



作者 | Sirius 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/7202317478
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
>>点击进入→自动驾驶之心『Transformer』技术交流群
本文只做学术分享,如有侵权,联系删文
之前老喜欢死记硬背transformer的网络架构,虽然内容并不复杂,但是发现这个transformer模块中的positional encoding在死记硬背的情况之下很容易被忽略。为了更好地理解为什么transformer一定需要有一个positional encoding,简单推了一下公式
先说结论:没有Positional Encoding的transformer架构具有置换等变性。
证明如下:
1. 对self-attn的公式推导

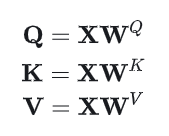
其中的是可训练的权重矩阵。首先计算Query和Key之间的点积,得到注意力权重矩阵:
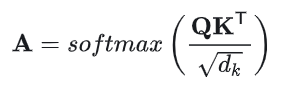
然后计算自注意力输出:
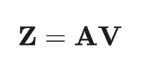
2. 假设对输入进行置换

置换后的Query, Key, Value的公式分别为:
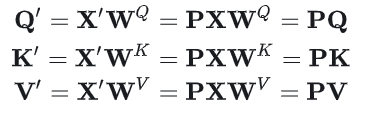
注意力矩阵的计算则变化为:

由于P是置换矩阵,满足=,且P=I,所以:
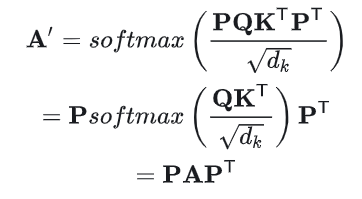
所以最终的输出可以这样写:
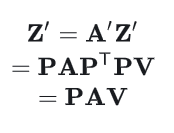
这样就可以证明,transformer架构在没有Positional Encoding计算的情况下具有置换等变性,换句话说,输入序列中元素的排列方式不会影响模型对它们的处理方式,只是输出的顺序相应地改变。
3. 添加Positional Encoding之后的影响
加入Positional Encoding之后,置换后的输入为:
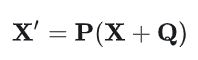
由于P是固定的,加入Positional Encoding之后,输入序列的置换将导致模型的输出发生变化,模型能够区分不用的序列:
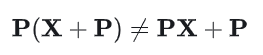
从公式上看,在没有位置编码的情况下,自注意力机制的计算只涉及输入向量的内容,不涉及任何位置信息,且对输入序列的置换是等变的。
加入位置编码后,输入向量包含了位置信息,打破了自注意力机制的置换等变性,使模型能够对序列中的元素位置敏感。
① 2025中国国际新能源技术展会
自动驾驶之心联合主办中国国际新能源汽车技术、零部件及服务展会。展会将于2025年2月21日至24日在北京新国展二期举行,展览面积达到2万平方米,预计吸引来自世界各地的400多家参展商和2万名专业观众。作为新能源汽车领域的专业展,它将全面展示新能源汽车行业的最新成果和发展趋势,同期围绕个各关键板块举办论坛,欢迎报名参加。

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵


















 2729
2729

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









