



作者 | Sakura 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/1933901730589962575
点击下方卡片,关注“自动驾驶之心”公众号

>>自动驾驶前沿信息获取→自动驾驶之心知识星球
本文只做学术分享,如有侵权,联系删文
写在前面--先聊聊为啥写这篇文章
笔者这段时间阅读了来自ICCV2025的论文DONUT: A Decoder-Only Model for Trajectory Prediction
这篇论文以qcnet为baseline,基于decoder-only架构配合overprediction策略,在argoversev2上取得了SOTA
联想到之前笔者所阅读的论文SmartRefine,该论文也是基于Qcnet的基础上对refine部分进行改进,也在argoverse v2上取得了SOTA;
因此,本着学习的态度,笔者想在此简单总结这三篇论文;
Query-Centric Trajectory Prediction--CVPR 2023
SmartRefine: A Scenario-Adaptive Refinement Framework for Efficient Motion Prediction--CVPR 2024
DONUT: A Decoder-Only Model for Trajectory Prediction--ICCV 2025
先看qcnet
Query-Centric Trajectory Prediction--CVPR 2023
两个关键点
笔者理解该文有两个关键点:
以查询为中心的场景编码范式
这种场景编码范式使得模型学习的表示是独立于全局时空坐标系的,带来一个好处,可以复用过去的历史计算,无需重新规范化和重新编码输入
propose+refine两阶段轨迹解码范式
首先采用无锚query以循环方式生成轨迹proposal;然后通过refiner将proposal 轨迹作为锚点,基于锚点的query细化预测轨迹
接下来具体看这两个关键点
以查询为中心的场景编码范式
传统的场景编码方式--当前时刻的直角坐标系下状态表示
传统的编码方式是利用时间网络来压缩时间维度,然后仅仅在当前时间步执行map-agent, agent-agent的融合;这种方式没有factorized attention更好;factorized attention在每个时间步中进行特征融合,因此,因子化注意力可以捕获更多信息,例如代理和地图元素之间的关系如何在观察范围内演变。
轨迹预测是一项流式处理任务;但是传统的场景编码方式中依赖于当前时刻的局部坐标系,这导致后续时间步的推理过程中无法直接使用之前时间步计算得到的特征
以查询为中心的编码范式--每个时刻的极坐标系下的状态表示
引入一种以查询为中心的编码范式,用于学习独立于场景元素全局坐标的表示;如下图所示
具体来说,我们为每个场景元素建立一个局部时空坐标系,在其局部参考系中处理查询元素的特征,然后,在执行基于注意力的场景上下文融合时,我们将相对时空位置注入到键和值向量中。
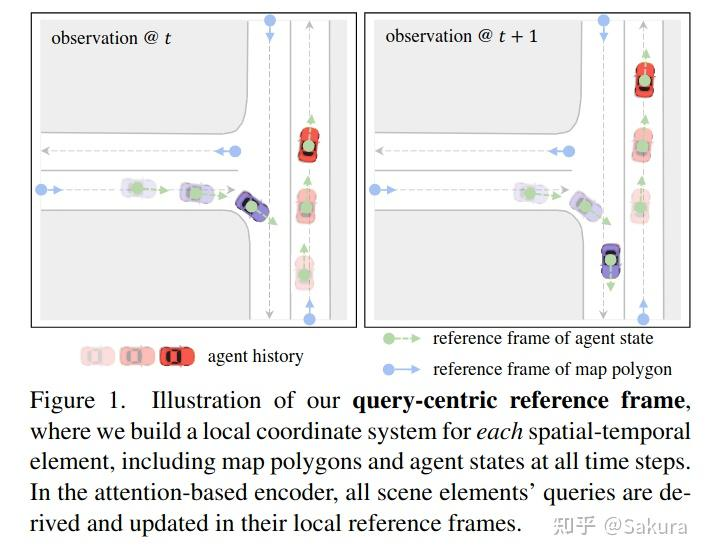
换个更加容易理解的语言来阐述,其实就是以每个时刻的位置为极坐标的极点,heading vector的方向为极轴表示agent自身状态,map元素,agent之间的相对状态,agent-map之间的相对状态;
具体来说就是表示agent自身位移矢量,速度矢量,map元素中点的位置及相对位置矢量,agent-agent之间相对位置矢量,以及agent-map相对位置矢量
这个地方插一嘴,为啥叫query-centric编码范式?这是由于每个时刻的状态在每个时刻的局部坐标系下表示后,经过编码,然后在注意力操作中会成为query,所以称之为query-centric的场景编码范式;换个名字叫every-timestamp local centric都行
直接看代码理解更清晰!
1. 先看怎么表示agent自身状态--位移矢量+速度矢量在极坐标系下拆分成大小和方向
下面是qcnet代码中对agent的输入状态的构成,分为位移大小,位移向量同航向向量的夹角,速度大小,速度矢量同航向向量的夹角
x_a = torch.stack(
[torch.norm(motion_vector_a[:, :, :2], p=2, dim=-1), #计算位移向量的大小
angle_between_2d_vectors(ctr_vector=head_vector_a, nbr_vector=motion_vector_a[:, :, :2]), #计算航向向量同位移向量之间的角度差异
torch.norm(vel[:, :, :2], p=2, dim=-1), #计算速度矢量的大小
angle_between_2d_vectors(ctr_vector=head_vector_a, nbr_vector=vel[:, :, :2])], dim=-1) #航向同速度向量之间的夹角通过一个FourierEmbedding对象self.x_a_emb进行编码
x_a = self.x_a_emb(continuous_inputs=x_a.view(-1, x_a.size(-1)), categorical_embs=categorical_embs) #车辆历史轨迹的编码得到傅里叶特征之后同语义特征级联
2. 再看agent-agent之间的相对状态怎么表示--相对位置矢量大小,相对位置矢量方向,相对方向以及时间差
我们为场景元素对准备相对位置嵌入,它将被合并到基于注意力的运算符中,以帮助模型了解两个元素的局部坐标系之间的差异。
用4D的描述符来总结他们的相对位置;具体来说,对于两个坐标系 和
4D描述符包含,两个坐标系原点之间的距离 ,两个坐标系的相对方向
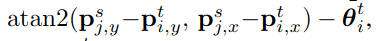
以及两个坐标系的方向差 ,时间差S-T;经过堆叠的MLP后得到fourier features,表示为
这个地方有补充,agent-agent之间的相对位置表示不仅仅是不同agent之间的,同一个agent不同时刻也可以看作是两个agent之间的相对状态,也需要按照上述方式表示并进行编码
以下是同一个agent不同时间步相对位置编码的代码
# mask_t 是按照时间步是否存在构建的智能体到智能体之间的邻接矩阵
mask_t = mask.unsqueeze(2) & mask.unsqueeze(1)
edge_index_t = dense_to_sparse(mask_t)[0] #这一行将密集的邻接矩阵mask_t转换为稀疏格式,可能是边索引的列表。[0]表示只关注第一个输出,
edge_index_t = edge_index_t[:, edge_index_t[1] > edge_index_t[0]] #??? 这过滤掉自环边,并确保图没有无向边,只保留边(i, j),其中j大于i。
edge_index_t = edge_index_t[:, edge_index_t[1] - edge_index_t[0] <= self.time_span] #进一步基于时间条件过滤边,只保留表示在self.time_span时间范围内的连接的边。
rel_pos_t = pos_t[edge_index_t[0]] - pos_t[edge_index_t[1]] # 构建车辆之间的相对位置向量
rel_head_t = wrap_angle(head_t[edge_index_t[0]] - head_t[edge_index_t[1]])
r_t = torch.stack(
[torch.norm(rel_pos_t[:, :2], p=2, dim=-1),
angle_between_2d_vectors(ctr_vector=head_vector_t[edge_index_t[1]], nbr_vector=rel_pos_t[:, :2]), #计算车辆之间的相对位置向量与航向向量之间的夹角
rel_head_t, # 相对航向差异
edge_index_t[0] - edge_index_t[1]], dim=-1) # 时刻差异
r_t = self.r_t_emb(continuous_inputs=r_t, categorical_embs=None)以下是不同agent之间相对状态的编码
edge_index_a2a = radius_graph(x=pos_s[:, :2], r=self.a2a_radius, batch=batch_s, loop=False,
max_num_neighbors=300)
edge_index_a2a = subgraph(subset=mask_s, edge_index=edge_index_a2a)[0]
rel_pos_a2a = pos_s[edge_index_a2a[0]] - pos_s[edge_index_a2a[1]]
rel_head_a2a = wrap_angle(head_s[edge_index_a2a[0]] - head_s[edge_index_a2a[1]])
r_a2a = torch.stack(
[torch.norm(rel_pos_a2a[:, :2], p=2, dim=-1),
angle_between_2d_vectors(ctr_vector=head_vector_s[edge_index_a2a[1]], nbr_vector=rel_pos_a2a[:, :2]),
rel_head_a2a], dim=-1)
r_a2a = self.r_a2a_emb(continuous_inputs=r_a2a, categorical_embs=None)3. 再看如何表示map元素中的点及相对位置矢量--地图元素在polygon级别表示为第一个点+第一个点的方向,在点级别表示为相邻点矢量大小+矢量方向
qcent中对map元素的处理分为点级别和polygon级别(类似于vectornet,这个polygon级别可以理解为就是一个实例级别,可能是一个lane_segment,也可能是一个cross_walk)
对于polygon级别:取每个polygon第一个点的位置及方向
lane_segment_idx = polygon_ids.index(lane_segment.id)
centerline = torch.from_numpy(centerlines[lane_segment.id].xyz).float() #获得指定lane_segment的中心线坐标的numpy矩阵,维度为[n 3]
polygon_position[lane_segment_idx] = centerline[0, :self.dim]
polygon_orientation[lane_segment_idx] = torch.atan2(centerline[1, 1] - centerline[0, 1], #按照两个centerlines上的点的坐标计算方向,得到夹角
centerline[1, 0] - centerline[0, 0])
polygon_height[lane_segment_idx] = centerline[1, 2] - centerline[0, 2]
polygon_type[lane_segment_idx] = self._polygon_types.index(lane_segment.lane_type.value) #lane_type 指示哪些车辆类型可以使用此类车道
polygon_is_intersection[lane_segment_idx] = self._polygon_is_intersections.index(
lane_segment.is_intersection)就是取lane_segment中的中心线中第一个点的坐标及方向,cross_walk中起始位置和方向作为polygon的位置及方向
对于点级别:取相邻点构成的矢量和方向
map元素中点的位置表示倒是很简单,取的是相邻点坐标构成的矢量,这段代码在数据集预处理argoversev2Dataset中
left_boundary = torch.from_numpy(lane_segment.left_lane_boundary.xyz).float()
right_boundary = torch.from_numpy(lane_segment.right_lane_boundary.xyz).float()
point_position[lane_segment_idx] = torch.cat([left_boundary[:-1, :self.dim], #获得指定lane_segment的左边界、右边界和中心线的坐标,截止到倒数第二个点
right_boundary[:-1, :self.dim],
centerline[:-1, :self.dim]], dim=0) #此lane_segment的所有点的位置信息
left_vectors = left_boundary[1:] - left_boundary[:-1] #left_boundary是从何而来
right_vectors = right_boundary[1:] - right_boundary[:-1]
center_vectors = centerline[1:] - centerline[:-1]
point_orientation[lane_segment_idx] = torch.cat([torch.atan2(left_vectors[:, 1], left_vectors[:, 0]),
torch.atan2(right_vectors[:, 1], right_vectors[:, 0]),
torch.atan2(center_vectors[:, 1], center_vectors[:, 0])],
dim=0)
point_magnitude[lane_segment_idx] = torch.norm(torch.cat([left_vectors[:, :2],
right_vectors[:, :2],
center_vectors[:, :2]], dim=0), p=2, dim=-1) #计算lane_segment中每个点到点之间向量的长度
point_height[lane_segment_idx] = torch.cat([left_vectors[:, 2], right_vectors[:, 2], center_vectors[:, 2]],
dim=0)上述代码列举了lane_segment中点的状态处理,point_magnitude就是矢量的长度,point_orientation是矢量的方向
写至此处,其实已经将qcnet中对于地图元素如何表示的部分阐述完毕了;但是仅仅依赖上述内容还不便于理解;下面再看下map encoder如何处理
总体思路类似于vectornet,现在polygon内部聚合特征(同一个polygon的点之间),然后是polygon之间聚合特征(polygon之间交互)
具体代码如下,位于qcnet中的QCNetMapEncoder对象的forward中;
#调用contiguous产生一个新的tensor,其数据在内存中是连续的
pos_pt = data['map_point']['position'][:, :self.input_dim].contiguous() #map_point position中存放了当前地图中所有lane_segments和cross_walks的点的坐标
orient_pt = data['map_point']['orientation'].contiguous() #存放地图中所有点的方向,角度
pos_pl = data['map_polygon']['position'][:, :self.input_dim].contiguous() #存放地图中所有的lane_segments中心线的第一个点的坐标以及cross_walks的中心线的两个点的坐标
orient_pl = data['map_polygon']['orientation'].contiguous() #存放地图中中心线中的第一个点的方向
orient_vector_pl = torch.stack([orient_pl.cos(), orient_pl.sin()], dim=-1) #地图中的lane_segments和cross_walks的中心线的第一个点的方向向量
if self.dataset == 'argoverse_v2':
if self.input_dim == 2:
x_pt = data['map_point']['magnitude'].unsqueeze(-1) #data['map_point']['magnitude']存放的是点到点之间的长度
x_pl = None
elif self.input_dim == 3:
x_pt = torch.stack([data['map_point']['magnitude'], data['map_point']['height']], dim=-1)
x_pl = data['map_polygon']['height'].unsqueeze(-1)
else:
raise ValueError('{} is not a valid dimension'.format(self.input_dim))
x_pt_categorical_embs = [self.type_pt_emb(data['map_point']['type'].long()),
self.side_pt_emb(data['map_point']['side'].long())] #对点的类型和边的类型进行embedding
x_pl_categorical_embs = [self.type_pl_emb(data['map_polygon']['type'].long()),
self.int_pl_emb(data['map_polygon']['is_intersection'].long())]
else:
raise ValueError('{} is not a valid dataset'.format(self.dataset))
x_pt = self.x_pt_emb(continuous_inputs=x_pt, categorical_embs=x_pt_categorical_embs) #对点的位置和类型进行embedding
x_pl = self.x_pl_emb(continuous_inputs=x_pl, categorical_embs=x_pl_categorical_embs) #对边的位置和类型进行embedding默认的input_dim为2,取polygon中点的矢量的大小,使用fourier_emb编码得到傅里叶特征x_pt
polygon内部的特征聚合代码如下,需要构造polygon内部中点点之间相对状态表示及编码
edge_index_pt2pl = data['map_point', 'to', 'map_polygon']['edge_index'] #描述当前地图中点与多边形之间所属关系的“边索引”(edge index)
rel_pos_pt2pl = pos_pt[edge_index_pt2pl[0]] - pos_pl[edge_index_pt2pl[1]] #所有点的坐标减去各自所属的多边形的中心线的第一个点的坐标,产生相对位置向量
# rel_orient_pt2pl每个对象中点的方向同中心线第一个点的方向之间的角度差值,此处是点的方向同中心线第一个点的方向之间的角度差值
rel_orient_pt2pl = wrap_angle(orient_pt[edge_index_pt2pl[0]] - orient_pl[edge_index_pt2pl[1]]) #限制角度在
if self.input_dim == 2:
r_pt2pl = torch.stack(
[torch.norm(rel_pos_pt2pl[:, :2], p=2, dim=-1), #计算相对位置向量的长度,rel_pos_pt2pl存放每个点的方向
angle_between_2d_vectors(ctr_vector=orient_vector_pl[edge_index_pt2pl[1]], #orient_vector_pl 折线中的中心线的第一个点的方向向量
nbr_vector=rel_pos_pt2pl[:, :2]), # 折线中所有点同中心线第一个点之间形成的方向向量
rel_orient_pt2pl], dim=-1) #每个点的方向同中心线第一个点的方向之间的角度差值
elif self.input_dim == 3:
r_pt2pl = torch.stack(
[torch.norm(rel_pos_pt2pl[:, :2], p=2, dim=-1),
angle_between_2d_vectors(ctr_vector=orient_vector_pl[edge_index_pt2pl[1]],
nbr_vector=rel_pos_pt2pl[:, :2]),
rel_pos_pt2pl[:, -1],
rel_orient_pt2pl], dim=-1)
else:
raise ValueError('{} is not a valid dimension'.format(self.input_dim))
r_pt2pl = self.r_pt2pl_emb(continuous_inputs=r_pt2pl, categorical_embs=None)polygon之间的自注意力依赖于polygon之间相对状态的表示及编码
# 描述当前地图中多边形与多边形之间所属关系的“边索引”(edge index)
# 第一行是pred/succ/nbr等多边形的id,第二行是所从属的lane_segment的id,两者构成edge_index_pl2pl
edge_index_pl2pl = data['map_polygon', 'to', 'map_polygon']['edge_index']
# 基于节点的距离生成图的边
edge_index_pl2pl_radius = radius_graph(x=pos_pl[:, :2], r=self.pl2pl_radius, #pos_pl存放地图中所有lane_segment和cross_walk中心线的第一个点的坐标
batch=data['map_polygon']['batch'] if isinstance(data, Batch) else None,
loop=False, max_num_neighbors=300)
type_pl2pl = data['map_polygon', 'to', 'map_polygon']['type']
# edge_index_pl2pl_radius.size(1)是edge_index_pl2pl_radius的列数,表示建立的图的边的数量
# new_zeros 被用来创建一个与这些边数目一样长的全零张量,每个元素类型设置为 torch.uint8。
type_pl2pl_radius = type_pl2pl.new_zeros(edge_index_pl2pl_radius.size(1), dtype=torch.uint8)
# merge_edges用于合并来自多个源的图边及其相关属性(如边类型)
# 首先,使用 torch.cat(edge_indices, dim=1) 将所有的边索引张量沿着第一个维度(列)进行拼接,形成一个更大的张量,包含了所有的边。
# 然后,调用 coalesce 函数(很可能是PyTorch Geometric库中的函数)。
# coalesce 函数的作用是去重合并边。当图中存在多个连接相同节点的边时,coalesce 函数会把这些边合并为一条边,
# 并且根据 reduce 参数指定的方法来合并它们的属性。如果 reduce 参数是 'max',则对于每一对连接的节点,只保留具有最大属性值的那条边。
edge_index_pl2pl, type_pl2pl = merge_edges(edge_indices=[edge_index_pl2pl_radius, edge_index_pl2pl],
edge_attrs=[type_pl2pl_radius, type_pl2pl], reduce='max')
rel_pos_pl2pl = pos_pl[edge_index_pl2pl[0]] - pos_pl[edge_index_pl2pl[1]] #地图中对象(lane_segment或cross_walk)与对象之间的相对位置向量
rel_orient_pl2pl = wrap_angle(orient_pl[edge_index_pl2pl[0]] - orient_pl[edge_index_pl2pl[1]])
if self.input_dim == 2:
r_pl2pl = torch.stack(
[torch.norm(rel_pos_pl2pl[:, :2], p=2, dim=-1),
angle_between_2d_vectors(ctr_vector=orient_vector_pl[edge_index_pl2pl[1]],
nbr_vector=rel_pos_pl2pl[:, :2]),
rel_orient_pl2pl], dim=-1)
elif self.input_dim == 3:
r_pl2pl = torch.stack(
[torch.norm(rel_pos_pl2pl[:, :2], p=2, dim=-1),
angle_between_2d_vectors(ctr_vector=orient_vector_pl[edge_index_pl2pl[1]],
nbr_vector=rel_pos_pl2pl[:, :2]),
rel_pos_pl2pl[:, -1],
rel_orient_pl2pl], dim=-1)
else:
raise ValueError('{} is not a valid dimension'.format(self.input_dim))
r_pl2pl = self.r_pl2pl_emb(continuous_inputs=r_pl2pl, categorical_embs=[self.type_pl2pl_emb(type_pl2pl.long())])得到各个表示之后进行注意力操作
for i in range(self.num_layers):
x_pl = self.pt2pl_layers[i]((x_pt, x_pl), r_pt2pl, edge_index_pt2pl)
x_pl = self.pl2pl_layers[i](x_pl, r_pl2pl, edge_index_pl2pl)
x_pl = x_pl.repeat_interleave(repeats=self.num_historical_steps,
dim=0).reshape(-1, self.num_historical_steps, self.hidden_dim)4. 最后看agent-map之间的相对状态怎么表示
此处类似于agent-agent之间相对位置的表示及编码方式
以下是agent-map之间相对状态的表示及编码
# pytorch_geometric的radius方法,意在创建从一组源节点x(如代表智能体位置的pos_s)到一组目标节点y(如代表地图多边形的pos_pl)的边索引edge_index_pl2a。
# 这些边基于空间近邻原则建立,即当源节点和目标节点的距离小于或等于给定半径(r=self.pl2a_radius)时,它们之间就会建立边
edge_index_pl2a = radius(x=pos_s[:, :2], y=pos_pl[:, :2], r=self.pl2a_radius, batch_x=batch_s, batch_y=batch_pl,
max_num_neighbors=300)
edge_index_pl2a = edge_index_pl2a[:, mask_s[edge_index_pl2a[1]]] #过滤到不满足在指定时间步存在的agent同pl之间的边
rel_pos_pl2a = pos_pl[edge_index_pl2a[0]] - pos_s[edge_index_pl2a[1]] #计算agent同pl之间的相对位置向量
rel_orient_pl2a = wrap_angle(orient_pl[edge_index_pl2a[0]] - head_s[edge_index_pl2a[1]])
r_pl2a = torch.stack(
[torch.norm(rel_pos_pl2a[:, :2], p=2, dim=-1),
angle_between_2d_vectors(ctr_vector=head_vector_s[edge_index_pl2a[1]], nbr_vector=rel_pos_pl2a[:, :2]),
rel_orient_pl2a], dim=-1)
r_pl2a = self.r_pl2a_emb(continuous_inputs=r_pl2a, categorical_embs=None)encoder流程
下图是qcnet中encoder的结构图

如上图所示,编码器中需要进行temporal attn,agent-map attn以及social attn;由于特征编码时,均是在各自的local坐标系下,elements之间的相对位置关系丢失,因此在进行交叉注意力时,需要额外注入agent历史时刻之间,agent与map元素,agent与agent之间的相对位置信息,以下是代码
for i in range(self.num_layers):
x_a = x_a.reshape(-1, self.hidden_dim)
x_a = self.t_attn_layers[i](x_a, r_t, edge_index_t) #智能体历史轨迹特征提取
x_a = x_a.reshape(-1, self.num_historical_steps,
self.hidden_dim).transpose(0, 1).reshape(-1, self.hidden_dim)
x_a = self.pl2a_attn_layers[i]((map_enc['x_pl'].transpose(0, 1).reshape(-1, self.hidden_dim), x_a), r_pl2a,
edge_index_pl2a) #智能体同折线对象之间的特征提取
x_a = self.a2a_attn_layers[i](x_a, r_a2a, edge_index_a2a) #智能体之间社交特征提取
x_a = x_a.reshape(self.num_historical_steps, -1, self.hidden_dim).transpose(0, 1)propose+refine两阶段轨迹解码范式
下图是qcnet中的两阶段解码部分;
DETR范式的解码器利用多个可学习查询交叉参与场景编码并解码轨迹。然而,这些模型同其他无锚方法一样,存在训练不稳定和模式崩溃的问题
我们基于查询的解码器通过利用循环的无锚proposal模块来生成自适应轨迹锚点,然后使用基于锚点的模块进一步细化初始proposal,从而克服了这些限制。
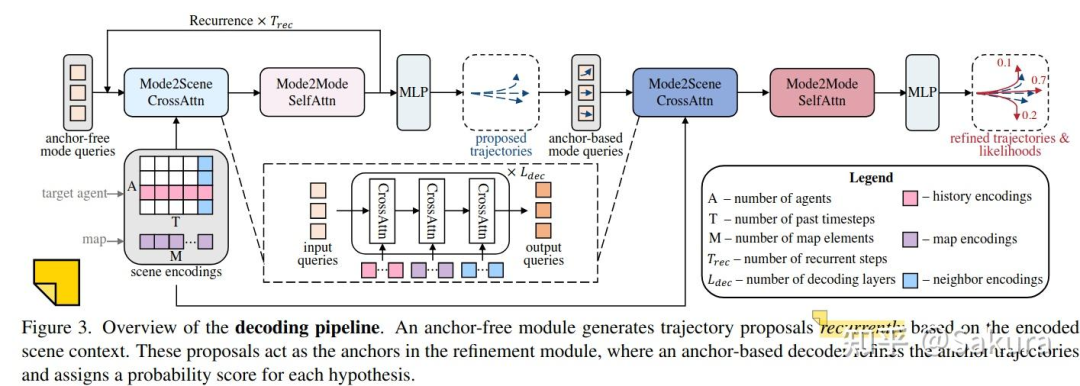
1.先看循环的无锚propose阶段
上图展示的非常清楚,mode2scene和mode2mode重复 次;mode2mode没啥好说的,就是mode query之间进行自注意力操作
mode2scene操作就是以input queries与target agent的时间维度上的嵌入,当前时刻的邻居agent的嵌入以及地图嵌入进行交叉注意力;
propose阶段有两点需要注意
第一个点,重复解码 次得到最终的propose轨迹;假设预测未来6s的轨迹,取 =3,也就是说每次循环生成20个点,即未来2s的轨迹;
第二个点,进行交叉注意力时需要为input queries假想一个其所处的坐标系,这个坐标系就是当前时刻agent的位置和航向构成的坐标系;
说人话就是指,由于我们需要解码出各个agent当前时刻坐标系下的未来轨迹,在进行交叉注意力时,类似于编码器中的操作,需要为key和value注入相对位置嵌入,通过各个scene elements的embedding到当前agent坐标系的相对状态产生相对位置嵌入
2.再看基于锚点的refine阶段
refine阶段的输入是propose阶段得到的proposal轨迹编码得到的anchor-based mode queries;这个编码是通过使用一个GRU来嵌入每个轨迹锚点,GRU最终的隐藏状态作为新的模式查询。
输送至refine模块中,refinement module预测偏差offset。此偏差是基于无锚估计得到的锚点/航路点
再看SmartRefine
SmartRefine: A Scenario-Adaptive Refinement Framework for Efficient Motion Prediction--CVPR 2024
smartrefine,顾名思义就是对qcnet中的refine部分进行了改进;下图是samrtrefine的结构图
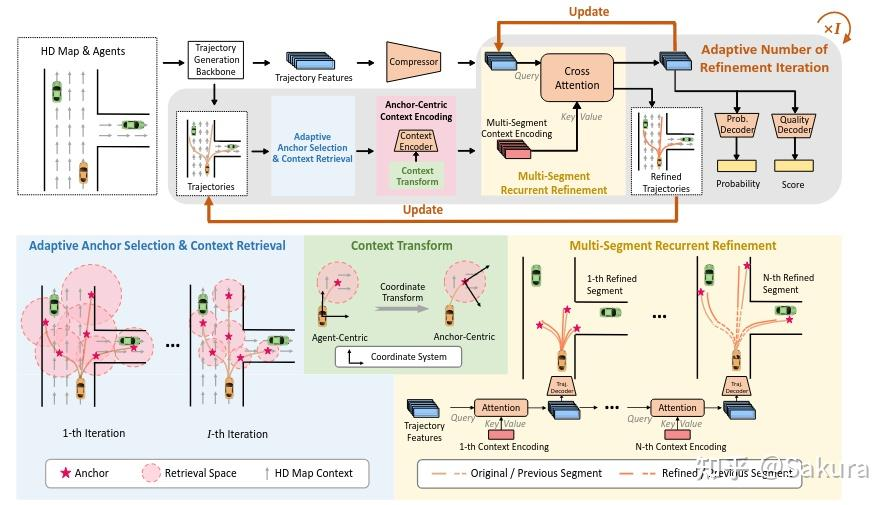
改进的点主要有以下几点
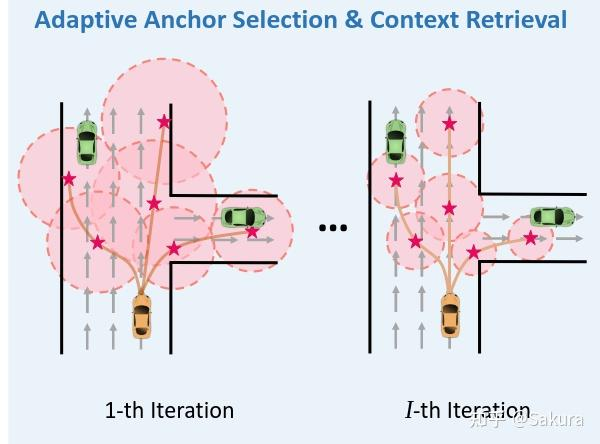
第一点,自适应anchor选择及上下文范围获取 Adaptive anchor/context selection
对于Anchor的选择
传统的refine中的锚轨迹是选取一整条proposal轨迹,这样计算量大;
因此选择将未来轨迹点进行切分,划分成一段一段的,每一段的终点作为锚点
对于上下文的获取
选择锚点周围固定半径或矩形来提取上下文的策略是次优的,针对这种情况,引入以下上下文信息动态获取范围的机制
一个anchor获取上下文的范围取决于两点,一个是迭代次数 ,另外一个是target agent在anchor处的速度;因此引入一个自适应检索策略,每个锚的检索范围R取决于细化迭代次数 和agent在锚点anchor周围的平均速度
motivation:相较于早期迭代,细粒度的上下文信息只用在后期的细化迭代中;早期细化迭代中不需要细粒度的上下文信息;速度越快,越需要更大范围的上下文
范围公式为 , 是任何随着迭代次数单调递减的函数即可,本文取 ,其中 是一个常数;
废话不多说总结此机制到底是干什么的
首先smartrefine一文中对refine过程的轨迹也进行分段的细化,类似于qcnet中的propose阶段的分阶段;同时,smartrefine中每次分段refine的时候,其各个锚点获取的上下文的范围是动态变化的,随着迭代次数的变化以及anchor附近agent速度而变化
第二点,anchor为中心的上下文编码 Anchor-Centric Context Encoding
先说motivation
回想一下,qcnet在refine阶段的整体流程;是通过GRU将proposal轨迹编码成新的mode queries;然后再走一遍mode2scene以及mode2mode
smartrefine中提到,qcnet在进行mode2scene时,keys和values还是源自于当前时刻的target agent周围的context,keys和values中所注入的相对位置信息还是周围scene elements相对于当前时刻agent坐标系的;
但是本文认为refine的过程,实际是希望沿着未来轨迹去捕获上下文的
再看smartrefine怎么做的
于是乎smartrefine在refine的过程中,将周围的上下文特征转换到对应锚点坐标系下
此处再细嗦一下:
为什么要转换到对应锚点坐标系下的需求是明确的;因为希望能获取更多的场景信息;假设只使用当前时刻target agent周围的context来细化,信息还是有限的;通过上一步,已经有对应的anchor点了,取anchor附近的context信息注入到模型,肯定是有用的;在这个过程中,需要将anchor周围的context信息转换到对应的锚点坐标系下,此处所说的转移,应该也是通过相对位置信息注入的形式,这个相对位置是anchor周围的context相对于anchor坐标系的
context中的地图信息好搞,但是周围agent的信息如何整?每个agent都有多个预测轨迹,难道取概率最大的轨迹编码,得到nbr agent的嵌入,再去进行处理嘛?
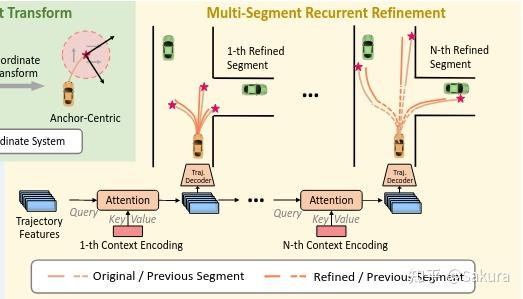
第三点,循环和多次迭代细化 Recurrent and Multi-Iteration Refinement
anchor-centric的上下文嵌入同轨迹特征嵌入相融合来细化轨迹
每条轨迹分为了N个片段segments,每个片段对应于一个锚anchor,细化每一条轨迹需要N次过程,完成整个N个片段的细化之后才算完成整体细化的一次迭代iteration
使用交叉注意力融合轨迹嵌入和上下文嵌入得到新的轨迹嵌入
新的轨迹嵌入用于预测轨迹段segment中waypoint的偏移
更新之后轨迹嵌入作为新的查询来优化下一个分段。在一次迭代中的N个步骤之后,整个轨迹都将被调整
第四点,自适应细化迭代次数 Adaptive Number of Refinement Iterations
细化迭代次数越多,模型表现越好;但同时带来了计算时间的增大,为了权衡两者,提出了一种自适应细化策略;
细化迭代的次数是根据当前的预测质量和剩余的潜在细化改进进行动态调整。
因此,smartrefine除了预测轨迹,轨迹对应的概率,同时还输出一个质量分数score
第i次iteration中quality score 的定义如下
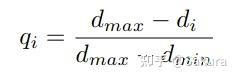
其中 是所有iteration中最大的预测误差; 是当前第i个iteration时的预测误差, 是所有iteration中最小的预测误差;上述分数的设计使得score位于0到1之间,使用绝对值 - 的话,不同场景差异比较大,不好
训练的时候,上面这个公式产生的各个iteration的质量分数作为gt,samrtrefine使用GRU处理所有多个trajectory features,然后再用MLP预测该iteration的分数
后续smartrefine中指定了几个策略,当满足指定的条件时,停止迭代,实现自适应refine iteration次数
最后最后,总结一下smartrefine,前面废话太多不看也行
这篇论文的出发点是简单直白的;将refine过程变得更加智能;
怎么变得智能呢?把refine变成多次多段;在每一段每一次的refine都智能
先说每段中的智能,论文对propose得到的轨迹进行分段,每一段进行refine,这称之为多段;
每段refine轨迹的智能体现在--自适应的context获取范围及anchor-centric的场景编码:
refine每段轨迹时,都有自适应的上下文获取范围,对应上图中红色圈圈的大小;上下文获取范围根据迭代次数以及agent在anchor附近的速度而定;同时,确定范围之后,获取的context信息都是基于anchor-centric编码的
每次refine轨迹的智能体现在--自适应的refine迭代次数
假设轨迹分成N段,完成N段的refine之后称之为一次iteration,这才是完整的一次refine;本文的模型还输出一个score,用以衡量该iteration的分数,当满足一定条件时,就不继续refine了;自适应的控制refine的次数,更加智能
最后看DONUT
DONUT: A Decoder-Only Model for Trajectory Prediction--ICCV 2025
这篇论文也是以qcnet为baseline进行改进,取得了argoverse v2上单agent轨迹预测的sota表现
论文中花了一节细细讲解了qcnet的结构,这是怕篇幅不够嘛哈哈
下图是DONUT的结构图
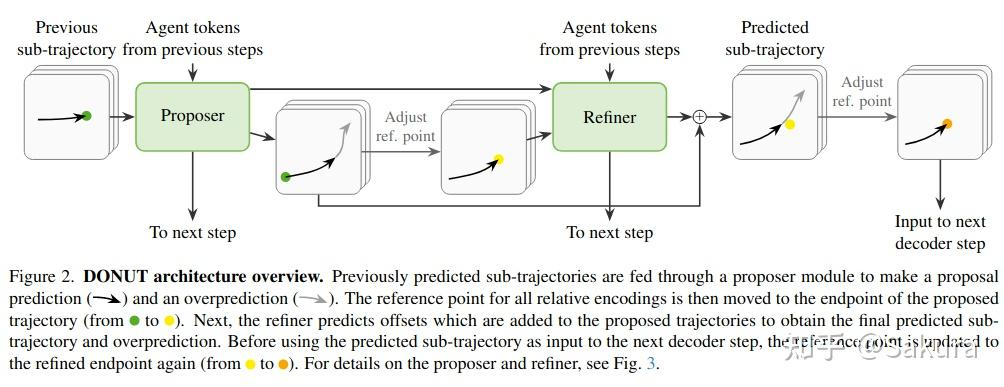
先说DONUT的整体结构
DONUT最核心的内容为,两个模块proposer,refiner以及一个overprediction机制;
通过上面的结构图可以看到,本文会将所有agent的轨迹划分为子轨迹 时间长度的子轨迹
从先前时间步的预测子轨迹开始 ,proposer用来预测下一个子轨迹片段,以及下下一个子轨迹片段(这个机制称之为overprediction)
将下一个子轨迹片段调整其参考点,输入至refiner中,得到细化的offset,同原始的proposal轨迹相加得到predicted sub-traj
上述过程说的比较笼统,具体再细看proposer和refiner的结构
接着说proposer和refiner的结构及流程
先说两个模块,proposer和refiner,这两个模块的结构一样,结构图如下
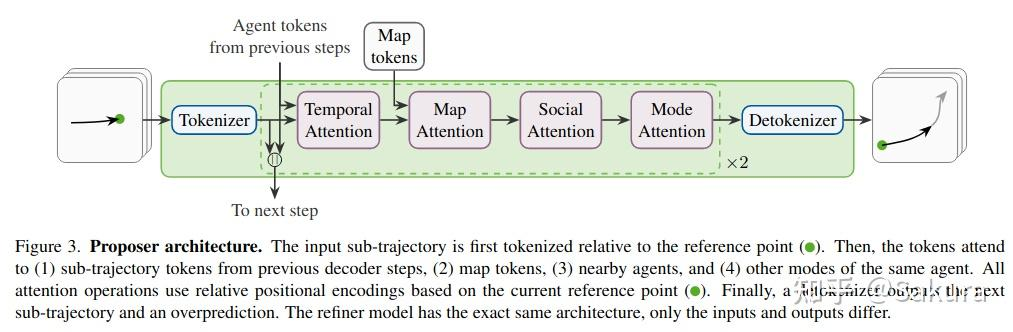
proposer的输入是 长度的轨迹片段;
tokenizer的过程:
输入的轨迹片段通过tokenizer进行编码,得到token;轨迹片段的状态包含位置,航向,运动向量以及速度,都是在轨迹片段端点endpoint的坐标系下的
计算每个时间步的fourier特征,将多个时间步的特征送入一个MLP中,把结果concat后送入一个MLP,结合agent type的embedding后得到 ;下图是tokenizer的细节

之后进行temporal attention,map-agent以及social attention,mode之间的自注意力操作,重复两次
temporal attn/map-agent attn/social attn的过程:
这个过程就类似qcnet;在进行attn时,keys和values需要注入的相对位置关系,是其他scene elements同ref point构成的坐标系之间的相对位置关系
proposer预测处一条sub-traj后,再输入进refiner前,会对该sub-traj调整参考点,将其中的状态调整到所预测的sub-traj端点所处的坐标系下;因此,在refiner中进行attn操作时,注入的相对位置信息是相对于这个新的ref point的坐标系
★
此处预测sub-traj并调整ref point和smartrefine中的操作一样,都是分阶段预测,同时调整到ref point坐标系下;
detokenizer的过程:
detokenizer用来解码轨迹,同时一个MLP输出overprediction的结果,同时输出一个logit,表示各个模式的概率
还有个问题,初始时proposer和refiner中Agent tokens from previous steps如何获取?
为了用历史tokens 初始化模型,本文将历史轨迹输入至proposer以及refiner中
由于唯一的目的是为时间注意力生成历史agent令牌,我们可以放弃预测。我们在单峰设置下运行,即K=1。在历史轨迹的最后一个时间步之后,我们沿着模态维度复制令牌。从这一点来看,该模型是多模态的。
★
此处没太懂;但笔者认为此处为了在初始时获得历史步的agent token,会将来自历史轨迹的sub-traj输送至只有temporal attn,map-agent attn以及social attn的proposer和refiner,然后在mode维度重复K次;
这是不是将历史轨迹走了一遍qcnet的encoder,然后得到了历史步的agent tokens
还有个问题,初始时proposer的输入 怎么来?
初始时还没有前一步预测多模态轨迹,此时 怎么来?难道是历史轨迹真值复制K份嘛
refiner的结构同proposer相同
最后看下实验结果和消融实验
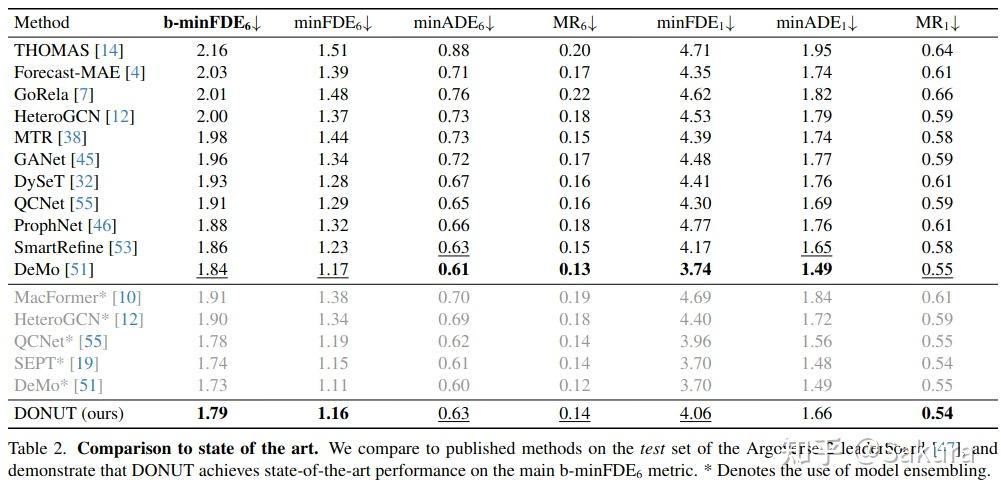
在非ensembling模型中,除了Demo之外,基本都能打过;和Demo互有胜负
消融实验
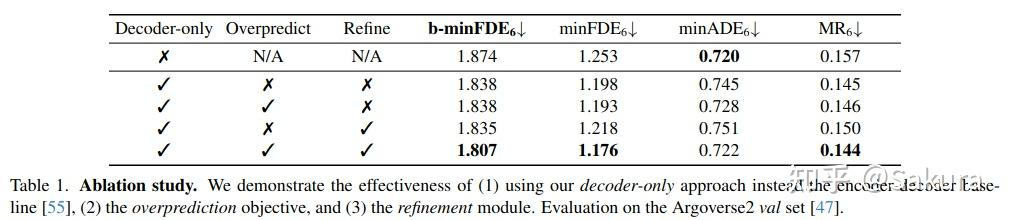
decoder-only的架构提升明显
自动驾驶之心
论文辅导来啦

自驾交流群来啦!
自动驾驶之心创建了近百个技术交流群,涉及大模型、VLA、端到端、数据闭环、自动标注、BEV、Occupancy、多模态融合感知、传感器标定、3DGS、世界模型、在线地图、轨迹预测、规划控制等方向!欢迎添加小助理微信邀请进群。

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









