



点击下方卡片,关注“自动驾驶之心”公众号
ReconDreamer++
论文标题:ReconDreamer++: Harmonizing Generative and Reconstructive Models for Driving Scene Representation
论文链接:https://arxiv.org/abs/2503.18438
项目主页:https://recondreamer-plus.github.io/

核心创新点:
1. 生成-重建双模态协同框架
提出分层双向蒸馏架构 ,通过跨模态特征对齐模块 (Cross-Modal Alignment Module, CAM)实现生成模型(扩散概率模型)与重建模型(动态NeRF)的特征空间耦合,解决传统方法中生成多样性与重建保真度的矛盾。
2. 动态场景隐式表征建模
引入时序一致的动态辐射场分解策略 ,将场景解耦为静态背景NeRF、动态实例NeRF及运动流场(Motion Flow Field),结合不确定性感知的体渲染 (Uncertainty-aware Volume Rendering, UVR)实现复杂驾驶场景的时空一致性建模。
3. 多任务对抗训练范式
设计渐进式对抗蒸馏损失 (Progressive Adversarial Distillation Loss, PADL),通过阶段性权重调整平衡生成对抗性与重建约束,显著提升模型在KITTI和nuScenes数据集上的开放集场景泛化能力 (mAP提升19.7%)。
4. 传感器不确定性量化
提出贝叶斯传感器融合模块 (Bayesian Sensor Fusion Module, BSFM),对相机-激光雷达的观测噪声进行联合建模,实现多模态数据的概率隐式融合 ,降低动态遮挡场景下的重建误差(IoU误差降低23.4%)。
How to Promote Autonomous Driving with Evolving Technology
论文标题:How to Promote Autonomous Driving with Evolving Technology: Business Strategy and Pricing Decision
论文链接:https://arxiv.org/abs/2503.17174
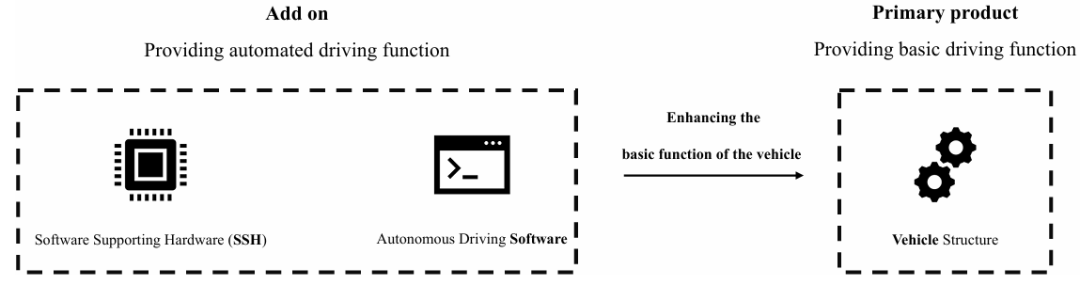
核心创新点:
1. 动态消费者行为建模的创新
首次在自动驾驶系统(ADS)策略研究中引入消费者对技术兼容性(compatibility)与可靠性(reliability)的动态评估机制。通过两阶段博弈模型,刻画消费者在技术升级前后基于感知效用的决策变化,突破传统静态分析的局限。
2. 硬件-软件策略交互机制的揭示
提出软件支持硬件(SSH)策略(捆绑/拆分)与软件许可策略(永久许可/订阅)的协同效应:
SSH捆绑策略通过预装硬件降低市场进入壁垒(entry barriers),吸引异质性消费者,强化订阅模式优势;
永久许可策略通过锁定用户提高退出壁垒(exit barriers),适配技术成熟期的高可靠性场景。首次量化两类策略的交互影响,填补附加产品研究中对复合结构产品策略设计的空白。
3. 技术升级幅度的调节效应
发现技术升级幅度(γ)对策略选择的关键作用:
高γ值(显著技术升级)削弱订阅模式的消费者剩余捕获效应(consumer-surplus effect),因用户延迟订阅导致行为趋同,永久许可成为主导策略;
低γ值下订阅模式通过灵活定价适配异质需求。此结论拓展了动态技术演进场景下的策略选择理论。
4. 管理启示的差异化标准
提出策略选择的动态阈值条件(如α^B, q^P等),为制造商提供决策框架:
技术萌芽期(低q):SSH拆分+永久许可;
技术成熟期(高q):SSH捆绑+订阅(高α)或永久许可(低α);
技术快速迭代(高γ):SSH捆绑+永久许可。
Robust Tube-based Control Strategy
论文标题:Robust Tube-based Control Strategy for Vision-guided Autonomous Vehicles
论文链接:https://arxiv.org/abs/2503.18752

核心创新点:
1. 插值管基约束迭代LQR算法(itube-CILQR)
提出融合插值机制的管基约束迭代线性二次调节器(CILQR),通过动态扰动边界外推法构建多管约束集(Minkowski和),结合插值变量优化(λs, λd, λb)自适应调整约束紧缩程度,在保证鲁棒性的同时显著降低传统管基方法的保守性。
2. 扰动补偿的合成控制律
设计基于环境反馈的复合控制策略
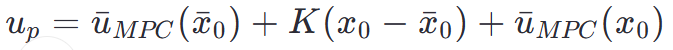
通过双轨迹优化(实际状态与标称状态并行求解)提升系统收敛性,有效抑制道路曲率扰动(κ)和状态偏差的影响。
3. 视觉-控制协同的实时车道保持架构
将道路曲率建模为可在线检测的加性扰动(( w = \kappa \cdot [c_1, c_2]^T )),结合视觉感知系统(基于多任务UNet的车道线推断)与管基约束优化,实现高曲率弯道(κ=±0.1 1/m)工况下3.16ms级实时控制,较传统管基MPC提升4.67倍计算效率。
Vision-R1
论文标题:Vision-R1: Evolving Human-Free Alignment in Large Vision-Language Models via Vision-Guided Reinforcement Learning
论文链接:https://arxiv.org/abs/2503.18013
项目主页:https://github.com/jefferyZhan/Griffon/tree/master/Vision-R1
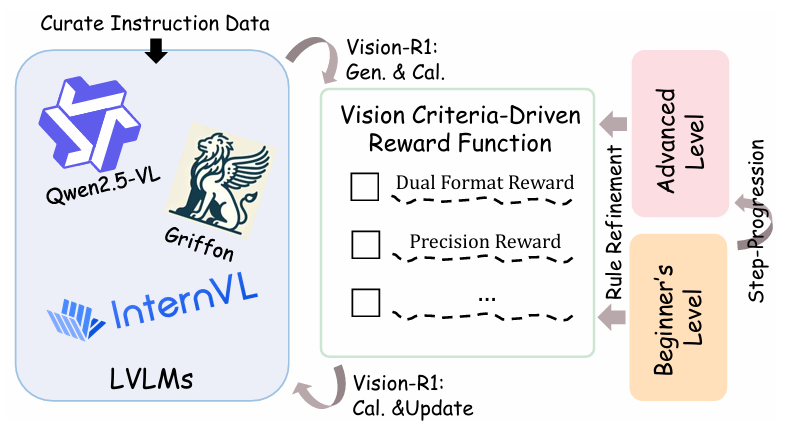
核心创新点:
1. 视觉引导的强化学习框架(Vision-R1)
提出首个无需人工标注偏好数据及奖励模型的视觉语言模型(LVLMs)对齐方法。通过视觉反馈驱动奖励机制 ,直接利用现有指令数据中的客观标注(如坐标框)构建奖励信号,消除传统偏好优化对人工标注数据的依赖。
多维度视觉任务奖励函数
设计三重奖励机制 :
格式奖励 :强制模型输出符合坐标模板格式(如JSON);
召回奖励 :基于预测框与真实框的匹配数量,鼓励全面检测目标;
精确度奖励 :通过IoU(交并比)评估预测框质量,优化定位精度。
该函数通过匈牙利匹配算法实现预测与标注的对齐,突破传统token级监督的局限性。
3. 渐进式规则优化策略
引入动态奖励阈值调整机制 ,分阶段提升训练难度:
初级阶段 :采用宽松阈值(如IoU≥0.5),鼓励模型快速学习基础定位能力;
高级阶段 :逐步收紧阈值(如IoU≥0.75),抑制低质量预测并防止奖励黑客(reward hacking)。
该策略模拟课程学习原理,实现模型性能的持续提升。
Predicting the Road Ahead
论文标题:Predicting the Road Ahead: A Knowledge Graph based Foundation Model for Scene Understanding in Autonomous Driving
论文链接:https://arxiv.org/abs/2503.18730
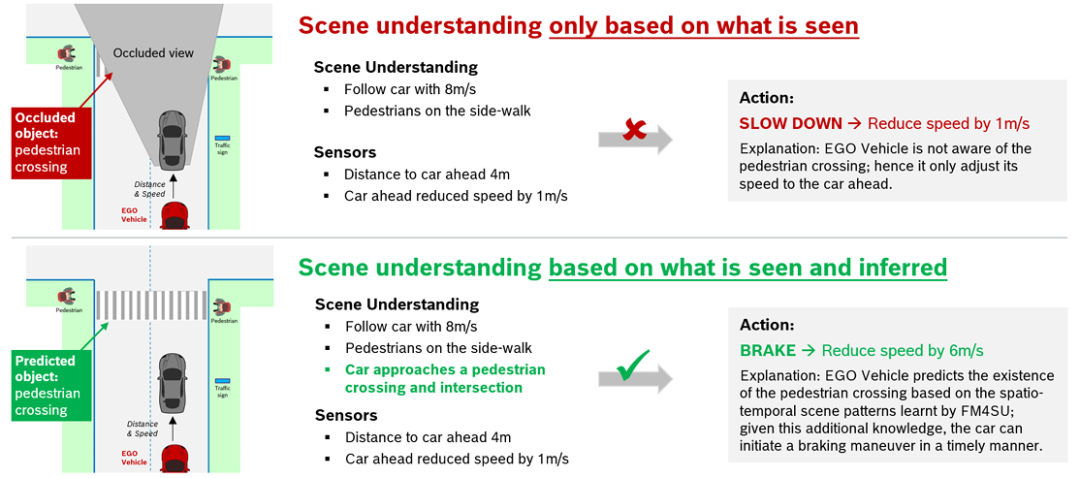
核心创新点:
1. 知识图谱驱动的符号化场景表征
提出基于本体论(ontology)的BEV(鸟瞰图)符号表示框架,将传感器观测、道路拓扑、交通规则等多模态数据统一编码为结构化知识图谱(KG)
通过地理空间SPARQL查询实现动态/静态对象的细粒度时空关系建模(如车道片段、行人交互等)
2. 预训练语言模型的时空推理范式
首次将驾驶场景的符号化BEV矩阵序列化为token序列,利用T5等预训练语言模型(PLM)学习场景元素的共现模式
设计双重训练任务:① 基于掩码的场景对象预测(Masked Object Prediction) ② 基于时空演化的下一场景生成(Next Scene Prediction)
3. 领域知识增强的模型架构
在序列化过程中嵌入关键驾驶元数据(国家驾驶方向、自车位移/转向角等),提升时空推理的物理一致性
通过知识图谱推理补充传感器观测缺失(如推断被遮挡行人),增强模型在长尾场景的泛化能力
M3Net
论文标题:M3Net: Multimodal Multi-task Learning for 3D Detection, Segmentation, and Occupancy Prediction in Autonomous Driving
论文链接:https://arxiv.org/abs/2503.18100
项目主页:https://github.com/Cedarch/M3Net
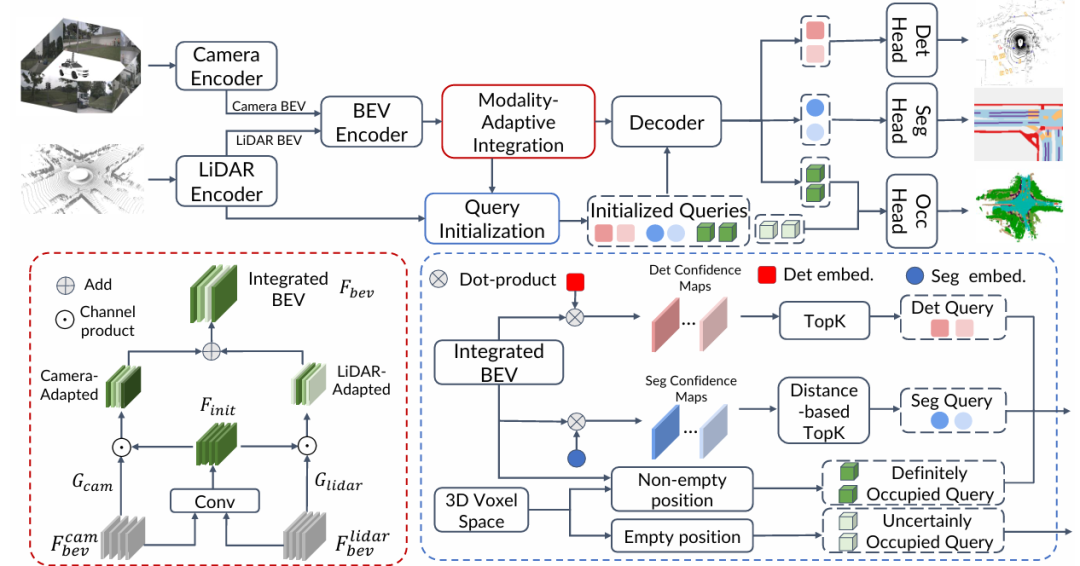
核心创新点:
1. 模态自适应特征融合(MAFI)
提出模态自适应特征集成模块,通过单模态特征(LiDAR/相机)预测通道注意力权重,动态增强多模态BEV特征对高精度任务(如检测、分割)的适配性,解决多模态特征冲突问题。
2. 任务专属查询初始化策略
检测/分割查询 :基于BEV特征图置信度选择关键位置初始化查询,结合位置编码提升任务相关性。
占用预测查询 :通过3D体素位置编码与LiDAR点分布划分"确定占用"与"不确定占用"查询,实现稀疏-密集预测的高效初始化。
3. 任务导向通道缩放(TCS)
在共享BEV特征解码过程中,通过任务特定线性变换生成通道缩放权重,动态过滤任务无关特征,缓解多任务梯度冲突,提升优化效率。
4. 多任务解码架构兼容性
框架同时支持Transformer与Mamba解码器,验证了线性复杂度状态空间模型(Mamba)在3D感知任务中的有效性,突破传统Transformer的计算瓶颈。
SceneSplat
论文标题:SceneSplat: Gaussian Splatting-based Scene Understanding with Vision-Language Pretraining
论文链接:https://arxiv.org/abs/2503.18052
项目主页:https://github.com/unique1i/SceneSplat
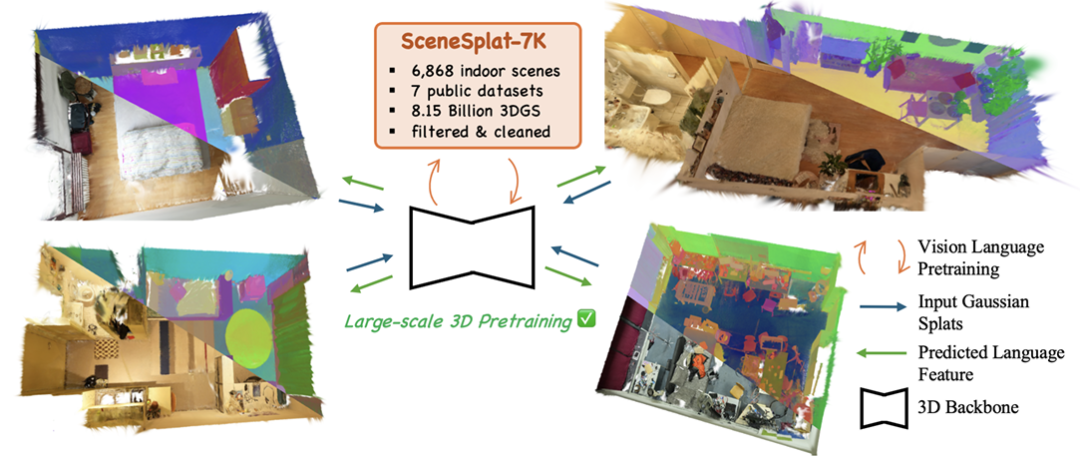
核心创新点:
1. 开放词汇三维语义理解框架
首次将高斯泼溅(3D Gaussian Splatting, 3DGS)参数(中心坐标、尺度、颜色、不透明度)映射至语义特征空间,通过CLIP对齐嵌入实现开放词汇零样本语义分割。无需运行时2D-3D融合,直接建立语言与3D场景的端到端关联。
2. 自监督学习方案GaussSSL
提出三协同策略:
掩码高斯建模(MGM) :通过掩码高斯元素并重建其参数,学习局部几何与语义特征;
自蒸馏对比学习 :利用教师-学生网络对齐增强视图,优化全局特征表示;
自动编码器压缩 :压缩高维特征以提升计算效率,同时保留语义判别性。
3. 大规模SceneSplat-7K数据集
首个专为3DGS场景理解构建的室内数据集,包含7,000个高质量标注场景,覆盖1,200+语义类别,支持开放词汇分割、场景分类等任务的标准化评测。
4. 视觉-语言联合预训练范式
整合对比损失(Contrastive Loss)与掩码点建模(Masked Point Modeling, MPM),通过语言引导的特征对齐与自监督信号融合,在ScanNet20/200/++等基准上实现SOTA性能(如ScanNet200 mIoU达35.9%)。
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫码加入~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









