



作者 | SPiriT 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/28974854144
点击下方卡片,关注“自动驾驶之心”公众号
>>点击进入→自动驾驶之心『强化学习』技术交流群
本文只做学术分享,如有侵权,联系删文
说明
最近强化学习的风又有点吹起来了,作为曾经的RL从业者,开始翻一些以前的经典资料,温故而知新。这篇复习的是22年的经典博文,细致研究了ppo的一些实现细节,对我当时实现 ppo 给于很大帮助。
iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/
注意
以前的rl都集中在序列决策问题上,即怎么最大化累计收益的期望,所以背景大都是游戏和控制相关,例如Atari game, Mujoco等, 与当前(2025年3月)rl在llm中的热度方向不一致。
原博文内容也集中以解决“游戏决策”为背景,同时以算法实现细节为基础。
本文会根据原博内容进行酌情增减
正文
原文主要目的是:复现官方的PPO实现,在github开源代码中,最终对比选择了 openai 的 baselines\ppo2 作为复现参考。原因如下:
ppo2 算法在 Atari 和 MuJoCo 的任务上都表现不错
包含了LSTM和处理多维离线空间(MultiDiscrete)的一些高级处理,能处理 RTS 游戏(实施策略游戏,例如星际争霸、王者荣耀这种)
ppo 原论文提出了2个算法实现,ppo1 是动态缩放kl,而 ppo2 算法是直接clip,更简单好用。所以 ppo2 才是现在大家更熟知的 ppo 算法实现,以下都默认为 ppo2 算法实现
13个关键实现细节
1. 矢量化架构
envs = VecEnv(num_envs=N)
agent = Agent()
next_obs = envs.reset()
next_done = [0, 0, ..., 0] # of length N
for update in range(1, total_timesteps // (N*M)):
data = []
# ROLLOUT PHASE
for step in range(0, M):
obs = next_obs
done = next_done
action, other_stuff = agent.get_action(obs)
next_obs, reward, next_done, info = envs.step(
action
) # step in N environments
data.append([obs, action, reward, done, other_stuff]) # store data
# LEARNING PHASE
agent.learn(data, next_obs, next_done) # `len(data) = N*M`使用多进程,串行或并行的初始化一个矢量化的环境 envs ,包含了 N 个独立环境。训练时同时获得 N 个 obs ,执行 N 个action,最后获得 N 个 next_obs。其中 next_done 代表各个环境里每一步有没有done。
这里面有2个循环
Rollout phase:每个环境里的 agent 执行 M 步收集数据。
Learning phase:从上面收集好的数据里学习更新网络参数,数据规模是 N*M 。
矢量化环境的优势很明显:1、并发收集数据更快,学习更快。2、各环境独立保证数据多样性,学习更稳。
这种并发是基操,但困难也很明显:1、很吃cpu,尤其是动作空间或状态空间很大的游戏,而一些重的env有时候很难并发。2、learner的消费可能跟不上生产导致数据浪费,所以要实验配比。
需要理解 next_obs 和 next_done 的角色:done代表是否结束,比如游戏结束或者被截断了。当环境done后,next_obs就是下一个阶段的第一个观测。这样即使一个episode只执行 M 步,但 ppo 依然能在没法停止或阶段的环境里学习。
上面这个最开始没看懂,后来才理解这个 reset 可能是 env 里面的“原地”reset。
这个不太符合一些游戏设定,因为大部分 reset 是直接回到 env 的“起点”,比如王者荣耀ai,在纯粹的游戏设立里,ai done后肯定是回到老家水晶,而不是在原地复活继续 battle。
但为了实现类似功能,一般都会让 ai 自由出生,或者从 env 的某个中间状态 reset(比如半血在中路位置复活),而不是完整受限于游戏进程,这样能减少训练的探索成本。
一个比较普遍的错误实现如下。错误有两处:1、单个env效率很低。2、对于RTS游戏(一个简单epsiode至少1M step)内存不够(相比上面,在采样相同step的数据而言)。
env = Env()
agent = Agent()
for episode in range(1, num_episodes):
next_obs = env.reset()
data = []
for step in range(1, max_episode_horizon):
obs = next_obs
action, other_stuff = agent.get_action(obs)
next_obs, reward, done, info = env.step(action)
data.append([obs, action, reward, done, other_stuff]) # store data
if done:
break
agent.learn(data)关于 N 和 M 的取值经验:在相同的 N*M 数据需求下,并不是 N 越大越好,相反 M 太小会导致探索太短。因为“shortened experience chunks”和“earlier value bootstrapping.”
关于上面说的错误实现,和前面“正确实现”的主要区别在于:done后要不要break。前面的实现是一直走M步,但如果中间某步done=True了,后面全部的done都是True,这样在计算V值时只会计算单步的reward,序列决策的反馈就没有,数据学习效率不高。
不过反过来想,前面的实现或许默认了“done后的step依然生效”这一逻辑,不用管done的值来中断epsiode,代码结构上更统一。
更细节是,平时自己写是 data.append([obs, action, reward, next_obs]),即存储一个完整的 state transition。这样能避免上面的问题,但问题是多存了个next_obs对 mem 不友好。
矢量化的环境天然支持 MARL (多智能体强化学习),兼容性更强。比如1个环境下初始化 N 个player,这样 M 步的数据量就变成了在同一环境下 N 个 player 执行得到的所有数据。
2. 网络的权重正交初始化、偏差常数初始化
源码实现如下:
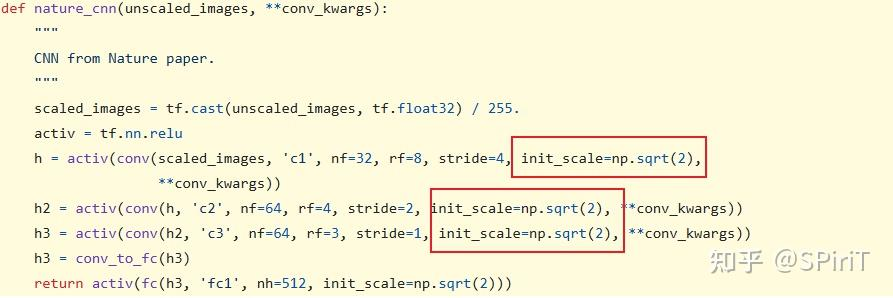

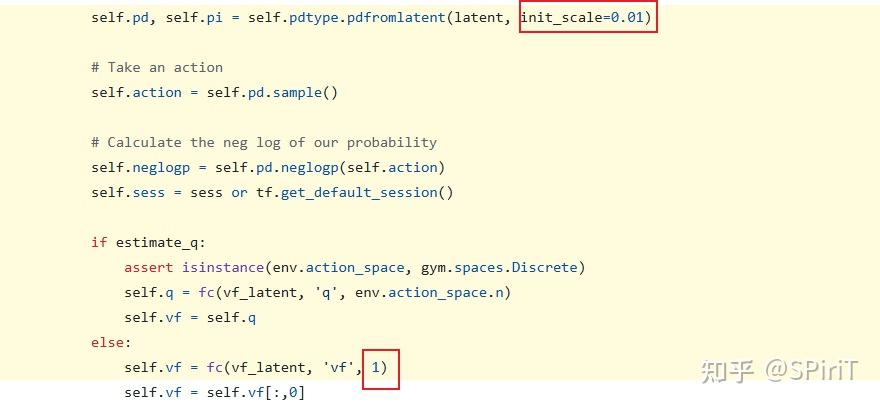
上面CNN、MLP里的正交初始化和 pytroch 自带的 api 实现不太一致,但对性能没什么影响。有一些证据证明orthogonal 相比 Xavier 要好一些。
3. Adam 优化器的epsilon参数值
ppo 实现里面的值是 1e-5 ,这和 pytorch (1e-8) 和tf里(1e-7)都不一样,为了保证可复现性保持一致。
4. Adam 学习率退火
Atari 的 lr 是从 2.5e-4 随着 step 线性衰减到0,Mujoco 任务里是从 3e-4 线性衰减到 0
5. GAE
gae 的提出要晚于 ppo 算法,但它现在是个默认实现,在 gamma 取特殊值时(0 和 1),gae 等效 td 和 mc。而且有证据表现:gae 要比 N-step 的 returns 要好(更好的 trade off 近视和远视)。
6. Mini-batch 更新
对于上面的N*M 数据,一般会先把数据 shuffle,然后用一个小的 batch_size 分批计算梯度更新网络。
一些错误实现:1、直接用全部数据计算,而不是分mini batch_size,2、随机选择 mini-batchs而不是全部学习。
这个 mini batch size 是一个比较重要的参数,在训练初期需要微调来平衡效果和性能。
这个原理其实好理解,首先 N*M 数据总量通常是比较大的,比如 N=20,M=2048 等,不可能全部直接计算梯度去更新网络,所以需要min batch size的概念。
其次,ppo 是 on-policy 算法,学习完的数据只能丢弃重新收集,最好能充分利用数据,所以 mini batchs 能让 ppo “小步快跑“的充分学习,并通过 clip 的方式保证稳定性。
最后,一般数据都是序列收集的,时序关联太强,shuffle 后再 mini batch 对学习更友好
7. advantages 归一化
gae 计算完后建议归一化,就是简单的减去均值除以方差。注意是在 mini_batch 里做而不是针对整个数据。
因为是对 mini_batch 计算梯度来更新,所以得在 mini_batch 里用。不过这一细节影响不大。
8. clipped surrogate objective
ppo 论文核心细节,有些任务里直接的 cliped 和 trpo 算法最后效果是一样的,但优势在 ppo 实现比 trpo 更简单
9. value loss clipping
对 v_net 的 loss 也进行 clipping,不过一些研究表明这个作用不大。注意这里是用 t-1和 t 时刻做对比,下面是不同数值clip 的结果:
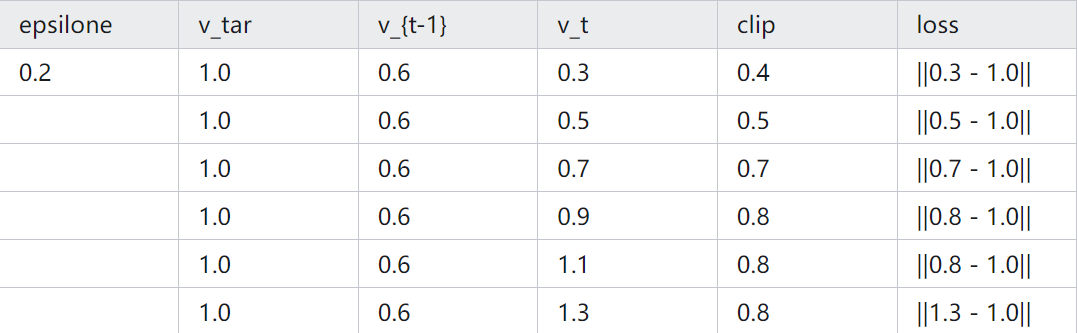
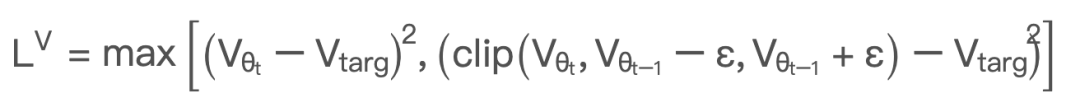
这个 value clipp 以前没用过,对于为什么取 max也没很理解。
从上面表格能看出,只有当 v_t 相比 v_t-1 超过 eps 更靠近 v_tar 时,这个 clip 才会实际生效。这个 max操作变相的增加了原来的 loss。
10.entropy loss
原文里为了增加策略随机性,把 policy 的 entropy 也加入 loss 计算,也是常规细节之一。
loss = policy_loss - entropy * entropy_coefficient + value_loss * value_coefficient11. global gradient clipping
把全局参数的 l2_norm 截断到 0.5 内
12. debug变量
ppo 实现里有很多用于 debug 的变量,除了上面 3 个 loss,还有以下几个:
clipfrac: 训练数据里触发 clipped 的比例
approxkl: 新旧策略的近似 kl 散度,计算上直接用 -logratio.mean() 。关于 kl 散度近似计算可以看这个博文
这两个参数更多是初步调参时需要注意的,尤其用于代码 debug,如果 clipfrac 太多说明策略更新太快,通常是有 bug
13. policy_net 和 value_net 网络是否共用 backbone
ppo 默认实现是共享网络结构,然后分别出 policy_head 和 value_head.
原博实现了网络分开实现的代码,最后实测效果明显比 shared 的更好
是否共用 backbone 是 RL 一个常见问题,共用的好处是,节省算力减少开销、共享特征信息。劣势也明显,两个loss 的梯度目标可能并不一致。不过在业务上好像都习惯采用 shared 方式,网络结构影响比想象要小。
9个Atari实现细节
atari游戏实现相关的一些 trick细节,摘取了一些有参考意义的。
NoopResetEnv:在reset的时候随机进行一定数量的noop操作【0-30】,目的是使游戏开始时的初始状态具有一定的变动。
MaxAndSkipEnv:默认跳 4 帧执行,4 帧内执行重复动作,收集 4 帧累计的 reward 作为实际 reward,能加速模型收敛,毕竟有时候 env.step 要比 policy_net(state) 计算更快。并且状态选择最后 2 帧的最大值pixel,应对 atari 像素游戏里的怪物特征闪烁(游戏里的闪烁动效)。
EpisodicLifeEnv:有些游戏里角色有多条命,只有命数到 0 时游戏才结束,这里包装成只要命数-1就算 done。不过其他论文说这个对最终表现有害 。
FireResetEnv:有些游戏可能需要固定按键作为开始,这里就修改成 reset 后执行action-1 和action-2再继续游戏。不过这个细节好像并没啥作用而且没法追溯设计动机?
WarpFrame:把 rgb 图像灰度化,然后 resize(210x160 -> 84x84)
ClipRewardEnv:根据 reward 的正负全部映射到 {+1, 0, -1},这样就能一起学不同的游戏,但这样也会影响模型在具体游戏里一些细致化操作。
FrameStack:叠帧,默认叠 4 帧,这样能感知移动物体的速度和朝向。
policy_net 和 vlaue_net 共用网络的 backbone
pixel 值归一化,除以 255。
9个连续动作空间实现细节 [Mujoco]
基于正态分布的连续动作:pg 类算法从正态分布中采样来得到连续性动作,所以网络任务就是预测分布的均值和标准差,通常使用“高斯分布“。
与状态无关的对数标准差:网络输出均值的logits,而对于标准差输出 log std,初始化为0且和状态无关。
独立的动作组合:在很多机器人任务中有不同维度的动作输出,比如向左移动 3.5m和向上运动 4.2m,输出是[ , ],为了可微,ppo把它们视为概率独立的分布,所以计算动作的概率就是多个动作概率相乘:prob( ) = prob( )* prob( ).
这种设定假设各个维度的动作是完全独立,满足全协方差的高斯分布,但有些任务里面动作之间是耦合,所以也有文章研究非独立的动作选择问题(例如用自回归的策略),这是个开放性问题。
分开实现的 policy_net 和 value_net
对于连续控制问题,ppo 通常的网络设计是 64 hidden MLP,中间用 tanh 作为激活函数,后面再接两个 head.
和前面讨论的细节一样,实验证明把网络 backbone 分离设计最后效果要更好
处理动作越界问题
既然动作是从分布采样得到,必然会遇到越界问题,比如动作范围是 [-10,10],结果采用得到 +12。在实际执行时需要把动作截断在合法范围内,但存储原始动作来计算梯度更新网络。
有些研究会在分布采样后面加个可逆压缩函数(如tanh),这样就能兼容动作合法问题。一些研究证明这种方式更好。
观测归一化:数据在喂给网络前会对观测值 obs 进行动态归一化,减去 running_mean 再除以 running_std .
注意这里是 moving average normalization
观测截断:对 obs归一化后再截断在一个固定区间内,比如代码里是 [-10, 10] 之间。对于obs区间很大的环境会有帮助。
奖励缩放:就是计算折扣后再动态归一化
def step_wait(self):
obs, rews, news, infos = self.venv.step_wait()
self.ret = self.ret * self.gamma + rews
obs = self._obfilt(obs)
if self.ret_rms:
self.ret_rms.update(self.ret)
rews = np.clip(rews / np.sqrt(self.ret_rms.var + self.epsilon), -self.cliprew, self.cliprew)
self.ret[news] = 0.
return obs, rews, news, infos奖励截断:同前。但是目前对 reward 的 scaling 和 clipping 是否有效没有确凿证据。
5 个 LSTM实现细节
权重和偏置初始化为 std=1 和 0。
hidden & cell 都初始化为 0
在 epsiode结尾 reset LSTM的 state
使用时序连续的训练数据喂给网络,不能和之前一样 shuffle
Reconstruct LSTM states during training
MultiDiscrete动作空间细节
基于前面的多维动作空间独立的设定,alphastar和 openai five 都使用 MultiDiscrete 来建模动作空间,例如 openai five 就用了 MultiDiscrete([ 30, 4, 189, 81 ] 。所以最后的动作空间维度是:30 × 4 × 189 × 81 = 1, 837, 080 dimensions
4个辅助实现系列
官方 ppo 没有实现,但是在某些场景下可能有用的 4 个 trick
clip range 退火:比如从 0.2 逐渐退火到 0
并行梯度更新:多进程并行计算梯度,这样能利用所有可用进程来缩短训练时间。
策略优化提前终止:在 actor的 mini batch 中,spinning up 里会在 kl 散度大于阈值后提前结束,而不是跑完固定的 epoch 数。代码里面是 target_kl 默认是 0.01,阈值是 1.5 * 0.01。
非法动作 mask:openai five 和 alphastar都用了大量的非法动作 mask,具体实现上就是在 softmax 之前,用规则把invalid_action的 logits 修改成 -inf。 这个论文 证明这种mask 实际是把 invalid action 的梯度置零
logits = torch.where(self.masks, logits, torch.tensor(-1e8).to(device))invalid_action_mask 是非常常见且有效的 trick,但是mask一般是人为规则写的,会损失策略的一部分探索性
结论
建议
一些有用的 debug 方法:
seed anything:在复现时候可以观察 obs 和 act,对齐各类数值,确保实现没有问题
检查 ratio =1:在第一个 epoch 和第一个 mini-batch 更新期间,检查 ratio是否为 1,此时新旧策略相同所以 ratio应该一直是1
检查 KL散度:approx_kl 通常应该保持在 0.02 以下,如果过高说明策略更新太快,通常是有 bug
检查其他指标:policy loss \ value loss 这些指标,如果是复现代码,检查和官方的是否相近
经验法则:检查 ppo算法在 breakout 游戏里能否拿到 400 分,作者发现大部分 ppo实现仓库都没法得到,说明有细节没有对齐。
对于 ppo 研究者的一些建议
枚举使用的实现细节。考虑用本文这种方式来列举他们
发布源码。开源代码并确保能运行,建议用 poetry 和 pipenv 来管理锁定依赖。很多pip install -e .的代码仓库都没法直接跑。用 docker 管理装好依赖的镜像也是个好办法
管理实验。跟踪管理指标、超参数、代码和其他东西,会节省大量时间。商业软件如:Weights and Biases、Neptune, 开源项目:Aim,ClearML,Polyaxon.
单文件实现。如果研究需要很多调整,建议有单个文件实现他们,这么做代价是代码重复和难重构。但好处是:1. 更容易总揽全局,直接看到所有算法细节,再去看结构化的 rl仓库就更轻松;2、开发更快;3、更方便性能归因,直接查看文件 diff就行。
异步ppo更好吗?
Asynchronous PPO (APPO)能够增加吞吐量,消除ppo里面等待环境交互采样的空闲时间,提高吞吐量和 gpu、cpu利用率。但 这篇论文 论证了对性能有损害,不过最大的问题是:没有稳定可靠的 appo benchmark 实现。
相反,使用更快的矢量化环境来加速 ppo 更靠谱点,用 envpool 做了对比,发现能比之前快 3 倍。在 pong 上的表现甚至能和 impala 对比。
所以引出一个现实考虑:使异步的 rl 算法例如 impala,还不如想办法让并行环境运行更快。
一些其他研究
其他选择:对连续动作使用其他分布,lstm 不同初始化等等
值函数优化:ppg 探索了 pi_net 和 v_net更新频率,能否在 ppo里用prioritized experience replay?
自动驾驶之心
论文辅导来啦

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 2355
2355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









