 港中文DriveGEN提升自动驾驶视觉3D感知鲁棒性
港中文DriveGEN提升自动驾驶视觉3D感知鲁棒性




点击下方卡片,关注“自动驾驶之心”公众号
今天自动驾驶之心为大家分享港中文(深圳)团队最新的工作!DriveGEN:免训练扩散模型生成逼真3D驾驶场景,让自动驾驶无惧极端天气!如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
>>点击进入→自动驾驶之心『3D目标检测』技术交流群
论文作者 | Hongbin Lin等
编辑 | 自动驾驶之心
|导读|
随着新能源汽车产业的持续发展,智能驾驶辅助技术的应用越来越广泛。其中,基于纯视觉的自动驾驶方案只需使用多视角图像进行环境感知与分析,具有成本低、效率高的优势,因而备受关注。然而在实际应用中,视觉感知模型的泛化能力至关重要。来自香港中文大学(深圳)等单位的学者们提出了一种名为DriveGEN的无训练自动驾驶图像可控生成方法。该方法无需额外训练生成模型,即可实现训练图像数据的可控扩充,从而以较低的计算资源成本提升三维检测模型的鲁棒性。DriveGEN通过"自注意力物体原型提取"和"原型引导生成"的两阶段策略,在准确保留三维物体信息的前提下,将训练数据扩展至各类现实但难以采集的场景(如恶劣天气),目前代码已开源。

论文链接:https://www.arxiv.org/abs/2503.11122
代码链接:https://github.com/Hongbin98/DriveGEN
任务背景
据路透社消息[1],作为自动驾驶行业领先者的Waymo于2025年5月14日宣布召回超过1200辆自动驾驶车辆,原因在于算法在识别链条、闸门等道路障碍物时存在潜在风险,自动驾驶再次陷入安全风波。
诸如此类事件的背后共同折射出一个深层的技术难题:即使是最先进的自动驾驶系统,在面对真实世界场景时,仍然需要着重考虑系统的鲁棒性。一条普通的施工链条、一个临时设置的闸门,就可能成为算法的盲区。
自动驾驶中视觉感知模型的鲁棒性至关重要
不难看出,视觉感知模型的鲁棒性直接影响系统能否可靠地理解复杂的环境并做出安全的决策,其对驾驶安全至关重要。然而,传统的机器学习方法通常依赖大量预先收集的训练数据,而实际部署环境中的数据分布往往与训练时不同,这种现象称为"分布偏移"。通俗地说,就像学生备考时只复习了往年的题型,而正式考试却出了很多新题,导致很难发挥出应有水平。在自动驾驶中,分布偏移可能表现为天气状况与光照条件的变化,或因车辆行驶时的摄像头抖动导致的画面模糊等情况。这些常见但棘手的分布偏移问题会严重影响视觉感知模型的性能,往往导致性能显著下降,严重制约了其在现实场景的广泛部署与应用。
自动驾驶中分布偏移的解决难点是什么?
要解决分布偏移问题并不容易,因为用于训练的数据大部分来自理想的天气状况(如晴天),而那些特殊天气(如大雪、大雾、沙尘暴)的数据很难大量获得,采集起来成本高,标注起来也费时费力。实际上,我们在自然环境下就会观察到这种明显的场景"数量不均衡":晴天的数据特别多,而雪天甚至沙尘暴的场景却非常少,有些情况甚至根本从未被模型见过。这就像一个长期生活在南方的人,从来没有在雪天里开过车,第一次遇到大雪路面时,很难马上做出正确、安全的驾驶决策。同样的,自动驾驶模型在面对这种未曾经历过或极少见的场景时,也难以保证稳定可靠的表现。
那么该如何解决分布偏移呢?为了应对在实际应用中可能出现的各种场景,以及算法对快速扩展和实时响应能力的要求,我们不禁思考:是否能通过数据可控扩增的方法,将已有的训练图像转化为一些尚未出现或极少出现的场景呢?其中,一种可行的范式是无训练可控生成(Training-free Controllable Image Generation)。该范式在生成新图像的过程中不对生成模型本身的参数做任何修改,而是通过用户输入的文本指令,灵活地控制生成的图像效果,如图2所示。这种方式不仅成本低、效率高,还能够快速实现,因此引起学术界和工业界越来越多的关注。
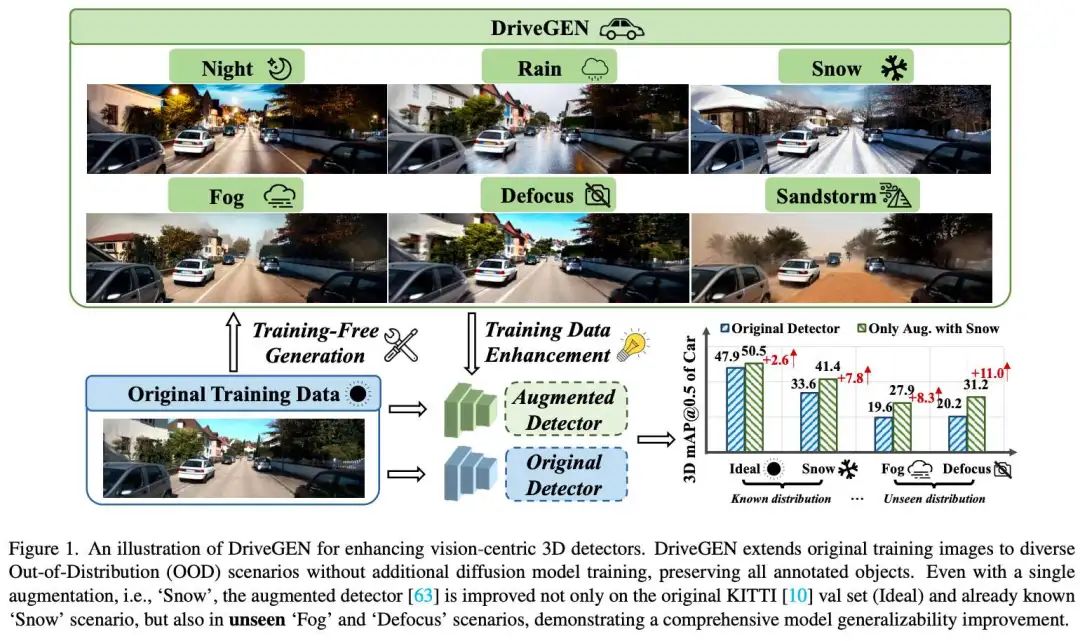
现存无训练可控生成方法主要面向通用图像编辑
无训练可控生成方法简单来说,就是在无需额外训练模型的情况下,对图像进行灵活且可控的编辑。目前该类方法主要用于通用图像修改,比如可以对图像主体进行变换,或添加、删除特定物体,快速生成所需图像内容。然而,在借助该技术将感知任务的训练图像扩充到各类分布偏移场景时,必须确保物体的三维信息与原始标注相匹配,否则就会给视觉感知模型带来额外噪音干扰。
技术方案
基于前面的讨论,我们不禁思考:要怎么去设计一个无需额外训练的可控生成方法,在准确保留物体三维信息的前提下,实现感知模型训练图像的可控扩充?来自香港中文大学(深圳)等单位的学者们给出了他们的看法。学者们提出了一个名为DriveGEN的方法,如图3所示。该方法由以下两个阶段所组成:1)自注意力物体原型提取;2)原型引导图像生成。具体细节阐述如下:

自注意力物体原型提取
该阶段旨在获取带有几何信息的标注物体特征,从而为后续引导图像生成奠定基础。如图3上半部分所示,给定输入图像 及其文本描述 ,通过DDIM Inversion可以得到时序潜空间特征 ,再输入到生成模型 (U-Net based)进行生成。从 中提取解码器的首层自注意力特征用于主成分分析,所得到的图像主成分 带有丰富的语义信息[2]。然而,现存方法往往通过类别名称与图像特征之间的交叉注意力掩码 以选取前景区域,学者们发现这很可能会产生物体信息遗漏,尤其是对那些体积相对小的物体。因此,给定标注物体区域 下的某一点(p, q),学者们引入一个峰值函数 为掩码 中的每个物体区域进行重新加权:
最终,借助带有准确物体区域信息 的指导,对图像主成分 进行重加权从而得到自注意力物体原型 。
原型引导图像生成
该阶段会通过两个层级的特征对齐以确保生成过程中,物体的三维信息能够被更好地保留。一方面,由于 解码器的首层自注意力特征带有丰富的语义信息,DriveGEN设计了语义感知特征对齐项 ,旨在借助自注意力物体原型 引导 在转换图像场景时保留原有物体:
另一方面,学者们通过观察发现:在自动驾驶视觉感知中,相对深层的图像主成分 难以精细地表示每个物体信息,尤其对小目标更是如此。举例而言,一个高20像素、宽5像素的行人框经多次(如32倍)下采样后,最终在主成分中无法占据一个独立的单元。因此,DriveGEN基于时序潜在特征 对浅层特征进行对齐,以确保相对小的物体的信息也能够被准确保留:
最终,模型的整体优化目标为:
其中, 代表无文本描述输入,DriveGEN 是一个基于无分类器引导[3](classifier-free guidance)的过程。
实验
方法有效性
一方面,DriveGEN能为现存单目三维检测方法带来可观的性能提升,实验结果展示了探索的新方法可以在模拟的域外分布测试场景(包括Noise,Blur,Weather,Digital四类)中带来显著的改进:
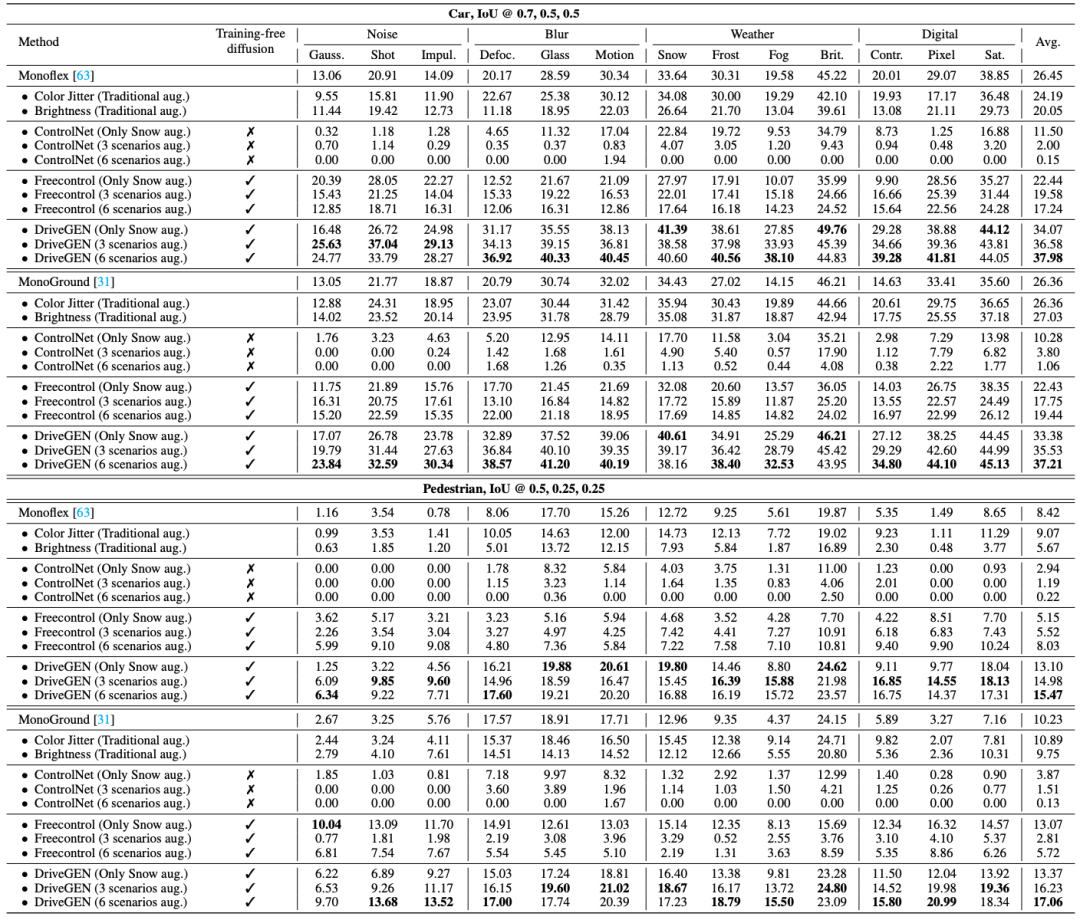
其中分别探索了三种训练图像增广设定,即1)仅额外增广雪天(Only Snow aug.)下的场景;2)额外增广雪天、雨天和雾天下的场景(3 scenarios aug.);3)额外增广训练图像到雪、雨、雾、黑夜、失焦以及沙尘暴6种场景下(6 scenarios aug.),广泛地验证了所提出方法的有效性。
另一方面,DriveGEN基于现存多目三维检测方法做进一步实验,仅基于nuScenes数据集上五百个场景所增广的三千张雪天训练图片,即可为模型带来可观的性能提升:

其中nuScenes-C是应用更广泛但挑战难度更大的任务基准,而nuScenes-Night以及nuScenes-Rainy则代表两个真实的现实世界下分布偏移数据场景。
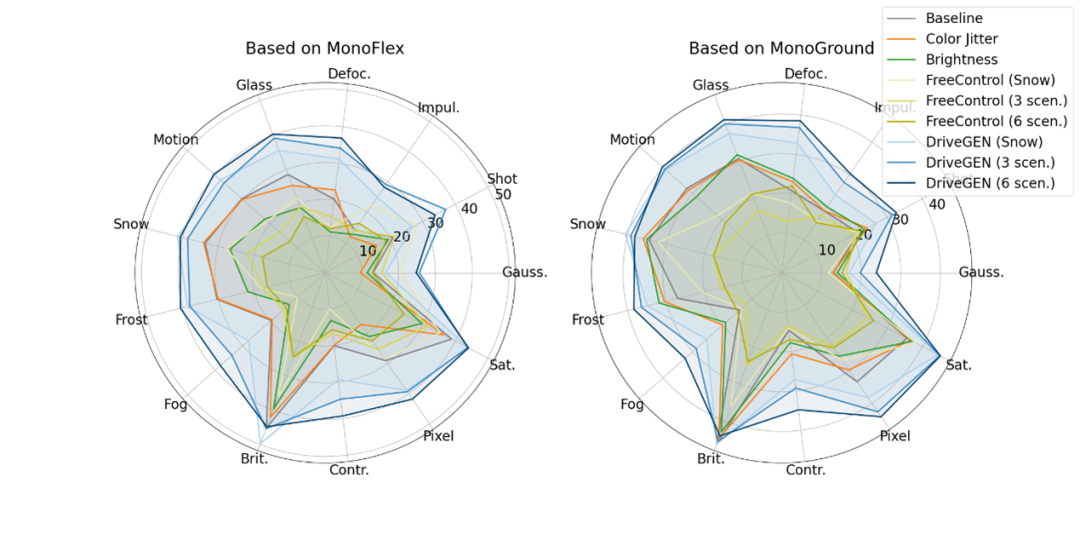
消融实验
如下图3所示,一方面表明了所提出方法各个优化项的有效性,比如加上物体原型能初步得到保留物体信息的生成结果,而浅层特征对齐则进一步促使生成模型能够比较好地保留在图片中相对小的物体。

结果可视化
进一步提供了单目和多目的可视化结果如下图所示:
图6 基于KITTI数据集的单目三维检测图像增广示例

图7 基于nuScenes数据集的多目三维检测图像增广示例
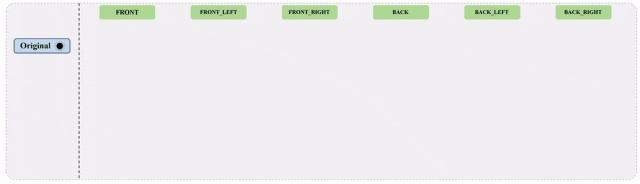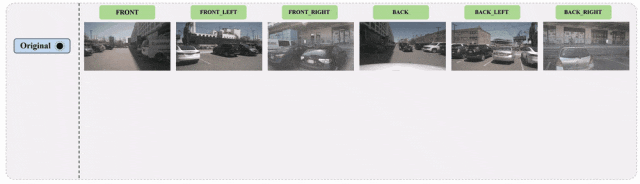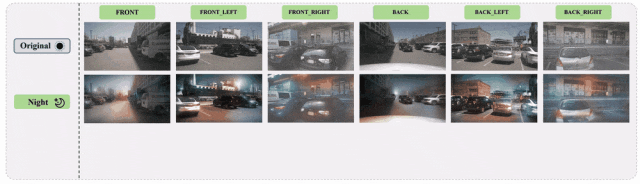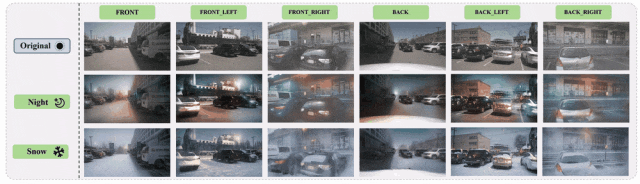
基于上述实验结果,有理由相信通过对视觉三维检测训练数据的有效扩充,该论文所设计的方法能够有效地提高视觉感知模型的泛化性能,从而提升三维检测在自动驾驶中的落地和应用。
关于作者
论文第一作者林宏彬来自香港中文大学(深圳)理工学院的Deep Bit 实验室、深圳市未来智联网络研究院,导师为李镇老师。目前实验室的研究方向包括:自动驾驶、医学成像和分子理解的多模态数据分析和生成等。
感兴趣的同学可以浏览https://mypage.cuhk.edu.cn/academics/lizhen/。
References:
[1] https://www.reuters.com/business/autos-transportation/alphabets-waymo-recalls-over-1200-vehicles-after-collisions-with-roadway-2025-05-14/
[2] Sicheng Mo, Fangzhou Mu, Kuan Heng Lin, Yanli Liu, Bochen Guan, Yin Li, and Bolei Zhou. Freecontrol: Training-free spatial control of any text-to-image diffusion model with any condition. In CVPR, 2024.
[3] Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598, 2022.
自动驾驶之心
论文辅导来啦

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









