



点击下方卡片,关注“3D视觉之心”公众号
第一时间获取3D视觉干货
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
多模态大模型正在成为通向通用人工智能的关键路径,而空间理解能力则是其认知能力的重要组成部分。尤其在视频这一动态媒介中,如何从纯2D输入中挖掘出三维结构信息,已成为视频大模型迈向更高智能的关键挑战。现有模型多依赖于附加的3D或2.5D数据(如点云、深度图)来弥补空间感知的缺失,然而这类数据在真实世界中难以获取,限制了模型的应用广度。
受视觉几何基础模型中结构先验的启发,清华大学团队提出了Spatial-MLLM,一种无需3D输入即可进行空间推理的新型视频大模型架构。该方法通过引入结构感知的空间编码器与传统语义编码器并行融合,显著增强了模型对场景几何的理解能力,并辅以高效的空间感知帧采样策略,从有限的视频帧中提取最具空间价值的信息。经过测试评估,Spatial-MLLM在VSI-Bench、ScanQA、SQA3D等多项空间理解基准中取得了领先性能。

论文标题:Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence
Arxiv地址: https://arxiv.org/abs/2505.23747
项目主页: https://diankun-wu.github.io/Spatial-MLLM/
Github仓库: https://github.com/diankun-wu/Spatial-MLLM
动机
在现有的多模态视频大模型中,视觉编码器往往预训练于图文对数据,因此非常擅长捕捉语义层级的信息。但这种训练范式也导致模型难以从2D图像中恢复出完整的三维结构,限制了其在空间理解任务中的表现。而最近的视觉几何基础模型(如VGGT)与多模态大模型的视觉编码器刚好构成互补关系:其主要在像素-点云对上训练,可以捕捉2D输入中的空间结构信息。Spatial-MLLM从这个角度出发,设计了双编码器结构,分别从视觉语义与空间结构两个维度提取信息,再通过轻量连接器融合成统一token序列。这种设计既保留了语义信息的完整性,又通过视觉几何模型弥补了空间结构感知的短板,使模型能够在无深度图或点云等额外3D数据的前提下,实现良好的空间感知与推理能力。其整体示意图如下所示:
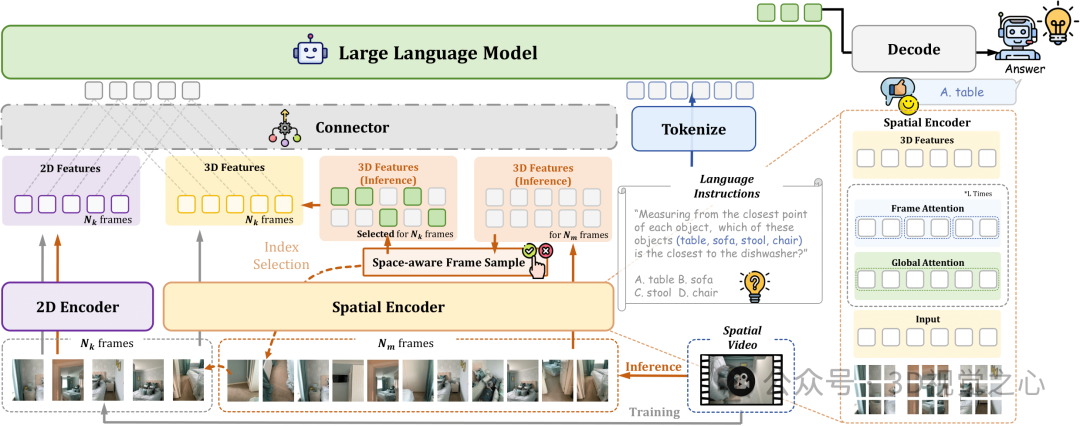
模型架构
Spatial-MLLM主要由以下四个部分组成:
语义编码器(2D Encoder): 使用现有的视频多模态模型(例如Qwen2.5-VL)的视觉编码器,负责提取视频帧中的高层语义信息(如物体类别、场景描述等)。
空间编码器(Spatial Encoder):采用预训练的视觉几何模型(例如VGGT),其通过全局与局部自注意力机制,可以捕获视频序列中的隐含三维空间结构信息。
特征融合连接器(Connector):用简单的MLP结构,将语义编码器和空间编码器分别提取出的特征进行融合,得到统一的视觉特征表示,从而为大语言模型(LLM)提供综合的空间和语义信息。
大语言模型(LLM Backbone):
图像分别通过语义编码器和空间编码器提取特征,由Connector模块融合为统一的视觉Token,与文本Token一起输入大语言模型Backbone中进行推理,得到最后的结果。
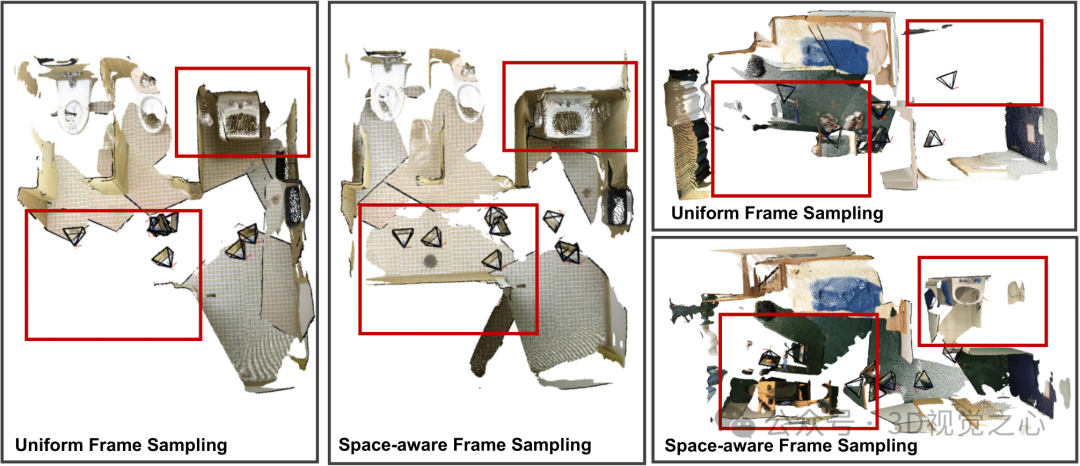
空间感知帧采样策略
基于视频的MLLM在实际部署中受限于GPU显存大小,一般只能使用有限的视频帧作为输入(如8~32帧)。常见的均匀采样策略虽然有效,但对空间推理场景往往不是最优。为此,论文设计了一种空间感知的帧采样策略,可以采样空间覆盖尽可能大的一组帧作为模型输入。其流程如下:
首先从完整视频序列中均匀采样一个较大的帧子集。
然后利用空间编码器对这些帧提取3D空间特征,并解码出每帧对应的深度信息与摄像机位姿,进而计算出每帧像素覆盖的体素集合。
将选择帧的问题转化为最大化场景空间体素覆盖率的优化问题,并采用贪婪算法进行快速求解,从而选出空间覆盖最大的视频帧集合。
下图展示了空间感知帧采样策略的可视化结果。这一方法使得即使在有限的帧数条件下,模型也能更有效地感知和推理场景中的空间结构。
数据集与训练流程
作者构建了名为Spatial-MLLM-120k的空间推理问答数据集。该数据集包含以下几种数据:
来自ScanQA、SQA3D等公开数据集的训练数据。
作者自行构造的基于ScanNet场景的空间推理数据。
Spatial-MLLM的训练流程包括两个阶段:
阶段一:监督微调(Supervised Fine-tuning, SFT)在构建好的数据集上,冻结2D与空间编码器的权重,训练连接器与语言模型,使模型能够有效地整合语义与空间特征。
阶段二:冷启动(Cold Start)和强化学习(GRPO)为了让模型输出正确的推理格式,论文首先对模型进行冷启动训练。然后采用分组相对策略优化算法(GRPO算法),对模型进行强化学习训练,进一步增强模型长链空间推理能力。
训练过程中关键参数的曲线如下图所示:

实验
作者进行了大量的实验来验证Spatial-MLLM的有效性,主要包括以下三个基准:
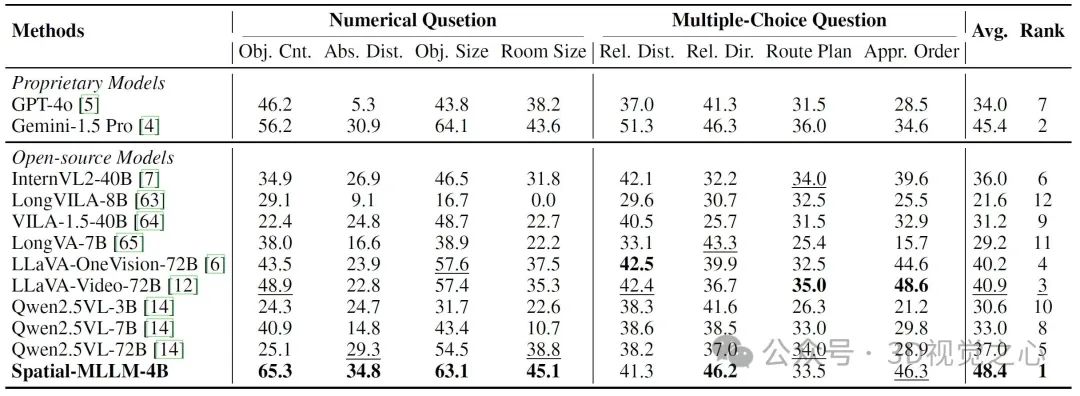
VSI-Bench(视觉空间智能基准):该任务涵盖空间配置、测量估计和时空推理等8种任务类型。Spatial-MLLM在此基准上表现突出,整体性能显著超越其他开源和商业MLLM(包括GPT-4o和Gemini-1.5 Pro),表现达到了当前最优。
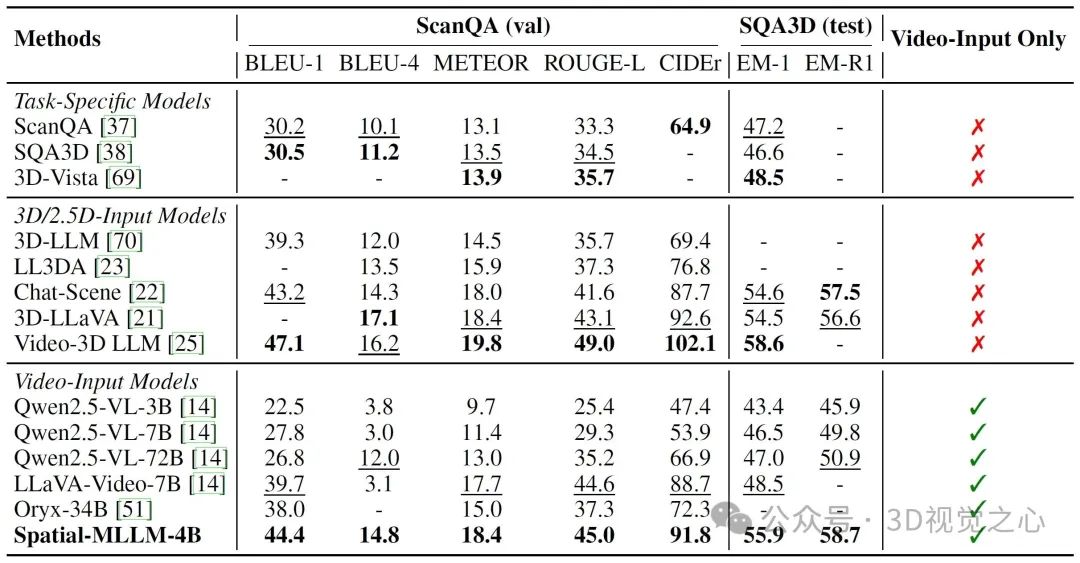
ScanQA和SQA3D(三维场景问答基准):这两个基准主要考察模型对场景内物体空间关系的理解和回答能力。实验结果显示Spatial-MLLM在仅输入视频数据(不需要额外3D信息)的情况下,大幅领先于其他视频输入的模型,甚至接近或超过了需要3D信息输入的专用模型的性能。
eval_scanqa_sqa3d
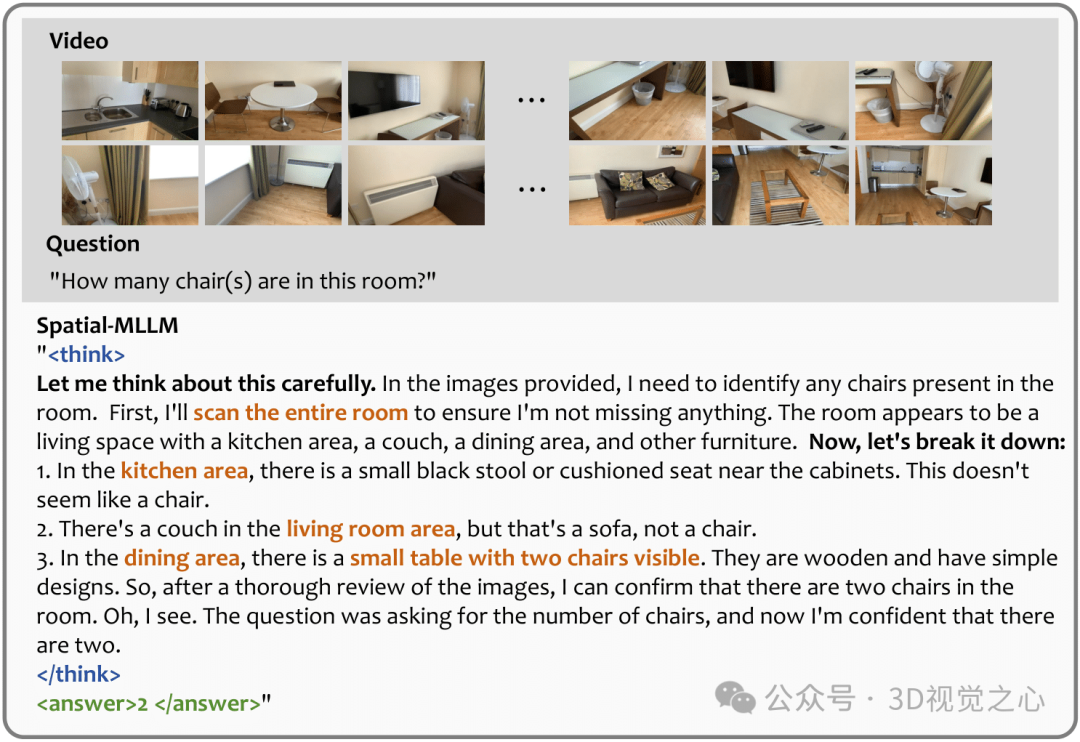
Spatial-MLLM的一些空间推理可视化如下:



【3D视觉之心】技术交流群
3D视觉之心是面向3D视觉感知方向相关的交流社区,由业内顶尖的3D视觉团队创办!聚焦三维重建、Nerf、点云处理、视觉SLAM、激光SLAM、多传感器标定、多传感器融合、深度估计、摄影几何、求职交流等方向。扫码添加小助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

扫码添加小助理进群
【具身智能之心】知识星球
具身智能之心知识星球是国内首个具身智能开发者社区,也是最专业最大的交流平台,近1500人。主要关注具身智能相关的数据集、开源项目、具身仿真平台、VLA、VLN、Diffusion Policy、强化学习、具身智能感知定位、机器臂抓取、姿态估计、策略学习、轮式+机械臂、双足机器人、四足机器人、大模型部署、端到端、规划控制等方向。星球内部为大家汇总了近40+开源项目、近60+具身智能相关数据集、行业主流具身仿真平台、各类学习路线等,涉及当前具身所有主流方向。
扫码加入星球,享受以下专有服务:
1. 第一时间掌握具身智能相关的学术进展、工业落地应用;
2. 和行业大佬一起交流工作与求职相关的问题;
3. 优良的学习交流环境,能结识更多同行业的伙伴;
4. 具身智能相关工作岗位推荐,第一时间对接企业;
5. 行业机会挖掘,投资与项目对接;


















 1639
1639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









