



作者 | 论文推土机 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/21030160168
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
Ha, D., & Schmidhuber, J. (n.d.). World Models. world model的工作模式和自动驾驶预测决策规划如出一辙,我认为world model是自动驾驶数据驱动方式的终局方案。perception对应V model, 预测对应M model,决策规划则是C model,在感知输入下,world model具有ego action对环境影响的判断能力,可以预测出next Z, 通过ego action的rollouts获得这种自车行为对未来的影响与演化过程,最后找到best policy,这不就是自动驾驶在做的事情吗。
world model
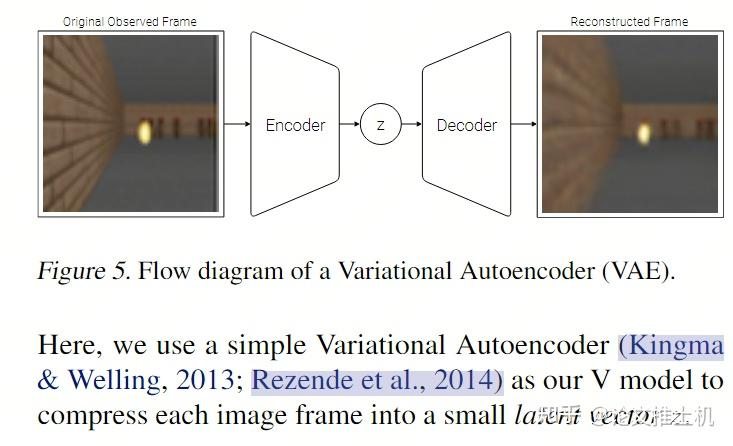
world model的组成有两部分:vision model + memory model. 其中vision model将高维度视觉信息转变成低维度信息,这里通过VAE完成:
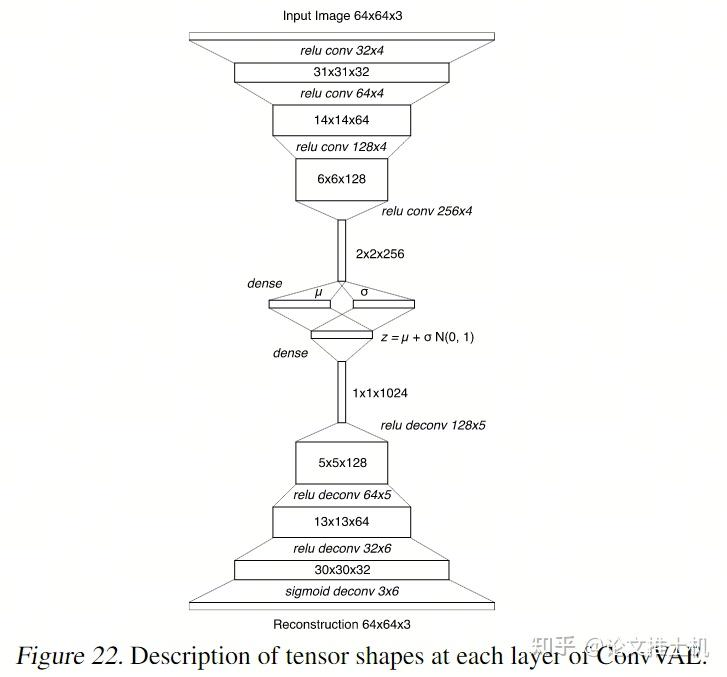
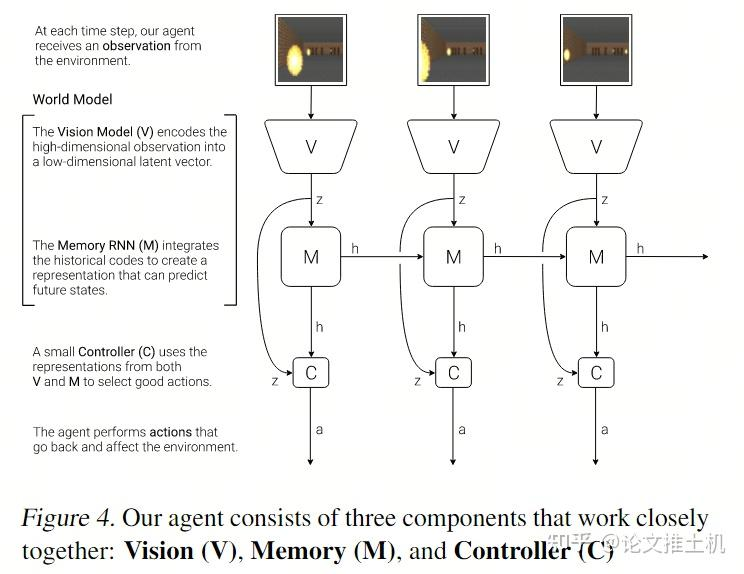
memory model采用了MDN-RNN模型实现,说白了就是混合高斯模型+LSTM. memory模块要维护一个latent state h, 它用于存储历史信息。此外他还要有预测未来的能力:“we also want to compress what happens over time. For this purpose, the role of the M model is to predict the future.”未来的状态记为z:“we train our RNN to output a probability density function p(z) instead of a deterministic prediction of z”。那这里有一个说法,关于z怎么表达,不同文章有不同的做法,比如可以是deterministic的做法,直接就是确定的z, 或者是这里的gaussian distribution用于容纳不确定性,也有dreamer系列的做法,搞成discrete的形式。下图表达了world model的结构,不过这里还不完整,少了action.
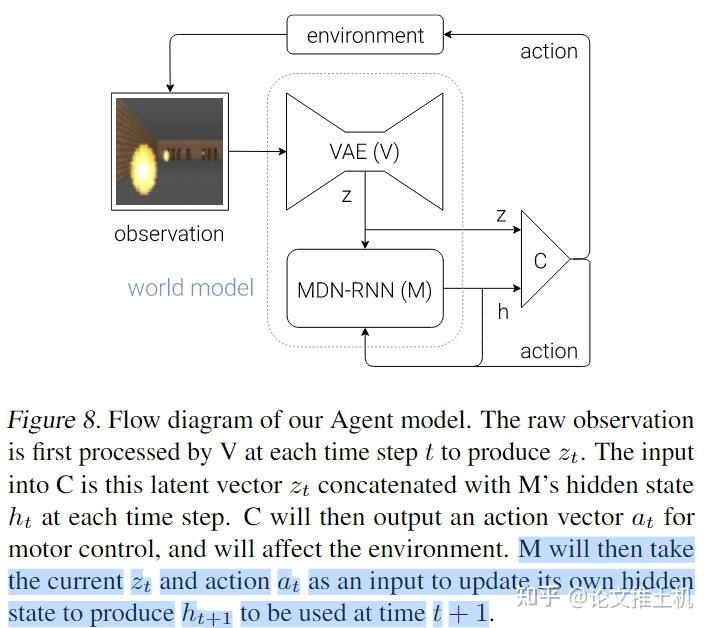
所以更准确的表达是带上action:
训练:
vision, memory and control三部分都是互相独立的,各训练各自的即可:
vision部分就是要训练一个重建任务:
memory部分是要训练一个对未来的预测任务:
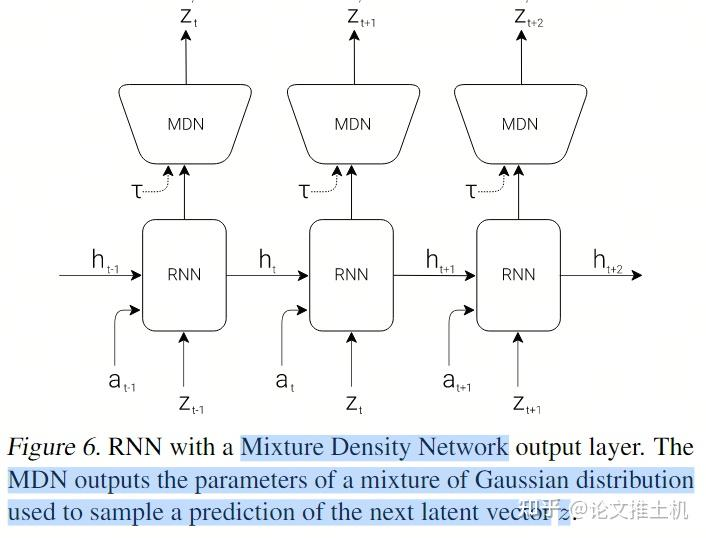
在后面的附录里面还有一个更明确的图:
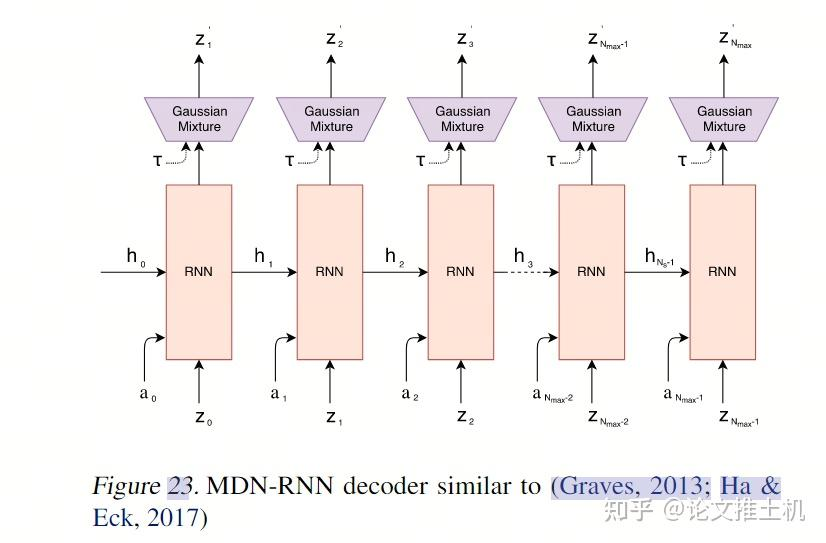
RNN输出两个东西,一个是latent state h: "M will then take the current zt and action at as an input to update its own hidden state to produce ht+1 to be used at time t + 1.", 还有一个未来的预测z。看到这里的温度系数,用于加入噪声,温度系数越大,则对网络施加的干扰越大。文中说到可以“adjust τ to control the uncertainty of the environment generated by M”。
controller就是参数量极小的MLP: = + , 训练过程也很简单,就是在rollouts中找打reward最高的rollout。文章强调:“In our experiments, we deliberately make C as simple and small as possible, and trained separately from V and M, so that most of our agent's complexity resides in the world model (V and M).”就是要用很小的C,来把压力全部给到V and M. 后面实验的参数量也可以看到:
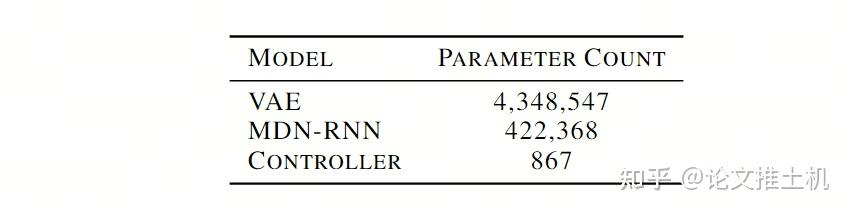
网络的一次循环伪代码如下:
感知输入进行encoding
controller输入z,h 计算action
rnn输入action, z,h更新h

实验
第一个实验式car racing。做了一个ablation, 说这个controller不给他h, 只有当前v行不行,答案是不行:

然后说既然这个world model可以自己预测未来,是不是可以直接在world model的闭环中实现自我学习:“This begs the question – can we train our agent to learn inside of its own dream, and transfer this policy back to the actual environment?”
那必须的,world model不就是用来干这个的嘛:“Since our world model is able to model the future, we are also able to have it come up with hypothetical car racing scenarios on its own. We can ask it to produce the probability distribution of zt+1 given the current states, sample a zt+1and use this sample as the real observation. We can put our trained C back into this hallucinated environment generated by M”,事实上,在下一个实验中就详细论证了这个自我学习过程,然后应用到真实环境中的思路。
VizDoom:
这个实验中强调了以下几点:
温度系数的作用
“we note that it is possible to add extra uncertainty into the virtual environment, thus making the game more challenging in the dream environment. We can do this by increasing the temperature τ parameter during the sampling process of zt+1”,说我们可以通过调整温度系数来在M model的训练过程中引入更多的不确定性,这样可以让模型学的更厉害,“In fact, increasing τ helps prevent our controller from taking advantage of the imperfections of our world model。”然后从后面的实验结果中也可以看到,提升系数可以让模型的虚拟表现和真实表现更加接近:
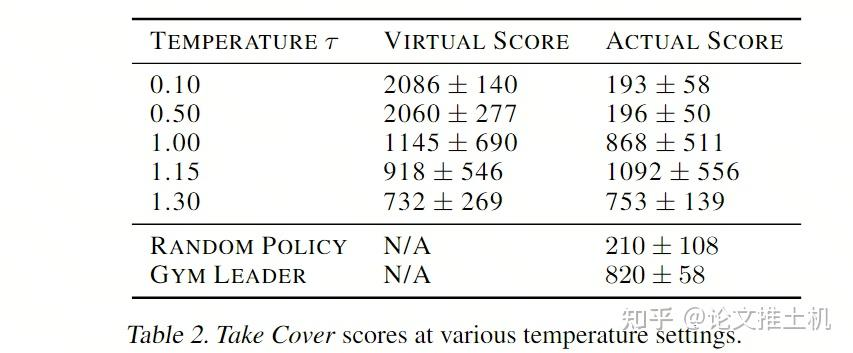
表达能力和决策能力
我们并不需要V model用来完美重建,这个和后面的M and C的表现不完全相关,V只要能够提供信息的压缩即可。“even though the V model is not able to capture all of the details of each frame correctly, for instance, getting the number of monsters correct, the agent is still able to use the learned policy to navigate in the real environment”。
iterative training
在环境比较复杂的时候,可以采用迭代学习策略“We need our agent to be able to explore its world, and constantly collect new observations so that its world model can be improved and refined over time”,因为你不可能直接一下子学到复杂环境的world model, 而我们的自学习过程又需要好的world model给到action-state的未来预测能力,所以这个时候就可以迭代学习:

① 自动驾驶论文辅导来啦

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵


















 9351
9351

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









