅用阶段 3)时,COCO 全景分割的 PQ 仅为 45.2,而加入阶段 1 后提升至 54.5;加入阶段 2 对齐预训练后,图像对话的准确率再提升 2.1%。三步训练环环相扣,缺一不可。
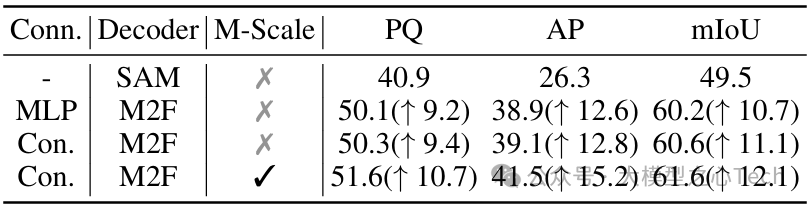
分割器架构的影响:采用 Mask2Former 解码器比 SAM 原生解码器的 PQ 提升 9.2,加入卷积连接器和多尺度特征后,PQ 再提升 1.3,证明精细的特征处理对分割精度的关键作用。
局限与未来:从图像到视频,分割之路仍在延伸
尽管 X-SAM 表现惊艳,论文也坦诚指出了其局限:
任务平衡难题:联合训练时,部分分割任务的性能会因对话数据的干扰而下降,如何设计更合理的数据集混合策略仍是挑战。
性能不均:在某些细分任务上(如语义分割的 mIoU),X-SAM 仍略逊于专门优化的模型,规模扩大(更大参数、更多数据)可能是突破方向。
未来,研究团队计划将 X-SAM 与 SAM2(支持视频分割的模型)结合,拓展至动态场景;同时将 VGD 分割延伸到视频领域,实现「跨时空视觉定位」。这些方向一旦突破,视觉分割将从静态图像迈向更广阔的视频理解场景。
参考
论文标题:X-SAM: From Segment Anything to Any Segmentation
论文链接:https://arxiv.org/pdf/2508.04655
开源链接:https://github.com/wanghao9610/X-SAM
大模型之心Tech知识星球交流社区
我们创建了一个全新的学习社区 —— “大模型之心Tech”知识星球,希望能够帮你把复杂的东西拆开,揉碎,整合,帮你快速打通从0到1的技术路径。
星球内容包含:每日大模型相关论文/技术报告更新、分类汇总(开源repo、大模型预训练、后训练、知识蒸馏、量化、推理模型、MoE、强化学习、RAG、提示工程等多个版块)、科研/办公助手、AI创作工具/产品测评、升学&求职&岗位推荐,等等。
星球成员平均每天花费不到0.3元,加入后3天内不满意可随时退款,欢迎扫码加入一起学习一起卷!


















 2922
2922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









