



作者 | 梦晨 编辑 | 量子位
点击下方卡片,关注“自动驾驶之心”公众号
>>点击进入→自动驾驶之心『多模态大模型』技术交流群
本文只做学术分享,如有侵权,联系删文
起猛了,Qwen发布最新32B推理模型,跑分不输671B的满血版DeepSeek R1。
都是杭州团队,要不要这么卷。
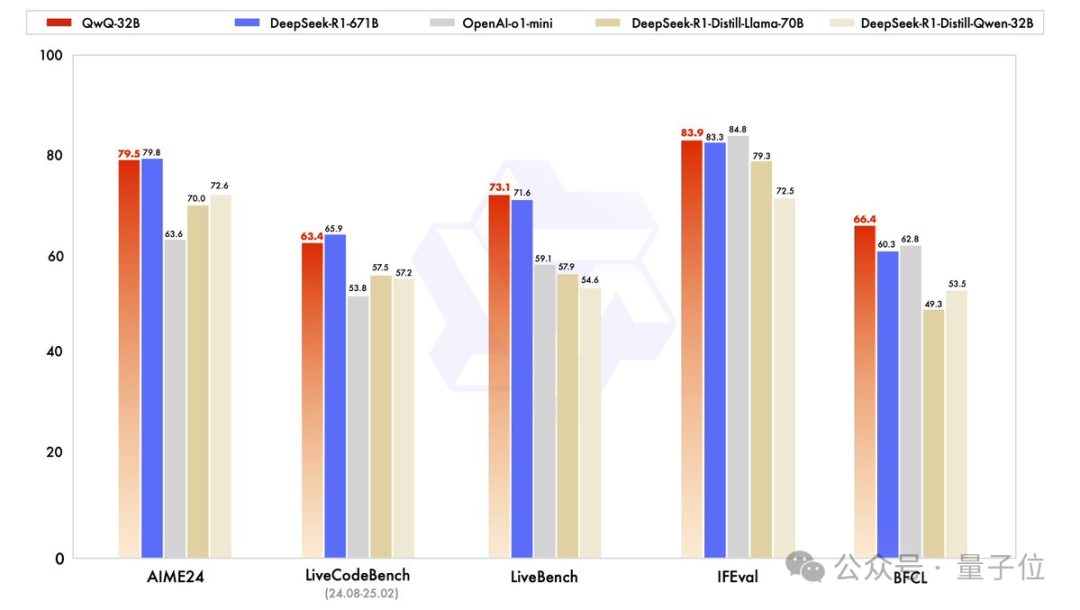
QwQ-32B,基于Qwen2.5-32B+强化学习炼成。

之后还将与Agent相关的功能集成到推理模型中:
可以在调用工具的同时进行进行批判性思考,并根据环境反馈调整其思考过程。

QwQ-32B的权重以Apache 2.0 许可证开源,并且可以通过Qwen Chat在线体验。
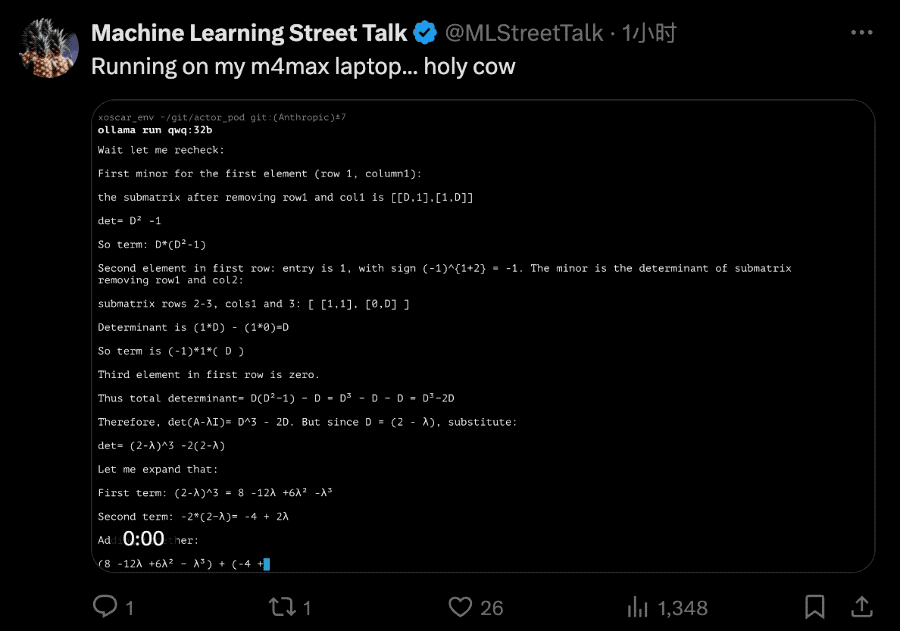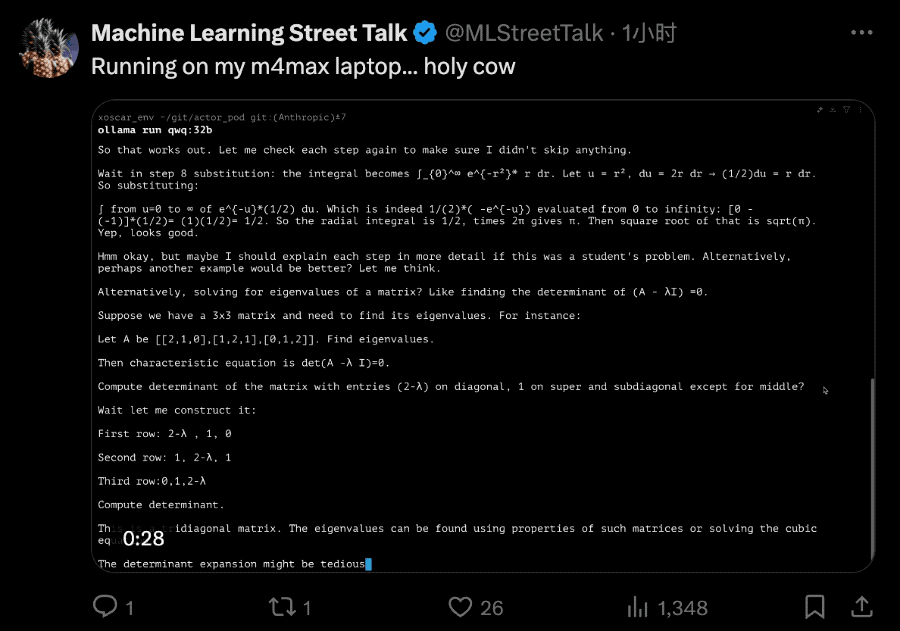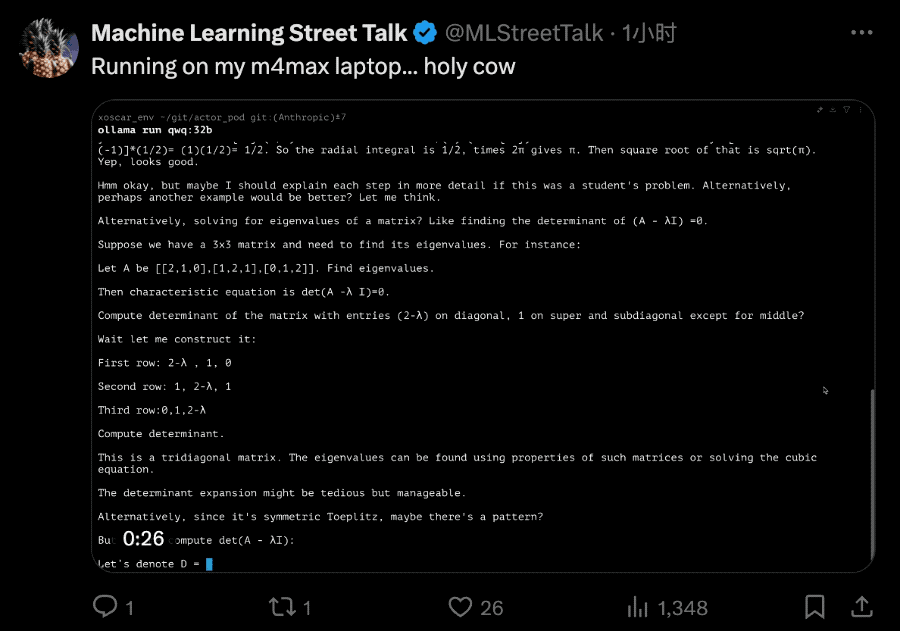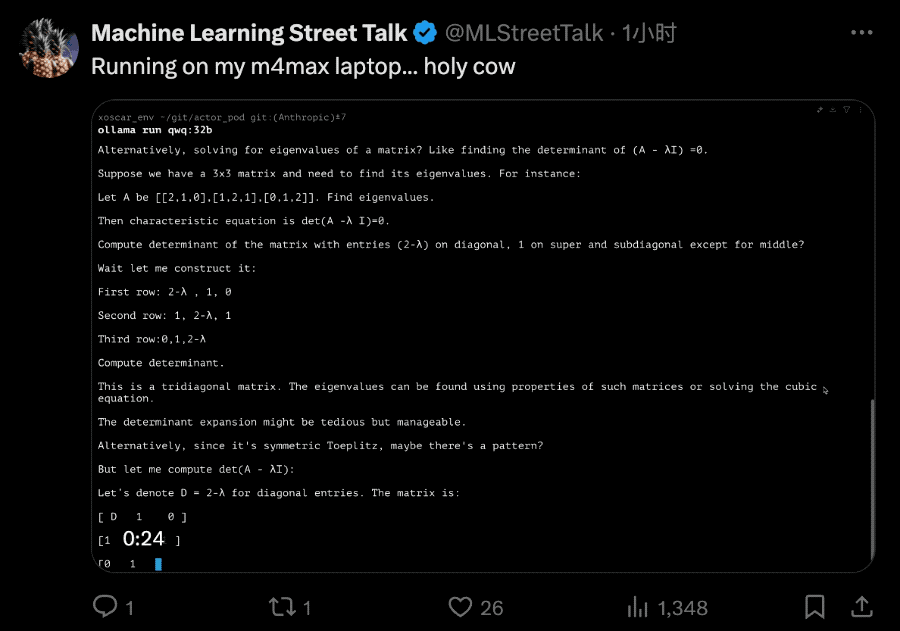
手快的网友直接就是一个本地部署在m4max芯片苹果笔记本上。
也有网友连夜at各大第三方API托管方,赶紧起来干活了。
32B不输DeepSeek R1
目前QwQ-32B还未放出完整技术报告,官方发布页面对强化学习方法做了简短说明:
从一个冷启动检查点开始,实施了由Outcome Based Reward驱动的强化学习(RL)扩展方法。
在初始阶段专门针对数学和编码任务扩展强化学习,没有依赖传统的奖励模型,而是使用一个数学问题准确性验证器来确保最终解决方案的正确性,并使用一个代码执行服务器来评估生成的代码是否成功通过预定义的测试用例。
随着训练轮次的推进,两个领域的性能都呈现持续提升。
在第一阶段之后,为通用能力增加了另一阶段的强化学习,它使用来自通用奖励模型的奖励和一些基于规则的验证器进行训练。
团队发现,这一阶段少量步骤的强化学习训练可以提高其他通用能力的性能,如遵循指令、符合人类偏好以及智能体性能,同时在数学和编码方面不会出现显著的性能下降。
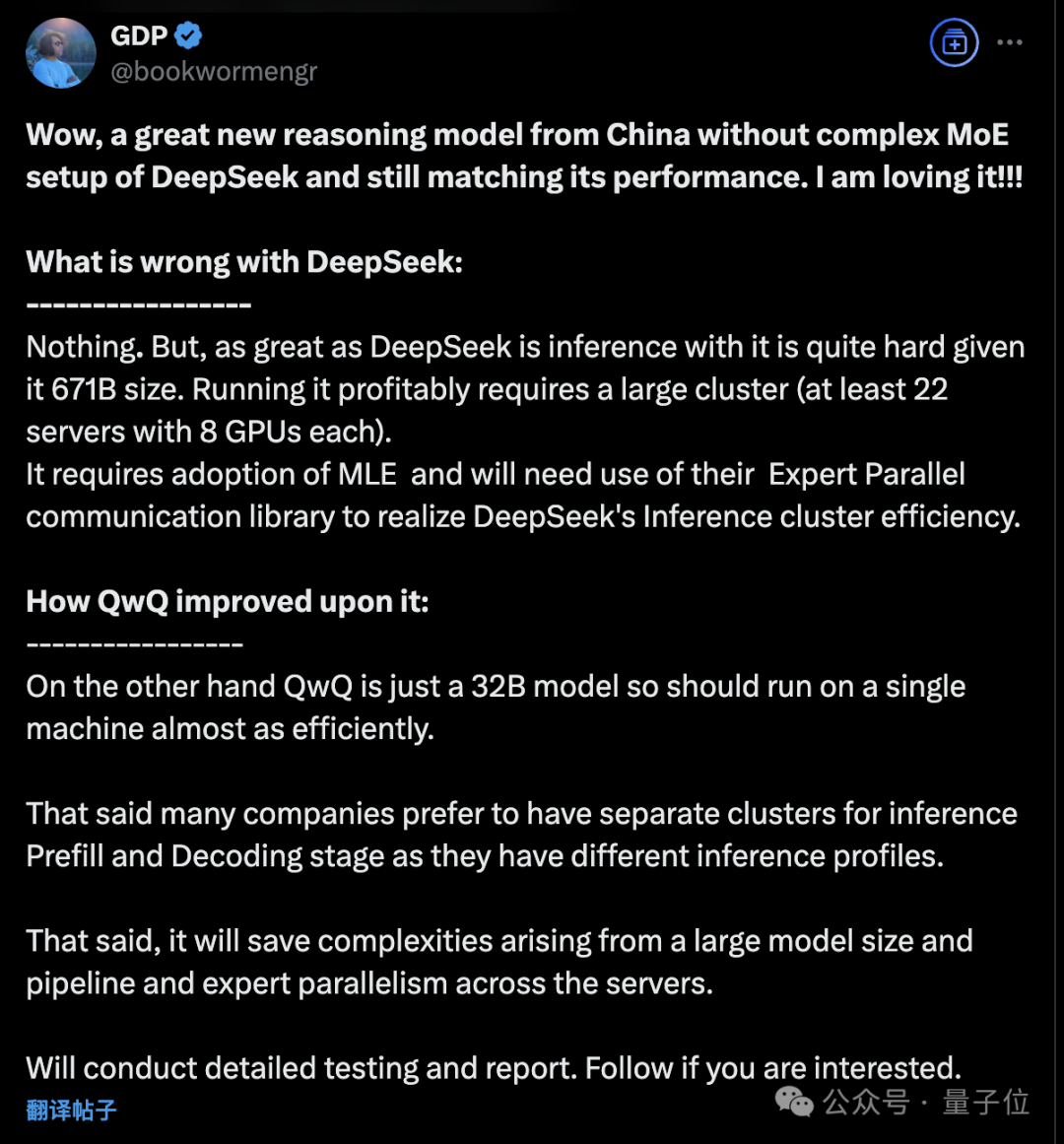
此外在ModelScope页面,还可以看出QwQ 32B是一个密集模型,没有用到MoE,上下文长度有131k。

对此,有亚马逊工程师评价不用MoE架构的32B模型,意味着可以在单台机器上高效运行。
DeepSeek没有问题,很强大,但要托管他且盈利需要一个大型集群,还需要使用DeepSeek最近开源的一系列通信库。
……另一方面QwQ 32B可以减少由流水线并行、专家并行带来的复杂性。
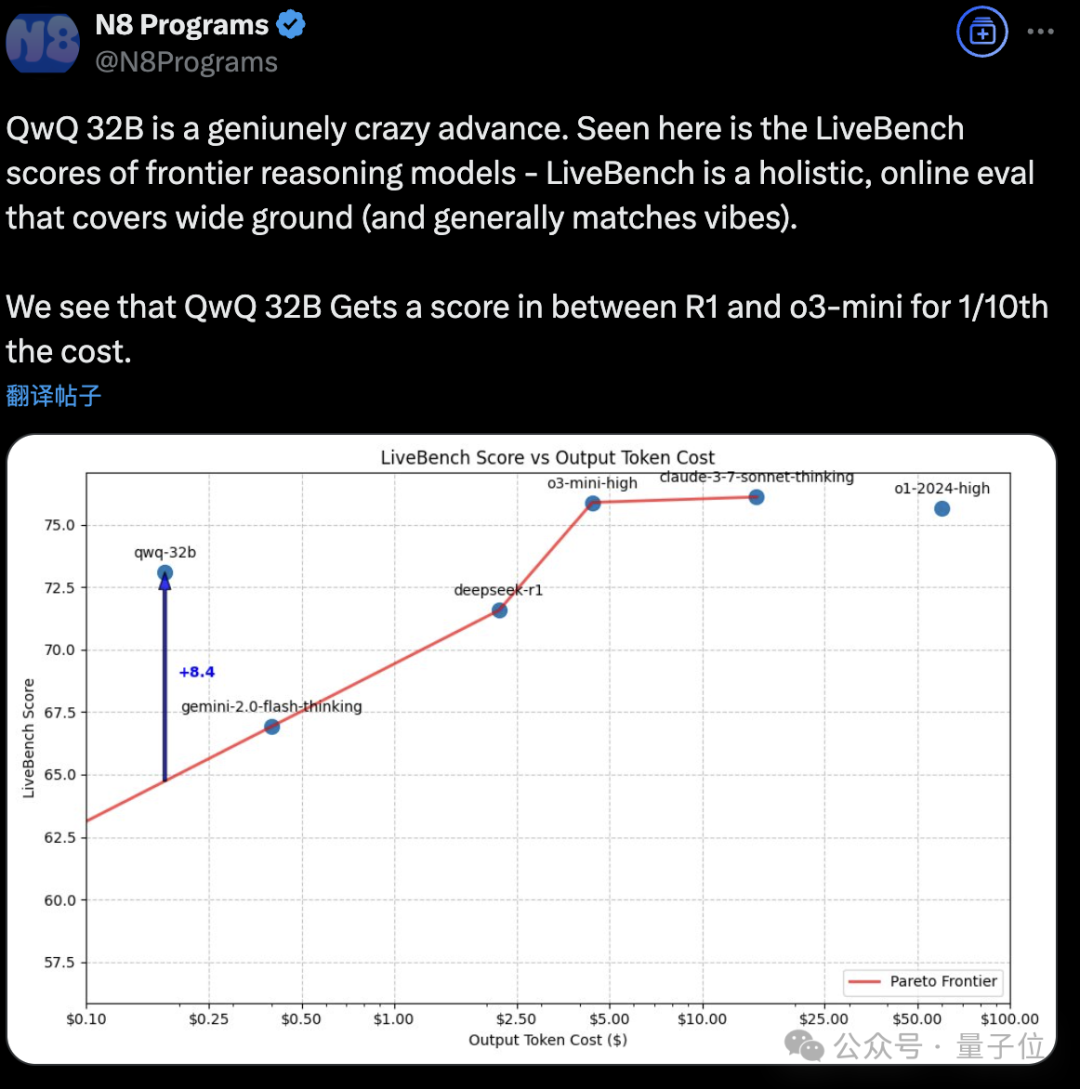
如果将QwQ 32B添加到代码能力与输出token成本的图表中,可以看到它以约1/10的成本达到了DeepSeek-R1与o3-mini-high之间的性能。
在线体验:
https://chat.qwen.ai
https://huggingface.co/spaces/Qwen/QwQ-32B-Demo
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!星球内部近期汇总了2024年自动驾驶领域的所有大模型相关工作,欢迎加入获取全部资料!

更有行业动态和岗位发布!欢迎扫描加入~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









