






作者 | 猛猿 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/7461863937
点击下方卡片,关注“自动驾驶之心”公众号
>>点击进入→自动驾驶之心『强化学习』技术交流群
本文只做学术分享,如有侵权,联系删文
在去年的这个时候,我以deepspeed-chat的代码为例,解读了rlhf运作的流程。当时写这篇文章的目的,主要是想让读者在没有RL知识的情况下,能从直觉上快速理解这份代码,以便上手训练和修改。
由于这篇文章侧重“直觉”上的解读,因此有很多描述不严谨的地方。所以去年我就想接着敲一篇PPO理论相关的文章,但是整理自己的笔记真得太麻烦了 ,所以一直delay到今天。
所以今天这篇文章就来做这件事,我的主要参考资料是Sutton的这本强化学习导论。在现有的很多教材中,一般会按照这本导论的介绍方式,从MDP(马尔可夫决策过程)和价值函数定义介绍起,然后按照value-based,policy-based,actor-critic的顺序介绍。但是由于本文的重点是actor-critic,所以我在写文章时,按照自己的思考方式重新做了整理:
我们会先介绍policy-based下的优化目标。
然后再介绍价值函数的相关定义。
引入actor-critic,讨论在policy-based的优化目标中,对“价值”相关的部分如何做优化。
基于actor-critic的知识介绍PPO。
为什么在网络上已经有无数RL理论知识教程的前提下,我还要再写一篇这样类型的文章呢?主要是因为:
作为一个非RL方向出身的人,我对RL的理论知识其实一直停留在“它长得是什么样”,而不是“它为什么长这样”
当我想去探究“它为什么长这样”的时候,我发现最大的难点在各类资料对RL公式符号定义比较混乱,或者写得太简略了。举例来说:
我们在RL会看到大量 [f(x)]这样求期望的形式,但是很多公式会把E的下标省略掉,使人搞不清楚它究竟是从哪里采样,而这点非常重要。
在RL的过程中,混合着随机变量和确定性变量,对于随机变量我们常讨论的是它的期望。可是在有些资料中,经常给出诸如r(s,a)这样的形式,且不带符号说明。乍一看你很难想到它究竟代表某一次采样中确定的即时奖励,还是代表多次采样的即时奖励的期望?诸如此类
最后,这篇文章不算是RL理论教程,它只是我为了串起PPO的脉络,在自己的逻辑体系里记录的一篇笔记。如果读完这篇文章,还是有困惑的朋友,可以阅读我前面链接中给出的Sutton的那本教材,它更适合从0开始学习RL。
一、策略(policy)
策略分成两种:确定性策略和随机性策略。我们用 表示策略的参数。
1.1 确定性策略
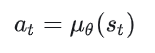
智能体在看到状态 的情况下,确定地执行
1.2 随机性策略
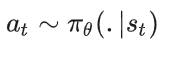
智能体在看到状态 的情况下,其可能执行的动作服从概率分布 (.| )。也就是此时智能体是以一定概率执行某个动作 。
在我们接下来的介绍中,都假设智能体采用的是随机性策略。
二、奖励(Reward)
奖励由当前状态、已经执行的行动和下一步的状态共同决定。
2.1 单步奖励
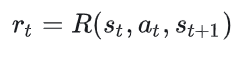
奖励和策略 无关
用于评估当前动作的好坏,指导智能体的动作选择。
2.2 T步累积奖励
T步累积奖励等于一条运动轨迹/一个回合/一个rollout后的单步奖励的累加。
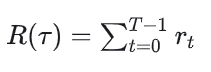
2.3 折扣奖励
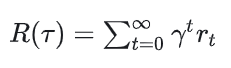
这里 (0,1)。
三、运动轨迹(trajectory)和状态转移
智能体和环境做一系列/一回合交互后得到的state、action和reward的序列,所以运动轨迹也被称为episodes或者rollouts,这里我们假设智能体和环境交互了T次:
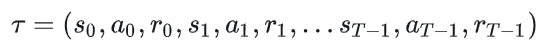
是初始时智能体所处的状态,它只和环境有关。我们假设一个环境中的状态服从分布 ,则有 ( )
当智能体在某个 下采取某个动作 时,它转移到某个状态 可以是确定的,也可以是随机的:
确定的状态转移: = f( , ),表示的含义是当智能体在某个 下采取某个动作 时,环境的状态确定性地转移到
随机的状态转移: P(.| , )
在我们接下来的介绍中,都假设环境采用的是随机状态转移。
四、Policy-based强化学习优化目标
抽象来说,强化学习的优化过程可以总结为:
价值评估:给定一个策略 ,如何准确评估当前策略的价值 ?
策略迭代:给定一个当前策略的价值评估 ,如何据此优化策略 ?
整个优化过程由以上两点交替进行,最终收敛,得到我们想要的最优策略 * 和能准确评估它的价值函数 *。
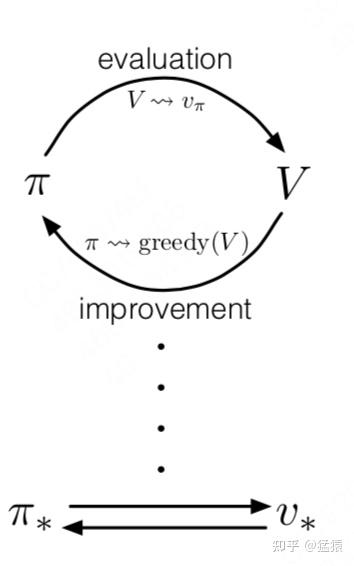
此时,你肯定会想,这是否意味着强化学习过程中一定存在 和 两个实体呢?例如,这是否意味我们一定要训练两个神经网络,分别表示策略和价值评估?答案是否定的:
你可以只有一个价值实体 ,因为它的输入和状态与动作相关(这里我们不区分V和Q,留到后文细说)。这意味着只要我们知道状态空间S和动作空间A, 就可以作用到这两个空间上帮助我们衡量哪个状态/动作的价值最大,进而隐式地承担起制定策略的角色,我们也管这种方法叫value-based。
你可以只有一个策略实体 ,在对策略的价值评估中,我们可以让策略和环境交互多次,采样足够多的轨迹数据,用这些数据去对策略的价值做评估,然后再据此决定策略的迭代方向,我们也管这种方法叫policy-based。
你可以同时有价值实体 和策略实体 ,然后按照上面说的过程进行迭代,我们也管这种方法叫actor-critic,其中actor表示策略,critic表示价值。这是我们本文讨论的重点。
接下来,我们就直接来看policy-based下的强化学习优化目标:
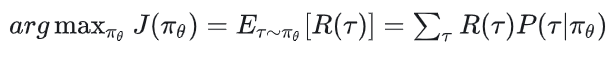
我们来详细解读这个目标:

J( ):
基于策略的强化学习的总目标是,找到一个策略 ,使得它产出的轨迹的【回报期望】尽量高。回报期望表示为 [R( )]。
为什么这里我们讨论的是【回报期望】,而不是某一个具体的回报值?这是因为策略和状态转移具有随机性,也就是对于一个固定的策略,你让它和环境交互若干次,它每次获得的轨迹序列也是不一样的,所以R( )是个随机变量,因此我们讨论的是它的期望。从更通俗的角度来讲,你评价一个策略是否好,肯定不会只对它采样一次轨迹,你肯定需要在足够多次采样的基础上再来评估这个策略。
五、策略的梯度上升
5.1 基本推导
现在我们知道强化学习的总优化目标是:
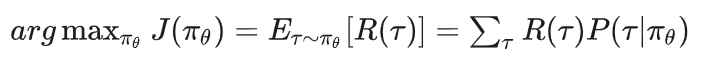
我们据此来计算梯度:
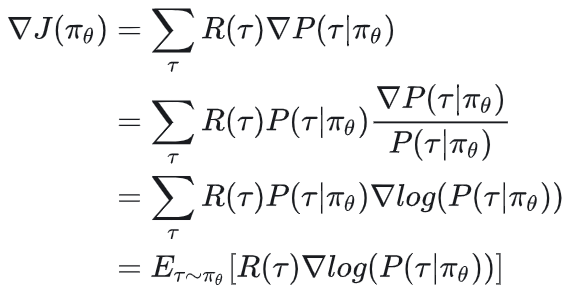
其中,第2行~第3行是因为:
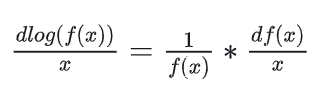
我们知道策略和状态转移都是随机的,同时我们设一条轨迹有T个timestep,则我们有:
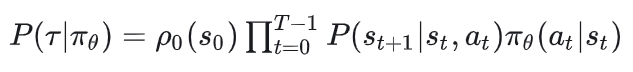
据此我们继续推出:
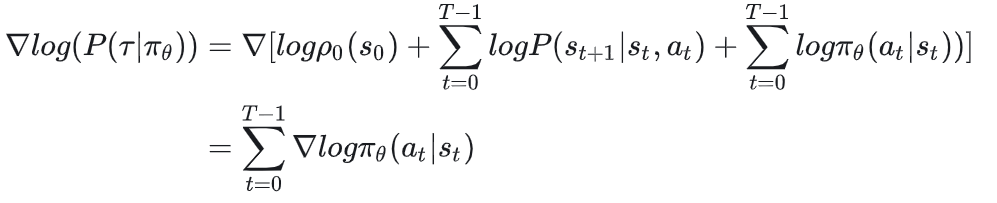
被约去的两项是因为这里我们是在对策略求梯度,而这两项和环境相关,不和策略相关。
综上,最终策略的梯度表达式为:
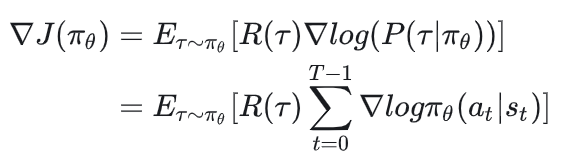
5.2 总结
在基于策略的强化学习中,我们期望max以下优化目标:
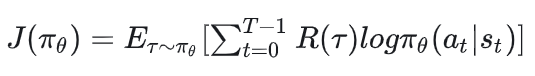
基于这个优化目标,策略 的梯度为:
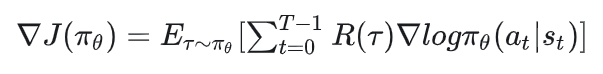
这个梯度表达式有一个简单的直观理解:当R( )越高时,动作 贡献的梯度应该越多,这是因为此时我们认为 是一个好动作,因此我们应该提升 ( | ),即提升在 下执行 的概率。反之亦然。
在实践中,我们可以通过采样足够多的轨迹来估计这个期望。假设采样N条轨迹,N足够大,每条轨迹涵盖 步,则上述优化目标可以再次被写成:
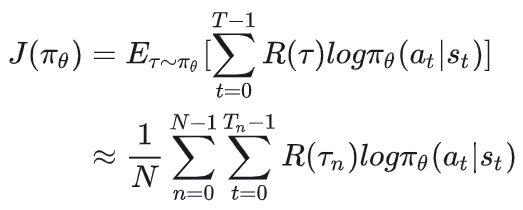
对应的梯度可以被写成:
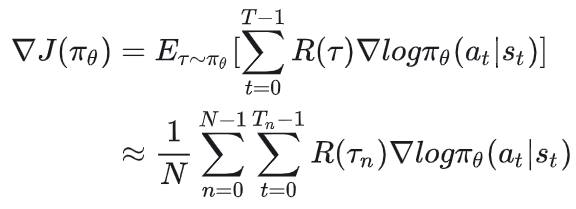
六、价值函数(Value Function)
通过上面的推导,我们知道在强化学习中,策略的梯度可以表示成:
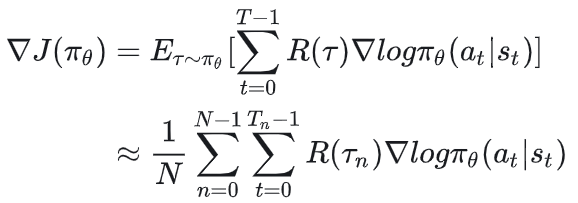
这里R( )表示一整条轨迹的累积奖励或者累积折扣奖励。
当你端详这个公式时,你可能会有这样的疑问:R( )是整条轨迹的奖励,但是 ( | )却是针对单步的。我用整条轨迹的回报去评估单步的价值,然后决定要提升/降低对应 的概率,是不是不太合理呢?例如:
一条轨迹最终的回报很高,并不能代表这条轨迹中的每一个动作都是好的。
但我们又不能完全忽视轨迹的最终回报,因为我们的最终目标是让这个回合的结果是最优的。
综上,在衡量单步价值时,我们最好能在【单步回报】和【轨迹整体回报】间找到一种平衡方式。
有了以上这些直觉,你开始考虑用一个更一般的符号 来表示各种可行的价值函数,你用 替换掉了上面的R( ),这下策略的梯度就变成:
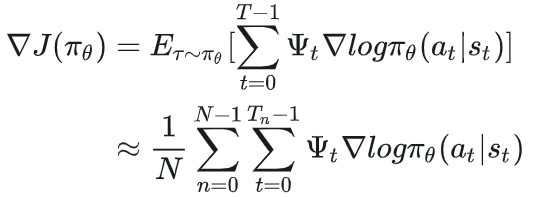
6.1 总述:衡量价值的不同方式
总结来说 可能有如下的实现方式:
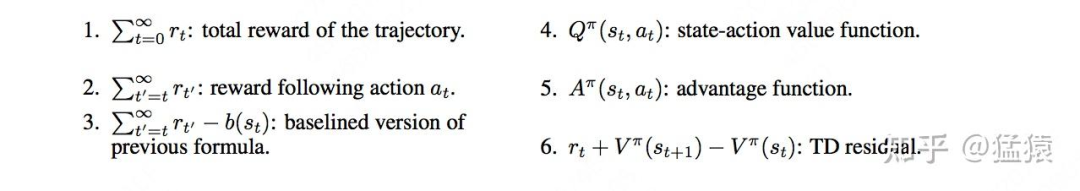
我们来做逐一讲解。
(1)整条轨迹累积奖励/累积折扣奖励
这就是我们前文一直沿用的方法,即:
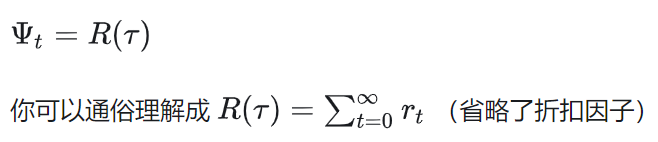
(2)t时刻后的累积奖励/累积折扣奖励
由于MDP的假设,t时刻前发生的事情和t时刻没有关系,t时刻后发生的事情才会受到t时刻的影响,所以我们可以令:
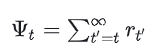
(3)引入基线

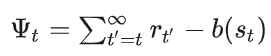
这里基线的实现方式也可以有多种,比如当我们采样了一堆轨迹,我们可以找到这些轨迹中状态为 的数据,求这些数据在(2)下的奖励并做平均(也就是求了个期望)当作基线。

我们沿着(4)~(6)继续来讨论 的可行形式,一种符合直觉的处理方法是:

那么什么叫【执行 带来的回报】和【执行其它动作带来的回报】?
假设你在玩马里奥游戏,你来到了画面的某一帧(某个 )
你在这一帧下有3个选择:顶金币,踩乌龟,跳过乌龟。你现在想知道执行“顶金币”的动作比别的动作好多少。
你先执行了“顶金币”的动作(即现在你采取了某个确定的( , )pair),在这之后你又玩了若干回合游戏。在每一次回合开始时,你都从(这一帧,顶金币)这个状态-动作对出发,玩到游戏结束。在每一回合中,你都记录下从(这一帧,顶金币)出发,一直到回合结束的累积奖励。你将这若干轮回合的奖励求平均,就计算出从(这一帧,顶金币)出发后的累积奖励期望,我们记其为 ( , )。

当优势越大时,说明一个动作比其它动作更好,所以这时候我们要提升这个动作的概率。
通过上面的例子,我们已经引出一些关于价值函数的基本概念了:

所以接下来,我们就从理论的角度,详细展开介绍它们。
6.2 回报

在接下来的讲解中,提到某一个回合中【单步】的奖励,我们说的都是【累积折扣奖励】
6.3 状态价值函数(State-Value Function)
状态价值函数的原子定义如下:
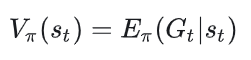
我们先来解释相关的符号:

上面是状态价值函数最原子的定义,我们把这个定义展开,以便更好理解 ( )是如何计算的:

上面这个展开细节帮助我们从理论上理解上面举的例子:从马里奥游戏的某一帧 出发,如何求这一帧的累积回报期望,也就是求这一帧下所有动作的累积回报期望。我们从第4行推导开始讲起:


6.4 动作价值函数(Action-Value Function)
同样,我们先来看动作价值函数的原子定义:
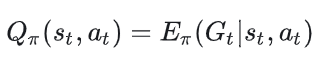
我们来解释相关符号:

6.5 动作价值函数和状态价值函数的互相转换
我们来简单回顾下上面的内容。
状态价值函数的定义为:
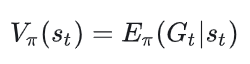
动作价值函数的定义为:
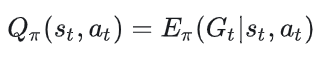
展开状态价值函数的定义,我们得到:
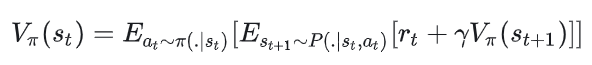
展开动作价值函数的定义,我们得到:
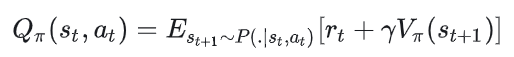
根据这两者的定义展开式,我们得到两者的关系为:
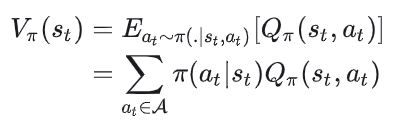
关于V和Q,我们可能在脑海里一直有“V是Q的期望”这样一个模糊的印象,但是却很难做具象化的解读。希望这里通过上面马里奥游戏的例子 + 具体的推导过程,能帮助大家更深入了解V和Q的关系。
6.6 优势函数和TD error

我们展开来讲优势函数,在前面的推导中我们已知:
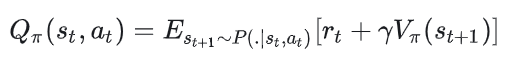

基于这两个式子,我们可以写成优势函数的表达式:
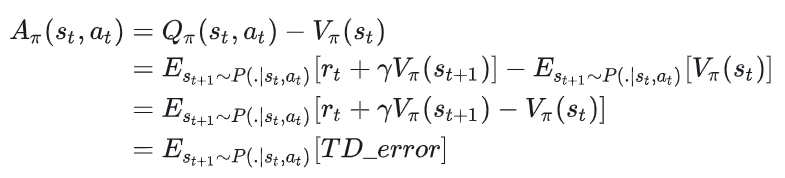
大家发现了吗:

七、Actor-Critic
我们先来回顾之前定义的policy-based下的策略梯度:
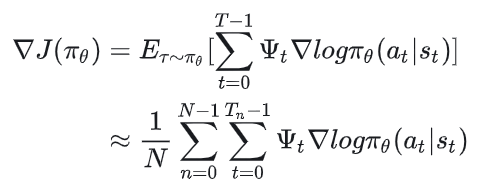
其中,衡量单步价值的 可以有如下几种设计方案:
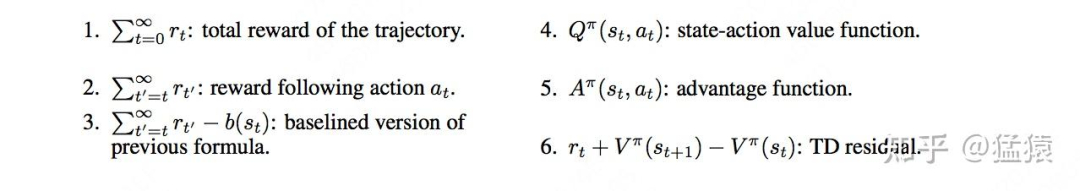


接下来我们来看actor loss和critic loss的具体表达式。
7.1 Actor优化目标
现在我们可以把actor优化目标写成如下形式:
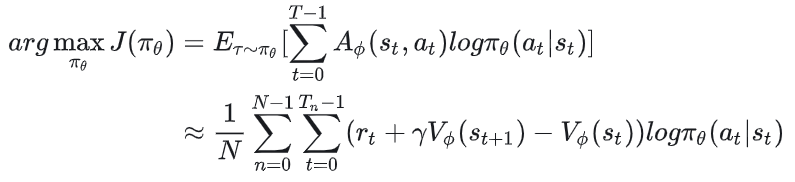

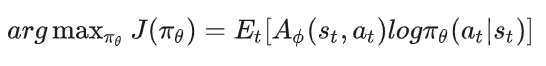
在接下来的表示中,我们都将采用这种形式。
对应的策略梯度前面写过很多遍了,这里就不写出来了。
7.2 Critic优化目标
同理,在单步更新下,我们可以把critic优化目标写成:
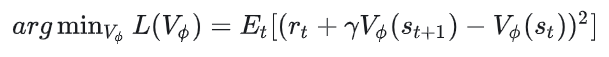
对应的critic梯度这里也略去。
7.3 Actor和Critic之间的关系
关于7.1节中,actor这个优化目标的改写我们已经很熟悉了,但对于7.2中的critic loss你可能还是满腹疑惑,例如:看样子,critic loss是在让优势趋于0,但是如此一来,每个动作的好坏不就都差不多了?那你怎么能选出那个最好的动作呢?
为了解答这个问题,我们先回想第四节中提到的“价值评估->策略迭代”这样一个循环的过程:
价值评估:给定一个策略 ,如何准确评估当前策略的价值 ?
策略迭代:给定一个当前策略的价值评估 ,如何据此优化策略
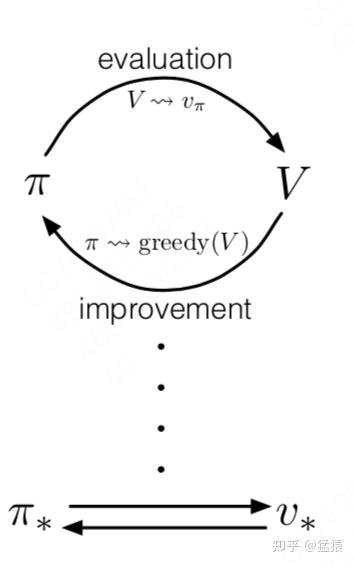
我们结合actor-critic的框架把这个循环的优化过程展开来讲:

我们把以上内容换成比较好理解,但可能不太精确的人话:当我们推动critic loss(优势)趋于0时:
对于actor来说,是推动它找到某个状态下最佳的动作,逐步向 * 拟合
对critic来说,是推动它准确衡量当前策略的价值,逐步向 * 拟合
八、PPO
8.1 朴素Actor-Critic的问题
在理解critic loss为何如此设计的前提下,critic的梯度就比较好理解了,这里我们不做过多解释。我们把目光再次放回actor的梯度上来:
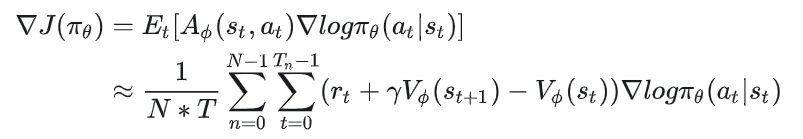

观察这个梯度表达式,我们会发现如下问题:
问题1:每次执行这个梯度更新时,我们都需要对 进行若干次回合采样。我们知道智能体和环境交互的时间成本(fwd)比较高,也就是整个训练过程会比较慢。同时由于采样过程具有随机性,我们可能偶发采样到了一些方差特别大的样本,如果我们直接信任这些样本去做更新,就可能使得更新方向发生错误。

接下来我们就详细来看如何解决这两个问题。
8.2 重要性采样
在朴素的方法中,我们使用 和环境交互若干次,得到一批回合数据,然后我们用这个回合数据计算出来的奖励值去更新 。我们管这个过程叫on-policy(产出数据的策略和用这批数据做更新的策略是同一个)
而现在,为了降低采样成本,提升训练效率,同时更加“谨慎”地更新模型,我们想做下面这件事:

我们从更理论的角度来看待这个off-policy的过程:

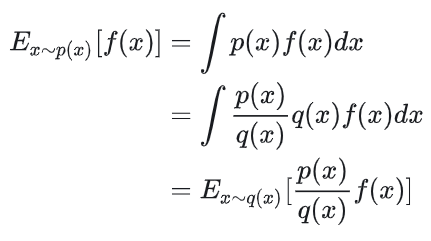

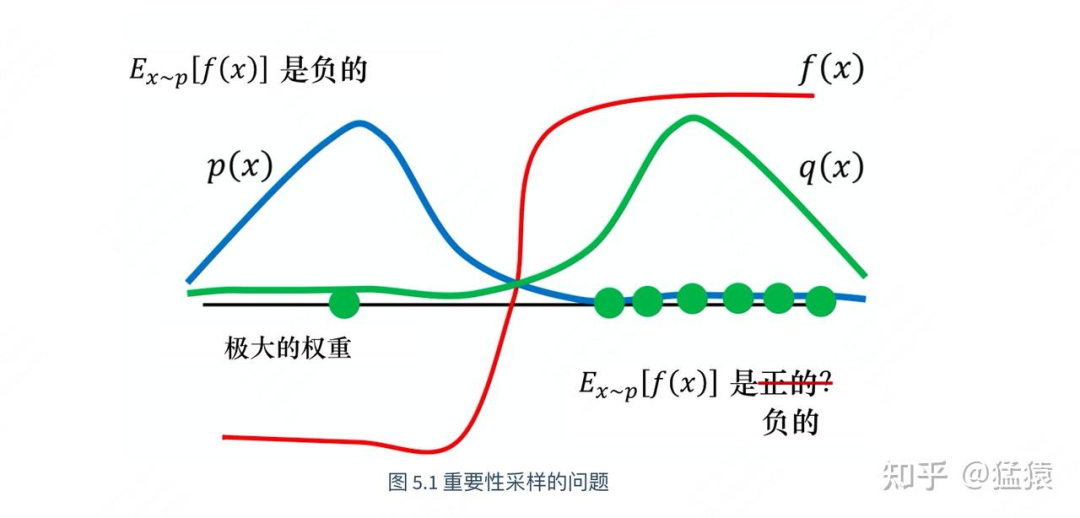
虽然数学上是有办法改写了,但是实际操作中,我们可能遇到p(x)和q(x)分布差异较大的问题。这里我直接引用李宏毅老师的课堂ppt来说明这一点:

知道了重要性采样的过程,现在我们又可以根据它重写我们的优化目标了。
重要性采样前,策略的梯度是:
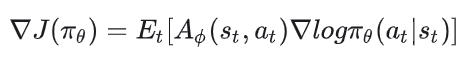
重要性采样后,策略的梯度是:
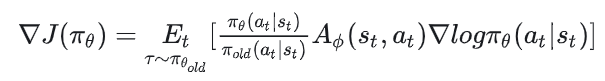
我们根据重要性采样构造了这个新的策略梯度,那么对应的新的actor优化目标就可以从这个策略梯度中反推出来:
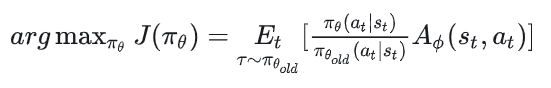

8.3 GAE:平衡优势函数的方差和偏差
再回顾下6.6节的内容:在假设 能正确评估策略 的价值的前提下,我们用TD_error作为优势函数的无偏估计:
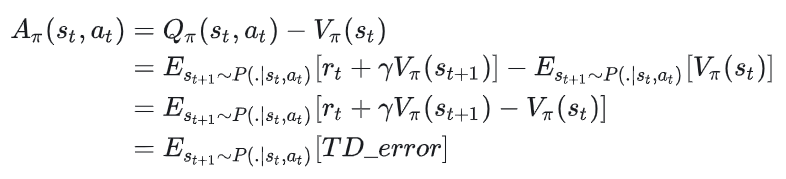
但是,在训练过程中,这个 往往无法完全正确评估出策略 的价值,所以上述这种估计是有偏的,也即如果我们使用TD error去近似优势函数,就会引发系统性偏差。这样讲可能比较抽象,我们来看具象化地解释下。
(1)方差与偏差
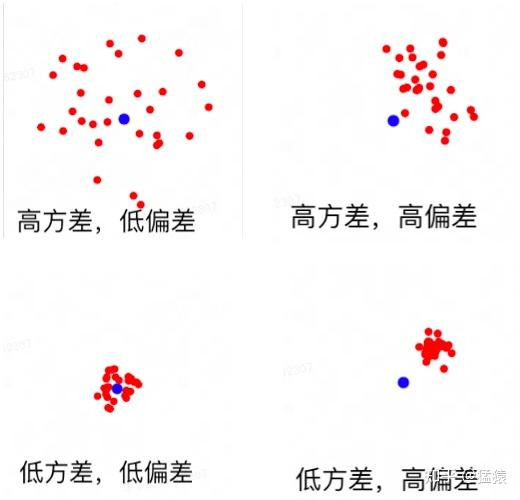
低方差,低偏差:
E(射击点) = 靶心,且射击点密集分布在靶心周围。此时我们随机选一个射击点就能很好代表靶心高方差,低偏差:
E(射击点) = 靶心,但射击点们离靶心的平均距离较远。此时随机一个射击点不能很好代表靶心,我们必须使用足够多的射击点才能估计靶心的坐标高/低方差,高偏差:
E(射击点)!=靶心,无论你做多少次射击,你都估计不准靶心的位置。



(2)GAE



8.4 PPO前身:TRPO



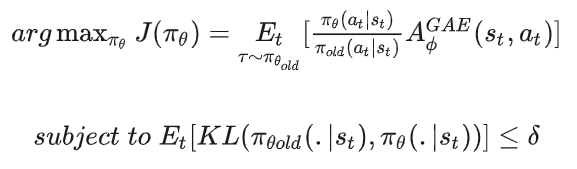
由于这种限制不直接加在J( )中,因此使得整体优化过程变得较为复杂,这就是TRPO的缺陷(关于TRPO的更多细节,这里就不做展开了,大家可以去看paper)
8.5 PPO做法1:PPO-Clip

我们重新来端详引入重要性采样和GAE以后的强化学习优化目标:
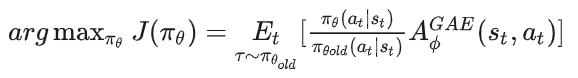


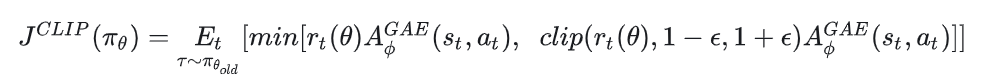
虽然这个公式看起来复杂,但本质上做的就是上面说的clip问题,大家对照着上面的解释看这个公式就好。
8.6 PPO做法2:PPO-Penalty

其中,超参 的调整策略如下:

(PPO论文里的表述和这里又一些不一样,但本质上都是用min和max去动态变更 )
8.7 PPO中的critic loss
在PPO的原始论文中,并没有对critic和actor拆分成两个网络以后的critic loss形式做详细介绍,所以这部分的解读我直接以deepspeed-chat的rlhf实现为例,讲一下critic loss的实现。
我们知道,PPO的更新步骤是:
# 对于每一个batch的数据
for i in steps:
# 先收集经验值
exps = generate_experience(prompts, actor, critic, reward, ref)
# 一个batch的经验值将被用于计算ppo_epochs次loss,更新ppo_epochs次模型
# 这也意味着,当你计算一次新loss时,你用的是更新后的模型
for j in ppo_epochs:
actor_loss = cal_actor_loss(exps, actor)
critic_loss = cal_critic_loss(exps, critic)
actor.backward(actor_loss)
actor.step()
critc.backward(critic_loss)
critic.step()在以上的讲解中,我们已经知道actor是在PPO epoch中使用同一批数据做迭代更新的。但是同时,critic也是在迭代更新的。为什么critic要做迭代更新?因为 是和 挂钩的,如果你的策略参数已经更新了,你必须有一个新的critic来衡量新策略的价值。

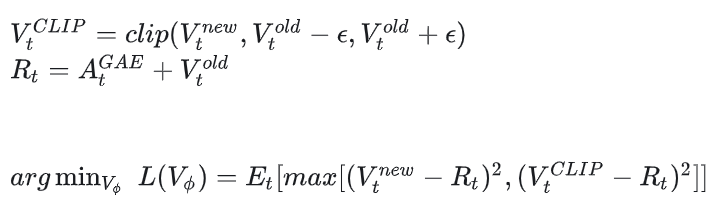
我们来详细解释这个公式的含义:


大家发现了吗,这个critic的优化目标就和我们7.2节中说的critic优化目标是一致的,只不过这里引入了GAE对优势做了指数平滑而已。
那么为什么critic要选择用这个优化目标?答案请看7.3节中的解释。

在本文中,我们从理论上介绍了策略梯度->Actor-Critic -> PPO的理论框架,在下一篇中,我们将会重新结合rlhf的代码,从更加严谨的角度解读这份代码。
九、参考
1、Reinforcement Learning: An Introduction
2、蘑菇书EasyRL
3、各类paper,这里不一一例举
① 自动驾驶论文辅导来啦

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









