




点击下方卡片,关注“自动驾驶之心”公众号
今天自动驾驶之心为大家分享上海期智研究院&清华大学赵行老师团队最新的工作!BEV-VAE:实现自动驾驶环视图像精准生成与操控。如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
论文作者 | Zeming Chen等
编辑 | 自动驾驶之心
论文链接: https://arxiv.org/abs/2507.00707
代码仓库 (Github): https://github.com/Czm369/bev-vae

摘要
在自动驾驶中,多视角图像生成任务需要在不同相机视角下实现对三维场景的一致理解。然而,大多数现有方法将其简化为二维图像集合的生成问题,缺乏对三维结构的显式建模。我们认为,对于自动驾驶场景的生成任务,结构化表示至关重要。为此,本文提出 BEV-VAE 方法,实现具有空间一致性与可控性的多视角图像生成。BEV-VAE 首先训练一个多视角图像的变分自编码器(VAE),以学习一个紧凑且统一的鸟瞰视角(BEV)隐变量空间;随后,在该隐变量空间中训练 Diffusion Transformer,用于生成空间一致的多视角图像。BEV-VAE 支持根据任意相机配置生成对应视角的图像,并结合三维布局信息进行控制。在 nuScenes 和 Argoverse 2(AV2)数据集上的实验表明,BEV-VAE 在多视角图像的重建与生成任务中均具备优异性能。
动机
1. 一次性数据采集 vs. 可控场景生成
自动驾驶采集到的数据都是一次性的、不可控的,这让我们很难研究“如果场景稍有不同,车辆会怎么开”。比如,把路边停着的车从图像里去掉,可能对驾驶行为没什么影响;但如果去掉正前方慢慢开的车,系统的决策可能就完全变了。可惜的是,在现实中我们没办法对同一个场景采很多个“稍微不同版本”的数据,这让端到端自动驾驶模型在学习这类微妙差异时很吃力。而生成模型正好能解决这个问题——在不改变整体场景的情况下,低成本地修改局部内容,比如移除或添加一辆车,从而帮助模型更高效地学习各种驾驶策略。
2. 图像为单位 vs. 场景为单位
多视角图像本质上是对同一个场景的不同视角观察——不管相机有几个,放在哪儿,它们描述的都是同一个三维世界。因此,我们认为生成模型的训练单位应该是“场景”,而不是“图像”。然而,现有的世界模型大多仍在图像的隐空间里建模,不仅要处理视角之间的空间对应关系,还要同时建模时间维度上的自车运动,以及不同交通参与者之间的动态交互。多个任务耦合在一起,导致训练目标模糊,模型难以泛化。更麻烦的是,不同车辆搭载的相机数量和位置各不相同,导致训练好的模型很难迁移到另一套感知系统上。

图1. 两种多视角图像生成范式对比。
(a) 图像隐空间生成依赖于三维物体的二维投影为条件来指导图像隐变量的生成,通过交叉视图注意力机制保证空间一致性。
(b) BEV 隐空间生成以3D占用为条件来指导 BEV 隐变量的生成,所有视角的图像都从同一个BEV隐变量中解码,自然地保持空间一致性,并且可以通过调整相机姿势实现新视角图像的生成。
框架设计
BEV-VAE 由基于 Transformer 结构的编码器 、解码器 和 StyleGAN 判别器 组成。编码器 包含图像编码器、场景编码器和状态编码器,用于将多视角图像编码为一个高斯分布,并通过重参数化从中采样状态特征。解码器 包括状态解码器、场景解码器和图像解码器,负责从状态特征中重建多视角图像,确保不同视角下图像之间的空间一致性。判别器 用于区分真实图像和重建图像,并通过对抗损失对解码器 进行训练指导,使重建结果更加真实自然。编码器 和解码器 通过KL散度损失、重建损失和对抗损失联合训练。此外,DiT(Diffusion Transformer)在BEV隐变量空间中执行去噪操作,从而实现高质量的多视角图像生成。
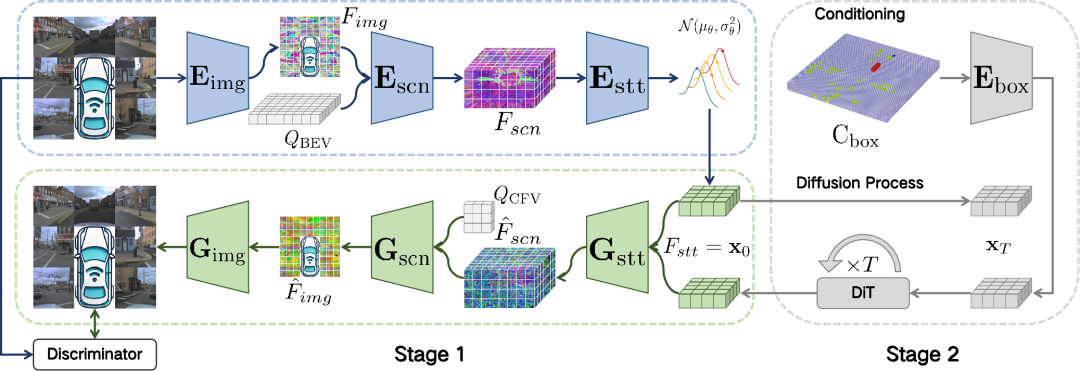
图2. BEV-VAE 总体架构包含两个阶段:
自监督训练阶段(Stage 1):多视角图像通过编码器映射为结构化的 BEV 隐变量,再解码回原视角的图像,保证空间一致性与语义完整性;
扩散生成阶段(Stage 2):使用 DiT 模型在 BEV 隐变量空间中建模噪声,通过Classifier-Free Guidance 生成 BEV 隐变量,再解码为多视角图像,可以实现任意相机配置下的多视角图像的生成。
多视角重建与新视角合成
多视角图像重建
与 SD-VAE (Stable Diffusion 所用的 AutoencoderKL)将单张 图像压缩为 的图像隐变量不同,BEV-VAE 将来自多个相机视角的图像编码为一个共享的 BEV 隐变量,从而捕获更丰富的空间结构与语义信息。由于该隐变量融合了多视角内容并显式建模三维空间关系,因此显然需要满足 ,以承载更大的信息容量。

在AV2 数据集上的不同隐变量维度下的多视角图像重建的对比。第1行为验证图像,第2-5行为隐变量维数为4、8、16、32的重构图像。在更高的维度下,重建图像能更准确地还原细节,例如白色框中的井盖。
新视角图像生成
通过仅旋转相机姿态即可在BEV隐空间中实现新视角图像生成,无需重新建模或额外训练,验证了空间建模的稳定性与表达能力。第1行显示验证集的图像,后面是显示所有摄像机分别向旋转15°到-15°的重建图像。其中,隐变量维度设置为32。

在 nuScenes 数据集上的多视角重建和新视角生成。

在 AV2 数据集上的多视角重建和新视角生成。
多视角图像生成与对象编辑
BEV-VAE支持对场景中对象的细粒度编辑,移除车辆后生成结果无明显空洞,表明模型成功学习到场景的三维结构与完整语义。 以下两张图中,第1行表示来自验证集的真实图像。第2行显示了从相应的3D边界框生成的图像。后面是移除特定车辆后生成的图像,移除的车辆用数字标签表示。注意:相同的3D标注框可能在不同的生成图像中产生外表不同的对象。

在 nuScenes 数据集上的多视角图像生成。

在 AV2 数据集上的多视角图像生成。
实验结果与消融分析
我们使用 nuScenes 和 Argoverse 2(AV2)两个多相机的自动驾驶数据集对 BEV-VAE 进行训练与评估。这两个数据集提供时间戳同步的多视角图像与对应的三维标注框。
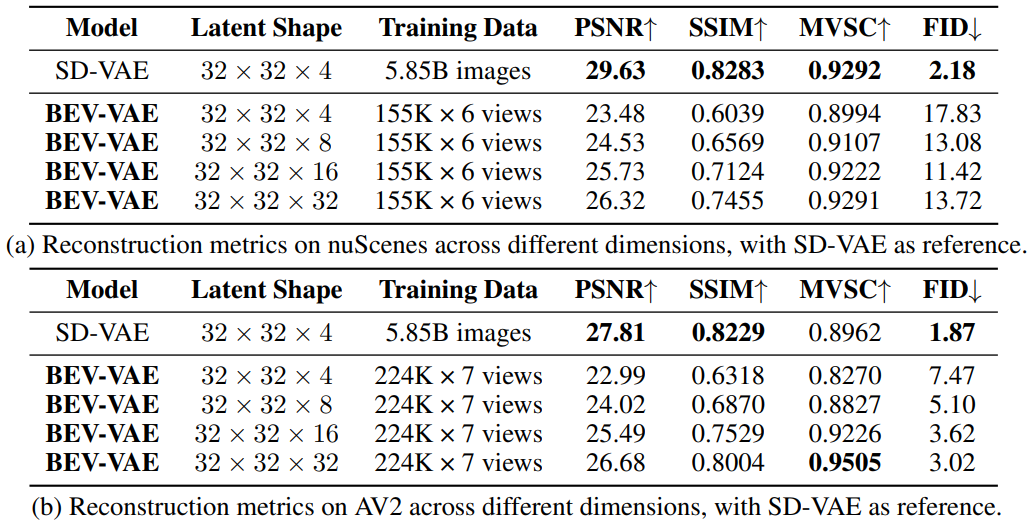
表1. 不同隐变量维度的 BEV-VAE 与 SD-VAE 在多视角图像重建中的比较:BEV-VAE 通过将多视角图像编码为统一的BEV隐变量并解码回图像来进行空间建模,而经过58.5亿张图像训练的SD-VAE仅作为图像重建的参考而不是直接基线。

表2. 不同指导尺度下的生成质量对比:指导尺度与隐变量维度共同影响多视角图像生成质量。
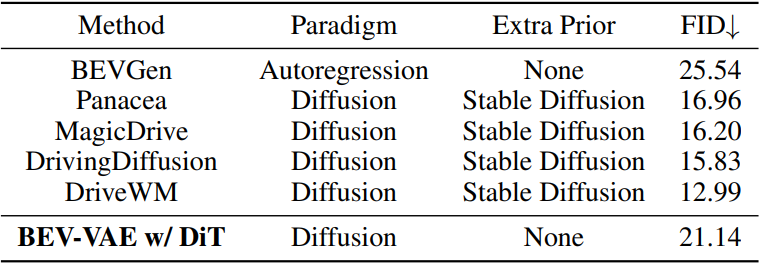
表3. 在 nuScenes 上的基准对比:BEV-VAE w/ DiT 显著缩小了从头训练与微调方法之间的性能差距
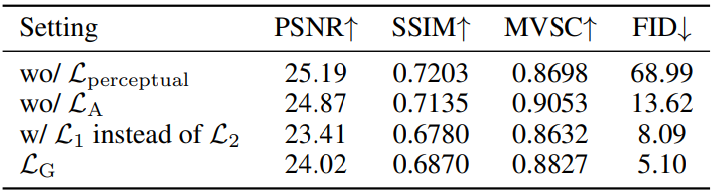
表4. 在 AV2 上的重建损失消融实验:隐变量维度为8时,不同损失组合对生成质量的影响,进一步验证了 BEV 损失函数设计的有效性。
结论:BEV-VAE的优势与可扩展性
✅ 结构化表示:学习统一的 BEV 隐变量空间,具备多视角图像的完整语义和空间结构;
✅ 模型解耦:空间建模与生成建模完全分离,简化世界模型构建;
✅ 支持任意视角配置:天然兼容多种相机数量与位姿,具备跨平台通用性;
✅ 符合数据规模规律(Scale Law):AV2 数据量仅为 nuScenes 的 1.5 倍,重建和生成的效果却大幅提升;
✅ 零成本迁移:只需将原有图像 VAE 替换为 BEV-VAE,Diffusion 系列算法即可直接用于生成空间一致的多视角图像。
BEV-VAE 提供了统一的 BEV 隐变量空间,完整地编码了多视角图像的场景语义与空间结构,显著降低生成模型在自动驾驶场景中的应用门槛,使生成模型领域的研究者能够以更低成本、更高效率参与自动驾驶世界模型的构建与拓展。
自动驾驶之心
论文辅导来啦

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 1519
1519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









