



作者 | 大鲸鱼 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/29254068576
点击下方卡片,关注“自动驾驶之心”公众号
>>点击进入→自动驾驶之心『大模型』技术交流群
本文只做学术分享,如有侵权,联系删文
论文标题:TokenSkip: Controllable Chain-of-Thought Compression in LLMs
论文地址:2502.12067v1.pdf
代码开源:https://github.com/hemingkx/TokenSkip
作者单位:香港理工大学
一、问题:为什么大模型「想太多」会变慢?
想象一下,你让ChatGPT解一道数学题,它会在脑海里「自言自语」:
“小明有5个苹果,先买了3个,现在有8个;然后吃掉2个,剩下6个。所以答案是6。”
这个过程叫思维链(CoT)——模型通过一步步推导得出答案。但问题来了:

这就好比:你写作文时,如果必须把“嗯…这里应该…对吧?”之类的内心活动全写出来,交卷时间肯定来不及
二、核心思想:让模型学会「划重点」
TokenSkip的灵感很简单:不是所有token都值得生成!
1. token的重要性天差地别
学霸token:数字(5、3)、公式(5+3=8)、答案(6)。
学渣token:连接词(“所以”“然后”)、重复描述(“我们仔细计算一下”)。
举个栗子 :
原始CoT:
“首先,小明有5个苹果。接着他买了3个,所以现在总共有5+3=8个。然后他吃掉2个,最后剩下6个。”
关键token:5, 3, 5+3=8, 2, 8-2=6, 答案6
冗余token:首先, 接着, 所以, 然后, 最后
2. TokenSkip的终极目标:
保留学霸token,跳过学渣token!从而让模型生成的CoT更精炼,推理速度更快,同时保持正确率。
三、实现方法:三步让模型学会「跳步骤」
Step 1:给每个token「打分」——谁是学霸?
用一个小型模型LLMLingua-2当「判卷老师」,给CoT中的每个token打分(重要性分数)。
训练方式:使用GPT-4为token标注一个二分类标签(重要/不重要),以此训练出一个打分模型,模型输出的概率就是token的得分
如何打分:
高分token:对答案影响大(如数字、公式)。
低分token:可跳过(如连接词)。
Step 2:动态压缩——按需「删废话」
用户指定一个压缩比例γ(比如γ=0.6,保留60%的token),TokenSkip会:
按分数从高到低排序所有token。
保留前60%的高分token,剩下的直接跳过。
压缩过程演示:
原始CoT(10个token):
[首先][小明][有][5][苹果][然后][买][3][所以][总数8]压缩后(6个token,γ=0.6):
[小明][5][苹果][买][3][总数8]
为什么有效:
删掉了首先、然后、所以等低分token。
保留了关键数字和动作(买3)。
Step 3:训练模型——教会它「走捷径」
我们的最终目的是要让LLM学会自动跳token,而现在我们需要使用压缩后的COT来微调(Fine-tuning) 模型。但全量微调成本太高,TokenSkip用了LoRA:
1. 数据准备:

输入格式:
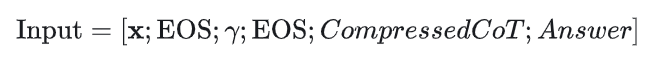
即[问题、分隔符、压缩比率、分隔符、压缩后的思维链、答案],EOS为序列结束符, 以数值形式嵌入[问题] [EOS] 压缩比例0.6 [EOS]
3. 损失函数:
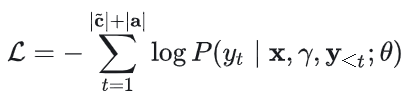
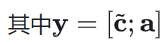
4. LoRA微调:
采用LoRA(Low-Rank Adaptation),仅更新权重矩阵的低秩增量:
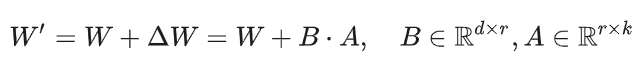
超参数设置:秩r=8,缩放因子 =16,仅调整0.2%的模型参数。
训练成本:
7B模型:2小时(2块3090显卡)
14B模型:2.5小时
(相当于刷两集《繁花》的时间~)
四、效果实测:速度翻倍,答案几乎全对
1. 评估指标

2. 理论分析

3. 实验结果
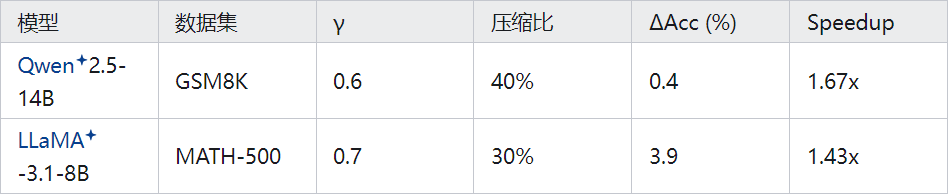
幂律现象:模型规模越大, Acc对 的敏感度越低(见图5)。
注意力稀疏性:压缩后的CoT序列中,注意力权重更集中于关键令牌(可视化见论文图2)。
如果有哪里没看懂,欢迎评论区提问!
① 自动驾驶论文辅导来啦

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵


















 1315
1315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









