



作者 | 论文推土机 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/570736638
点击下方卡片,关注“自动驾驶之心”公众号
>>点击进入→自动驾驶之心『决策规划』技术交流群
本文只做学术分享,如有侵权,联系删文
记录Continuous Decision Making for On-road Autonomous Driving under Uncertain and Interactive Environments,Jianyu Chen1, Chen Tang1, Long Xin1;2, Shengbo Eben Li2 and Masayoshi Tomizuka1。本文处理一个考虑uncertainty和interaction的决策问题,但是细节部分不详细,只能用来拓展下思路。文章将要处理的决策问题描述成一个带约束的优化问题,然后通过求解此问题获得最后的initial guess, 这个结果给下层的trajectory planner进行进一步优化,特别的这里对优化问题的求解是采用了sample and check的方式,也就是说先进行采样,然后通过约束检测找到不违反约束的最优解。而其中与决策部分最关键的就是motion prediction,所谓的处理uncertainty的方式就是给出周围车辆的不同的可能动作并附上概率;而对interaction的处理则是通过交互模型产生本车对目标车的未来动作的影响,只可以这部分并没有详细写而只是说了一下自己使用了交互模型。文章的abstract如下:

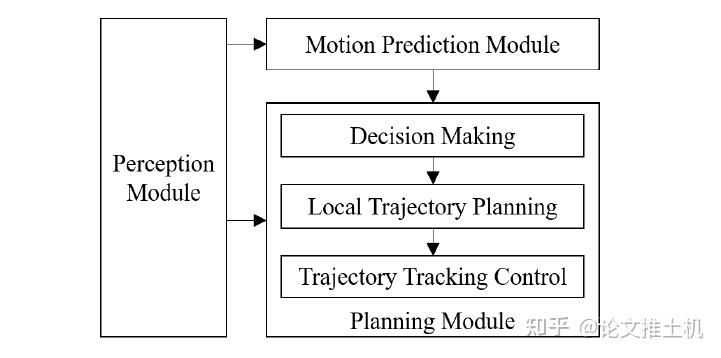
文章的基本设计架构如下,将prediction, decision 和trajectory planning组合成一个大的planning模块:
作者首先做了一个假设,这里的决策主要决策的是未来的速度profile的分配,因为不同的速度分配就会产生overtake或者yield的动作结果,而对于横向的移动,作者将更换参考线作为横向决策的标准,也就是说像overtake这种临时离开参考线,过一会再回去的动作只要规划分配纵向速度即可,不存在横向决策,而那些换道操作这是存在横向决策的,所以这里对于横向决策作者则是采用了离散化的表达,用 动作来表达横向决策。因此,在下面的优化问题中,优化的对象就有纵向的速度profile, 以及横向的离散动作(只有三种,lane keeping, lane change left and lane change right), 最后还有纵向的加速度。所以现在可以将当前的决策和规划问题写成一个优化问题:
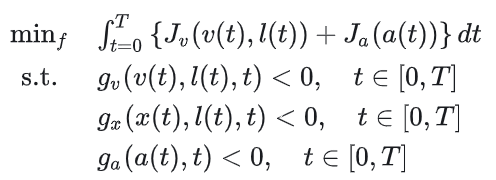
这里的cost包括对速度和加速度的惩罚。约束速度,加速度,以及纵向位置。这个纵向位置的约束主要来自于车辆,交通信号灯以及汇车等情况。
为了连续性表达,作者将车道中心线用贝塞尔曲线表达,并以此表达出车道的信息,车道写成:
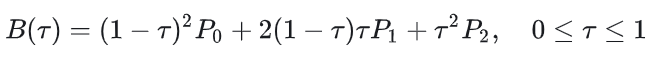
对应导数:
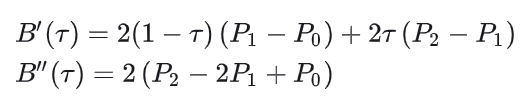
曲率为:
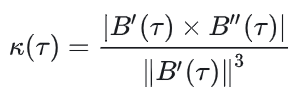
车速限制:
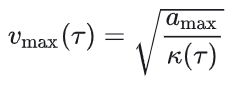
然后是速度采样,采用了在 — 图上进行采样的方案:
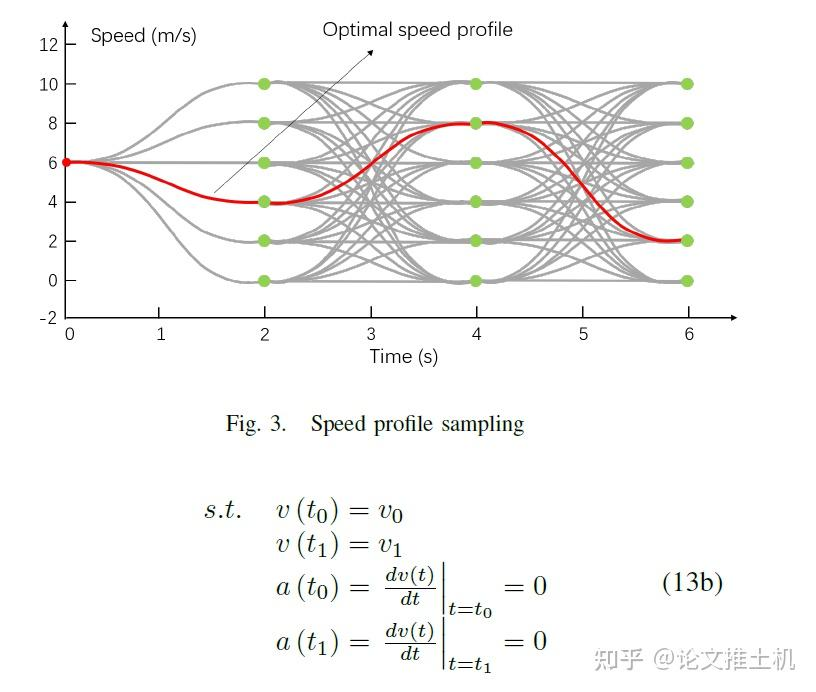
采样出所有可能方案,然后进行评估。
接下来是对uncertainty和interaction的处理,作者提出了三步架构:
第一步:安全stage, 在这个时间段需要严格满足避障要求。
第二步:Uncertainty Bifurcation Stage,由于目标对象可能产生不同的motion, 所以这一步通过bifurcation得出不同的状态迁移。
第三步:根据第二步的目标物的不同状态迁移采用交互模型预测本车与目标车交互,得到目标车收到本车影响后的预测状态。
以上的交互方式在第一步中可以产生位置约束:
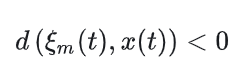
在第三步中产生:
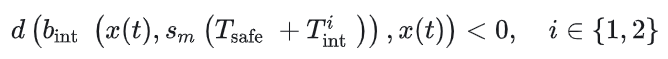
在考虑交互的前提下,目标函数稍作修改,写成:
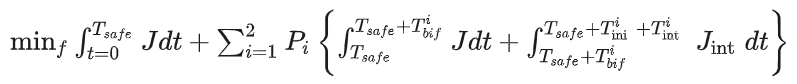
作者只在最后simulation中的V-B-2部分简单说了一下 logistic model交互模型采用NGSIM dataset训练获得。
自动驾驶之心
论文辅导来啦

知识星球交流社区
近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 1831
1831




 到【灌水乐园】发言
到【灌水乐园】发言







