




点击下方卡片,关注“3D视觉之心”公众号
第一时间获取3D视觉干货
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
三维点追踪当前问题
三维点追踪旨在从单目视频中恢复任意点的长期三维轨迹。作为一种通用的动态场景表示形式,该技术近年来在机器人、视频生成以及三维/四维重建等多种应用中展现出强大潜力。与参数化运动模型(如 SMPL、MANO、骨架或三维边界框)相比,它在各种真实场景中具有更强的灵活性与泛化能力,如图 1 所示。

现有的三维点追踪解决方案大量依赖于已经发展的低/中层视觉模型,例如光流与单目深度估计,并从二维点追踪模型中获益。其中,优化式方法通过针对每段给定的单目视频进行光流、深度与相机运动的联合提炼,取得了较为可观的效果,但由于其每个场景都需进行优化,因此计算成本高昂。SpatialTracker 提出了一种基于前馈模型的高效三维点追踪方法,之后的研究进一步探索了不同的架构设计与渲染约束以提升三维追踪质量。然而,这些前馈方案在训练数据的可扩展性方面受到限制,因为它们通常需要真实的三维轨迹作为监督信号,从而在真实自然场景下导致追踪质量下降。此外,忽略相机运动、物体运动与场景几何之间的内在关联会引发模块间误差的耦合与积累。
这些局限性启发了我们的核心观点:
对真实三维轨迹的依赖限制了现有前馈模型的可扩展性,因此需要设计能够泛化到多样化、弱监督数据源的方法;
缺乏对场景几何、相机运动与物体运动的联合建模会导致误差复合与性能退化,说明有必要对这些运动成分进行解耦并显式建模。
为了解决上述问题,我们将三维点追踪分解为三个独立的部分:视频深度、相机自运动(ego motion)与物体运动,并将它们整合到一个完全可微的流程中,以支持在多源异构数据上的可扩展联合训练。
SpatialTrackerV2 提出了前端-后端架构。前端包括一个视频深度估计器与相机位姿初始化器,改编自典型的单目深度预测框架,并引入了基于注意力机制的时序信息编码。所预测的深度图与相机位姿随后被送入尺度-偏移估计模块,以确保深度与运动预测之间的一致性。后端包含我们提出的联合运动优化模块,该模块以视频深度与粗略的相机轨迹为输入,迭代估计二维与三维轨迹,以及轨迹对应的动态性与可见性评分,从而实现高效的捆绑优化过程以更新相机姿态。该模块的核心是新颖的 SyncFormer 模块,其在两个分支中分别建模二维与三维之间的相关性,并通过多个交叉注意力层进行连接。这一设计减弱了二维与三维特征间的干扰,使模型能够分别在图像(UV)空间与相机坐标空间中更新表示。此外,借助该双分支结构,捆绑优化可以有效地同时优化相机位姿以及二维和三维轨迹。
论文名称:SpatialTrackerV2: 3D Point Tracking Made Easy
demo体验链接:https://huggingface.co/spaces/Yuxihenry/SpatialTrackerV2
这一统一且可微的流程使得在多样化数据集上实现大规模训练成为可能。对于带有相机姿态的 RGB-D 数据集,我们通过静态点的深度与姿态一致性约束进行三维追踪训练,而动态点则自然参与到优化中。对于仅提供相机姿态但缺乏深度信息的视频数据集,我们利用相机姿态与二维、三维点追踪之间的一致性来驱动模型优化。基于该框架,我们成功地在 17 个数据集上实现了整个流程的扩展训练。
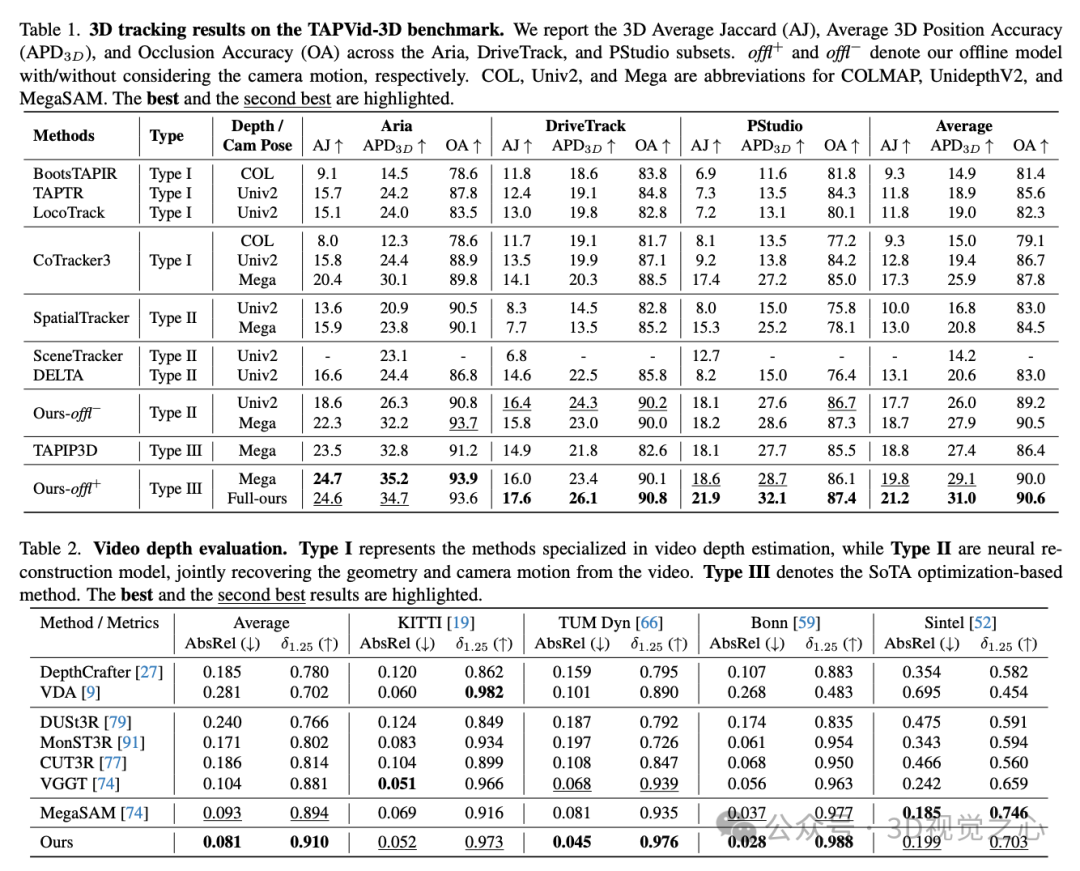
在 TAPVid-3D 基准上的评估表明,我们的方法在三维点追踪方面设立了新的 SOTA(state-of-the-art),达到了 21.2 的 AJ 和 31.0 的 APD3D,相较 DELTA 提升了 61.8% 与 50.5%。此外,大量关于动态重建的实验也展示了我们在视频深度与相机位姿一致性估计方面的优势。具体而言,SpatialTrackerV2 在大多数视频深度数据集上超过了最好的动态重建方法 MegaSAM,在多个相机姿态基准上也获得了相当的结果,推理速度更是快了约 50 倍。
具体方法
如图 3 所示。我们的模型采用前端-后端结构,前端部分生成每帧的单目深度估计和初始相机位姿估计。后端部分执行联合三维点追踪与捆绑优化,以微调深度和相机位姿估计。
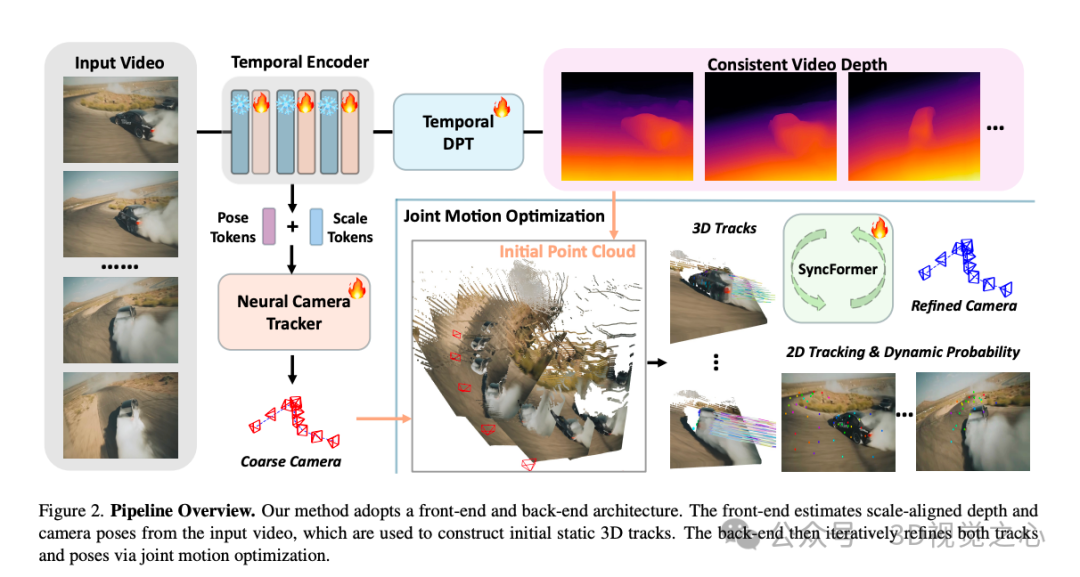
视频深度和相机初始化
我们使用一个前馈网络从每一帧图像中预测单目深度,并使用一个两帧姿态估计器预测相邻帧之间的相机相对姿态。在训练过程中,我们使用一个尺度-偏移(scale-offset)回归模块将深度图归一化为和相机姿态一致的尺度。对于每个图像帧 ,我们预测其深度 以及其相对于参考帧 的姿态 。
我们进一步在训练中加入约束,以对单目深度图中的尺度歧义进行校正。对于参考帧 ,我们将其所有像素投影为三维点云 ,然后使用相机姿态将其投影到帧 上:
通过投影这些三维点并与 中的深度预测结果比较,我们定义一个一致性损失,用于训练尺度-偏移模块,使深度与姿态在尺度上保持一致。
联合三维点追踪与优化
我们的目标是估计来自视频的点轨迹在三维空间中的运动。为此,我们将三维追踪问题建模为联合优化问题,优化变量包括相机姿态、二维轨迹、三维轨迹、点的可见性与动态性分数。我们设计了一个前馈模块用于初始估计,并引入可微的捆绑优化器对其进行迭代优化。
初始三维轨迹估计
给定相机内参 、每帧的深度图 、以及像素级二维轨迹 ,我们可以通过以下方式将像素投影为三维空间中的点:
使用估计的姿态 ,我们将三维点变换到参考坐标系:
我们使用所有帧的投影结果的平均值作为初始三维轨迹估计:
动态性与可见性估计
为了建模点的动态性,我们引入一个动态性分数 ,表示点 的运动程度。我们还引入一个可见性分数 ,表示点 在帧 中的可见程度。我们使用一个轻量级网络从图像特征和几何一致性中预测这些分数,并用它们作为加权项,用于下游三维轨迹优化。
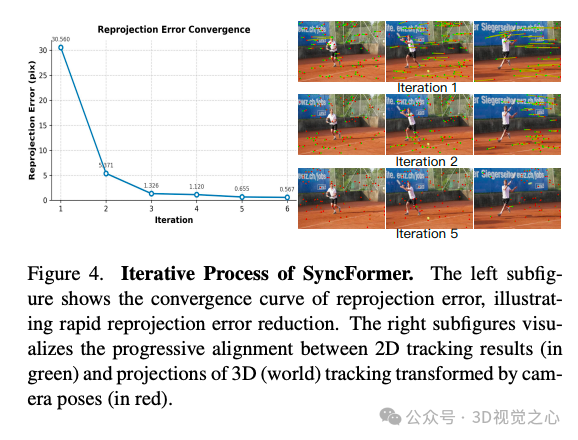
捆绑优化
我们定义总损失函数用于捆绑优化,包含多项:
重投影误差(2D):
其中 表示透视投影。
几何一致性损失(3D):
动态性约束损失:
正则项:
最终的总损失为:
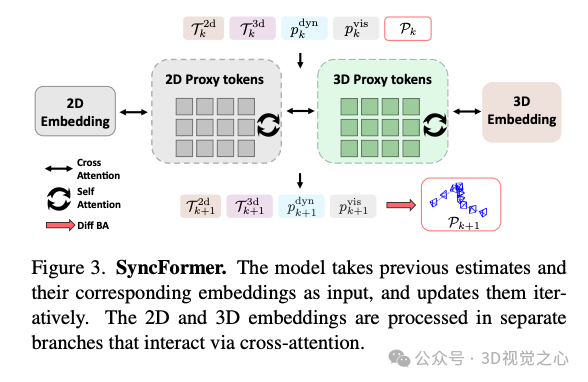
SyncFormer 模块
为了提升特征之间的一致性建模能力,我们提出了 SyncFormer,一个具有二维-三维双分支结构的交叉注意力模块。在该模块中,二维分支处理像素级轨迹特征,三维分支处理相应三维轨迹特征。两个分支通过交叉注意力进行同步信息传递,实现更有效的融合与更新。该模块被用于多次迭代优化中,在每次优化后更新三维轨迹与相机位姿。
实验效果

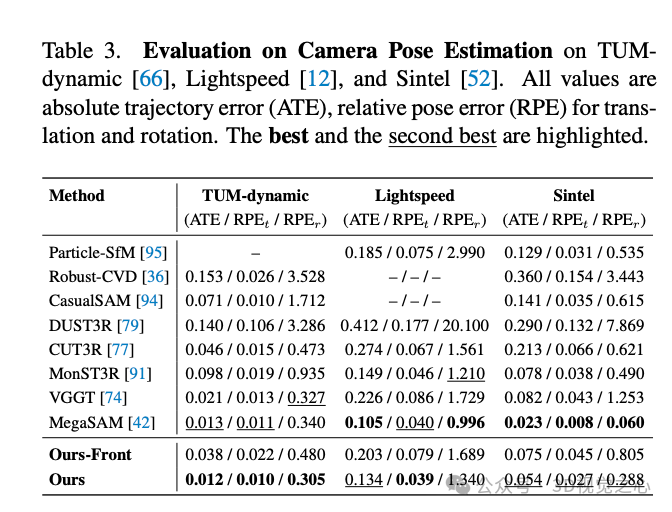
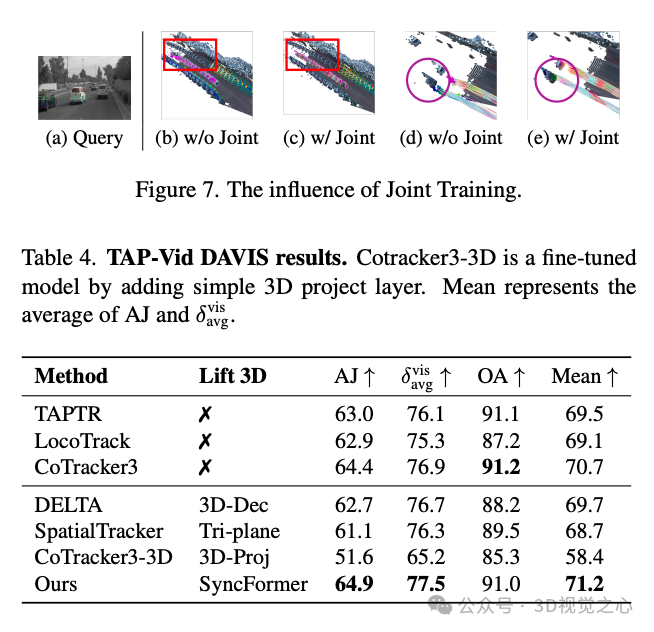
总结一下
SpatialTrackerV2是一个面向单目视频的前馈式、可扩展且性能领先的三维点追踪方法。该方法基于对运动与场景几何中常见的低/中层视觉表征的深入探索,将一致的场景几何、相机运动和逐像素三维运动统一到一个完全可微的端到端流程中。SpatialTrackerV2 能够从单目视频中精确重建三维轨迹,在公开基准测试中取得了优异的定量成绩,并在随手拍摄的互联网视频中表现出良好的鲁棒性。我们认为 SpatialTrackerV2 为真实世界中的运动理解奠定了坚实基础,并通过大规模视觉数据的探索,推动我们朝向“物理智能”迈出了一步。
【3D视觉之心】技术交流群
3D视觉之心是面向3D视觉感知方向相关的交流社区,由业内顶尖的3D视觉团队创办!聚焦三维重建、Nerf、点云处理、视觉SLAM、激光SLAM、多传感器标定、多传感器融合、深度估计、摄影几何、求职交流等方向。扫码添加小助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

扫码添加小助理进群
【具身智能之心】知识星球
具身智能之心知识星球是国内首个具身智能开发者社区,也是最专业最大的交流平台,近1500人。主要关注具身智能相关的数据集、开源项目、具身仿真平台、VLA、VLN、Diffusion Policy、强化学习、具身智能感知定位、机器臂抓取、姿态估计、策略学习、轮式+机械臂、双足机器人、四足机器人、大模型部署、端到端、规划控制等方向。星球内部为大家汇总了近40+开源项目、近60+具身智能相关数据集、行业主流具身仿真平台、各类学习路线等,涉及当前具身所有主流方向。
扫码加入星球,享受以下专有服务:
1. 第一时间掌握具身智能相关的学术进展、工业落地应用;
2. 和行业大佬一起交流工作与求职相关的问题;
3. 优良的学习交流环境,能结识更多同行业的伙伴;
4. 具身智能相关工作岗位推荐,第一时间对接企业;
5. 行业机会挖掘,投资与项目对接;



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









