



来源 | 深蓝AI
点击下方卡片,关注“自动驾驶之心”公众号

>>自动驾驶前沿信息获取→自动驾驶之心知识星球
本文只做学术分享,如有侵权,联系删文
导读
人类在公路上驾驶车辆的时候往往会这样思考:先扫一眼整体路况——有没有学校、施工、突然滚到路中央的足球;再决定是变道还是减速;最后才打方向、踩刹车。短短几秒,人脑完成了“策略–战术–操作”三层级联推理,而今天的端到端自动驾驶却大多只会“直接吐轨迹”,既解释不了自己为什么这么做,也应付不了没见过的新场景。
为了弥补这一差距,上海科技大学 & 香港中文大学的最新工作 ReAL-AD 把「人类式思考」搬进了自动驾驶决策模型之中。它一种推理增强学习框架,基于三层人类认知模型(驾驶策略、驾驶决策和驾驶操作)来构建自动驾驶中的决策过程,并引入视觉-语言模型(VLMs)以增强环境感知和结构化推理能力。简单来说,它会让VLM担任“副驾驶”,先把画面翻译成“看到足球→可能有小孩→需减速避让”的高维策略,再细化为“保持车道、减速 20%”的战术命令,最终由分层解码器输出平滑轨迹。下面就让我们一起来看一看ReAL-AD这篇工作吧~
论文出处:ICCV 2025
论文标题:ReAL-AD: Towards Human-Like Reasoning in End-to-End Autonomous Driving
论文作者:Yuhang Lu, Jiadong Tu, Yuexin Ma, Xinge Zhu
论文链接:https://arxiv.org/abs/2507.12499
1
—
背景信息
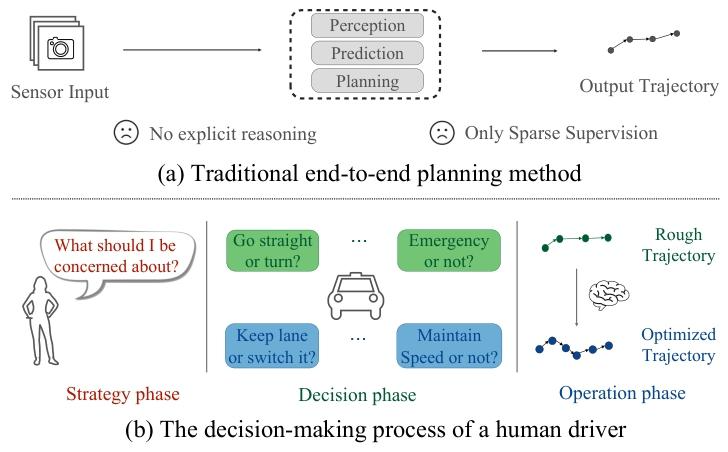
图1|端到端自动驾驶网络和人类驾驶决策逻辑对比
在基于视觉的端到端自动驾驶系统中,多视角相机图像流首先通过图像主干网络(例如 ResNet)进行处理,以提取二维视觉特征。随后,这些特征通过视图变换模块被转换为三维或鸟瞰图(Bird’s Eye View, BEV)场景表示,从而捕捉场景几何信息,例如道路布局、交通参与者位置以及车道拓扑结构。基于 Transformer 的任务特定解码器使任务查询(例如交通参与者查询、地图查询)能够与场景特征进行交互,建模出与规划相关的表示。规划模块初始化一个自我查询(ego-query)嵌入,该嵌入通过交叉注意力层关注场景特征和任务查询,构建自我特征(ego-features),从而使自我车辆能够将其状态置于上下文中。最后,轨迹解码器(通常是一个多层感知机,MLP)通过从自我特征进行回归,预测未来的航点。
2
—
总体架构
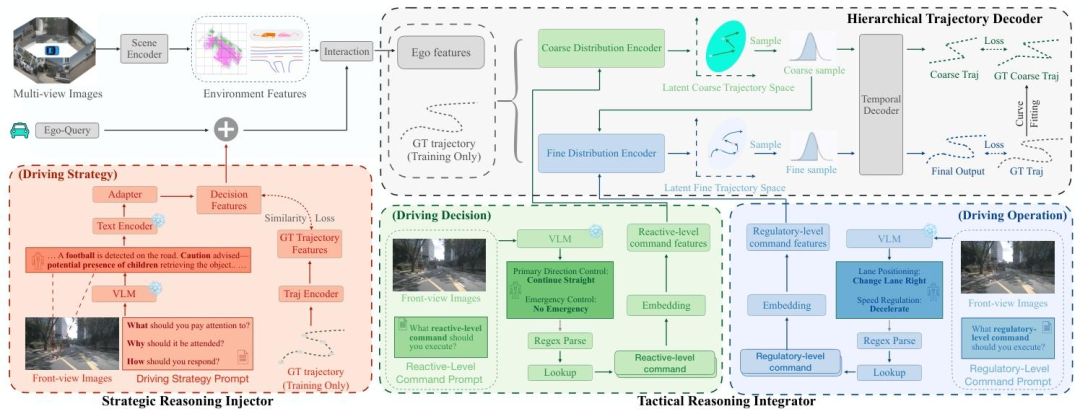
图2|ReAL-AD整体架构图
ReAL-AD的整体架构见上图(图2),这是一个带有VLM的类人推理增强学习框架,包含三个部分:
(1) 策略推理注入器(Strategic Reasoning Injector):利用 VLM 生成的洞察解析复杂交通情境,形成高层驾驶策略;
(2) 战术推理整合器(Tactical Reasoning Integrator):将策略意图进一步细化为可解释的战术选择;
(3) 分层轨迹解码器(Hierarchical Trajectory Decoder):模拟人类“直觉—细化”的决策过程,先建立粗略运动模式,再逐步精修为详细轨迹。
下面将详细介绍这三部分的内容
3
—
策略推理注入器——模型的眼睛

图3|VLM的输出结果示例
在驾驶场景中,人类司机会先通过识别关键交通参与者或相关法规来制定驾驶策略——研究人员将这一认知过程复现为由 VLM 生成的推理过程。随后,这些推理过程将被编码,用于引导 ego-query,从而开始整个规划过程。
VLM首先通过基于prompt引导的视觉推理生成驾驶策略文本:
其中 代表 VLM 处理器, 代表视觉输入, 代表驾驶策略 prompt 模板。 随后, 生成的策略文本 通过一个预训练的语言编码器编码进入语义空间。为了 弥补语义空间与视觉感知之间的差距, 研究人员还实现了一个轻量的 adaptor:
同样地, 研究人员还把真实轨迹 编码进入通过轨迹编码器 规划特征 中, 使用余弦相似度损失来强制策略语义与规划动态保持一致:
优化后的策略特征随后通过残差更新的方式融入 :
该做法将 VLM 获得的推理能力注入 , 使其在与环境特征交互时能够有针对性地获取与规划相关的关键信息。
4
—
战术推理整合器——模型的大脑
虽然驾驶策略提供了语义层面的上下文,但其表述抽象(例如“让行来车”),往往缺乏可直接用于轨迹规划的可执行指令。为了弥合这一缺口,研究人员引入了战术指令,将语义策略转化为可执行的选择,从而在策略规划和战术驾驶决策与操作之间建立双层推理机制。
通过类别约束的视觉推理,让 VLM 生成结构化指令:
其中 表示命令提示模板, 并强制输出遵循四大类格式:方向 (Direction)、紧 急 (Emergency)、车道 (Lane) 和速度 (Speed)。 原始的文本输入经过如下的程得到可执行的指令:
其中 是预定义好的正则表达式匹配表达式。然后再每一条指令分别经过特定的类别编码器进行编码以及进行策略混合:
其中 是可学习的编码矩阵。随后,编码后的特征按车辆控制层级进行划分
编码的是瞬时反应层的驾驶决策,而 编码的则是在深思熟虑后发出的驾驶操作指令。这两条命令在后续层轨迹解码器的不同层级中各自职,从粗到细地生成人类轨迹提供详尽且精准的指令。
5
—
分层轨迹解码器——模型的左膀右臂
受人类驾驶认知“先瞬时反应、后深思熟虑”的分层特性启发,研究人员提出一种双层变分解码器,其潜在轨迹空间同时以驾驶决策层与驾驶操作层的控制信号为条件。
第一层解码器以自车特征与反应级战术指令(方向意图与紧急指示)为条件,通过条件变分推断建立粗略运动模式:
1. 分布参数化:将输入映射到潜在粗粒度轨迹空间
2. 隐空间采样: 提取全局动作模式
其中 为自行车特征, 表示反应级指令特征, 粗粒度潜码 用于刻画宏观运动模式。
第二层是在第一层得到的粗略运动模式基础上, 融合多源条件信息, 并将其映射为精细的轨迹表征, 实现由粗到细的运动规划。
1. 分层细化: 以粗略运动模式和监管级指令为条件, 对潜在精细轨迹空间进行约束。
2. 隐空间采样: 采样精细轨迹表示
其中, 表示规则层面的指令特征, 用于编码车道管理和速度控制的选 择。
在通过分层变分过程获得隐空间表征 和 之后, 下一步是将这些隐变量解码为实际的轨迹序列。研究人员设计的轨迹解码器还对时间进行了建模, 采用了双潜胫流处理。具体过程如下:
Coarse Stream:
Fine Stream:
其中, 和 分别表示粗略轨迹和精细轨迹的潜在表示; 表示未来时间步的数量, 和 分别对应于粗轨迹和细轨迹的潜在特征序列; 和 分别表示计划的粗轨迹和细轨迹。
6
—
损失函数——模型优化的目标
复合损失函数整合了五个任务目标,以实现有效的分层学习:
基准模型损失 研究人员保留了所有基准模型的损失,记为
策略推理注入损失 对于策略推理注入模块,研究人员引入了两种损失
1. : 该损失用于确保策略语义与规划动态之间的一致性,如第 3.3 节所述。
2. : 该损失用于监督 GT (Ground Truth) 轨迹编码,以确保特征表示的正确性:
其中, 表示分层轨迹解码器。
分层轨迹解码器损失 为了确保有效的分层轨迹规划,研究人员为分层轨迹解码器引入了两个关键的损失函数:
: 该损失将基线目标应用于预测的粗轨迹 和经过 Bézier 曲线拟合的粗轨迹真实值 。
: 该损失通过两级KL散度公式, 强制要求分层潜在空间之间的一致性:
对于层级 , KL 散度的计算公式为:
随后, 整体的分层 KL 损失计算如下:
7
—
实验结果
实验设置
基准选择:ReAL-AD方法支持不同的端到端规划网络和 VLM。研究人员选择 VAD 和 UniAD 作为基线模型,并选用 MiniCPMLlama3-2.5V 和 Qwen-VL 作为视觉语言模型。
数据集:研究人员在 nuScenes 数据集上评估开环规划性能,该数据集包含 1000 个 20 秒的场景,采样频率为 2Hz,是端到端(E2E)自动驾驶领域的一个关键基准数据集。对于开环和闭环评估,研究人员使用 Bench2Drive数据集,它包含来自 13638 个剪辑的 200 万帧,覆盖 44 种场景、23 种天气条件和 12 个 CARLA v2 城市。其严格的闭环评估协议通过 220 条路线对端到端自动驾驶(E2E-AD)模型进行评估,确保了性能评估的公平性和全面性。
评估指标:对于开环评估,研究人员使用 L2 误差和碰撞率。L2 误差用于衡量规划轨迹与真实轨迹之间的距离,而碰撞率则用于量化与交通参与者的碰撞次数。默认情况下,研究人员使用VAD指标在 1 秒、2 秒和 3 秒时进行评估。对于闭环评估,研究人员使用驾驶评分(Driving Score)和成功率(Success Rate)作为评估指标。驾驶评分反映了带有违规行为的路线完成情况,而成功率则是没有违规完成路线的百分比。
主要结果
开环评估:为了更好地评估ReAL-AD框架的有效性,研究人员在nuScenes和 Bench2Drive 数据集上将我们的方法与几种最先进的方法进行了比较。如表 1 和表 2 所示,与基线方法 VAD 和 UniAD 相比,ReAL-AD方法在 L2 误差和碰撞率方面取得了显著的改进,改进幅度超过 30%。值得注意的是,我们的性能也优于其他使用相同基线的 VLM 辅助方法(如 VLP 和 VLM-AD),在 nuScenes 数据集上实现了最低的平均 L2 误差(0.48 米)和碰撞率(0.15%),在 Bench2Drive 数据集上则分别为 0.84 米和 0.12%。这表明引入人类决策过程使得网络在学习驾驶能力方面更加有效。
闭环评估:尽管开环指标能够提供部分性能结果,但为了评估实际应用中的表现,研究人员在 Bench2Drive 数据集上进行了闭环评估。结果显示,在引入ReAL-AD框架后,驾驶评分和完成路径的数量相较于基线都有了显著提升,这表明成功引入人类思维过程极大地提高了驾驶能力。
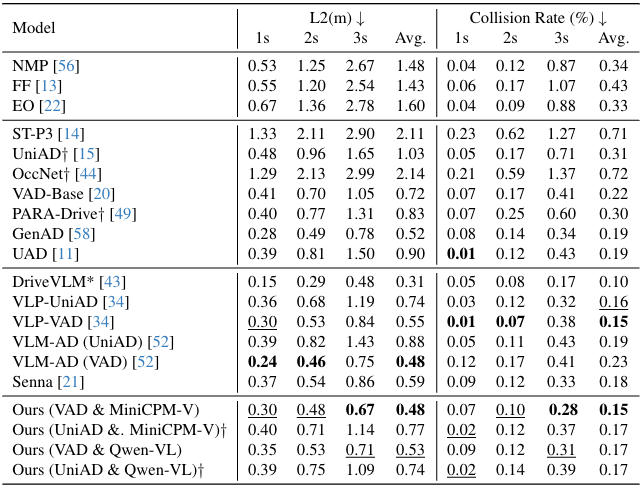
表1|nuScenes 数据集上的开环规划评估结果
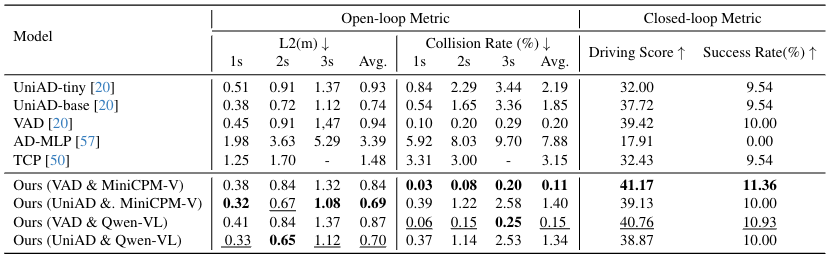
表2|Bench2Drive 数据集上的开环和闭环规划评估结果
消融实验
研究人员在 Bench2Drive 验证集上进行了消融研究,以评估ReAL-AD提出的各个模块。参考 VAD 的方法,研究人员在这里采用了两阶段训练策略以加速实验进程。所有消融模型都共享相同的阶段一检查点,以确保公平比较,并且所有实验均使用 NVIDIA 4090 GPU,基于 VAD 和 MiniCPMLlama3-2.5V 的基线进行。
策略推理注入器的有效性:为了评估策略推理注入器模块的有效性,研究人员通过移除该模块进行了消融研究。如表 3 所示(设置 0 和 1),移除该模块后,平均 L2 误差增加了约 12%,平均碰撞率增加了 19%。这些结果表明,策略决策引导自我查询建模,使其能够自适应地优先处理与当前场景决策过程相关的信息,从而提升了整体规划性能。
战术推理整合器的有效性:如表 3 所示,研究人员通过实验2和实验6验证了该模块的有效性。在实验2 中,研究人员将嵌入的命令特征与建模的自我查询特征进行拼接,并通过解码器获得最终输出。比较实验 0 和 2,观察到平均 L2 误差减少了 0.14 米,平均碰撞率降低了 0.05%。这些结果表明,战术命令比战略决策更接近规划,提供了更具体的指导,降低了学习空间的复杂性,并使网络能够做出更明智的决策。
分层轨迹解码器的有效性:为了凸显分层轨迹解码器的重要性,研究人员将其替换为一个多层感知机(MLP),该 MLP 直接根据自我特征预测未来的轨迹。这一修改导致 L2 误差增加了 0.07 米,碰撞率上升了 0.07%(比较设置 0 和 3)。这表明直接解码细粒度轨迹存在挑战。缺少从简单到复杂、从粗到细的分层解码过程,阻碍了模型对轨迹预测的精细化调整能力,最终导致性能次优。
8
—
结论
这篇工作提出了 ReAL-AD,这是一个增强型的端到端自动驾驶学习框架,通过利用视觉语言模型在策略、决策和操作层面进行结构化推理,从而提升自动驾驶的性能。ReAL-AD 模拟人类的分层决策过程,将战略决策、战术指令和轨迹细化相结合。在 NuScenes 和 Bench2Drive 数据集上的广泛实验表明,该框架在轨迹规划精度和驾驶安全方面达到了最先进的水平。
自动驾驶之心
论文辅导来啦

自驾交流群来啦!
自动驾驶之心创建了近百个技术交流群,涉及大模型、VLA、端到端、数据闭环、自动标注、BEV、Occupancy、多模态融合感知、传感器标定、3DGS、世界模型、在线地图、轨迹预测、规划控制等方向!欢迎添加小助理微信邀请进群。

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









