



作者 | vasgaowei 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/1916948041
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
目前流行的多模态大模型的结构是模块化的,和LLaVA、MiniGPT-4、Qwen-VL和DeepSeek-VL等系列一样,都会有视觉Encoder、Projector、Text Embedding Layer和LLM,最近也有一些工作没有视觉Encoder的多模态大语言模型,今天要介绍的论文《Mono-Internvl: Pushing The Boundaries Of Monolithic Multimodal Large Language Models With Endogenous Visual Pre-Training》提出了一种新的多模态大语言模型结构:Mono-Internvl以及对应的训练策略:endogenous visual expert(EViP)。
arxiv.org/pdf/2410.08202
internvl.github.io/blog/2024-10-10-Mono-InternVL/
huggingface.co/OpenGVLab/Mono-InternVL-2B
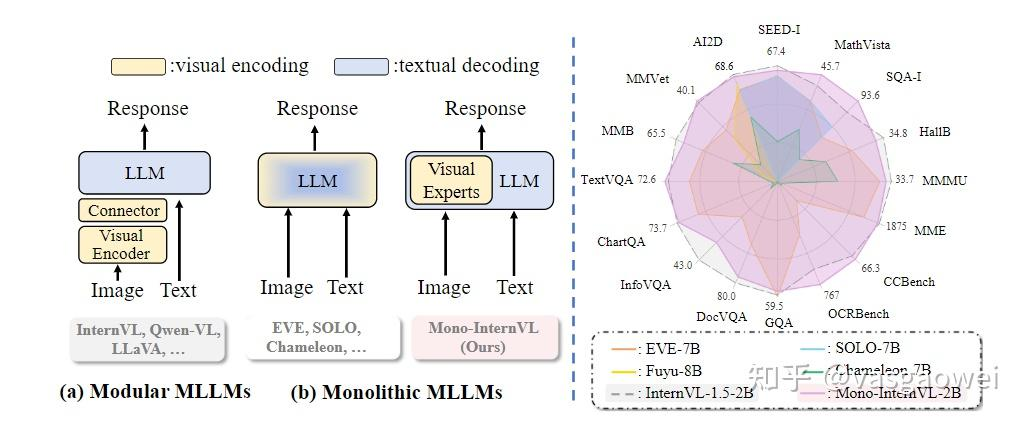
和其他范式的多模态大语言模型的结构如图Fig 1所示,细节见Fig 2.
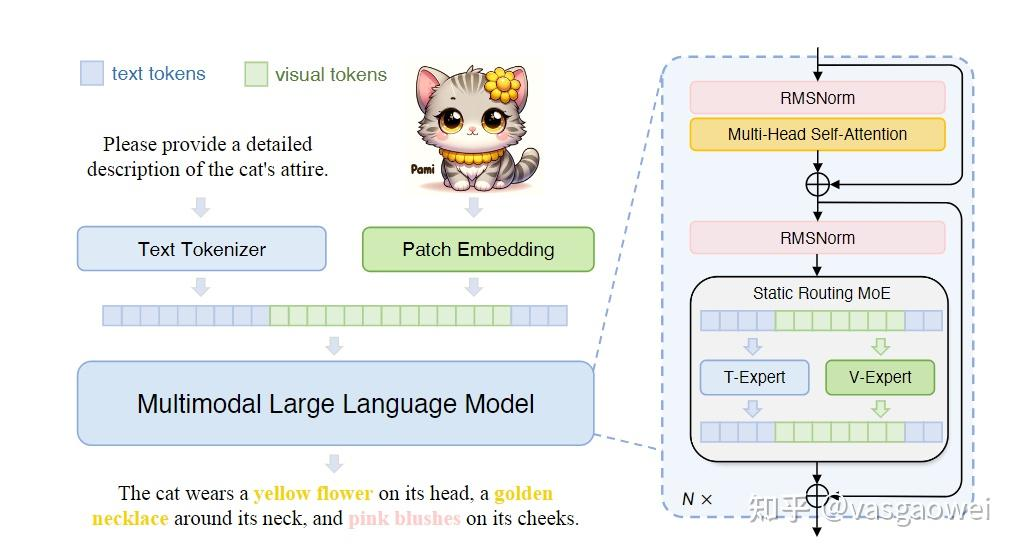

多模态特征蓄力作为LLM的输入,为了处理输入的文本和视觉特征,文中提出了混合专家结构,即
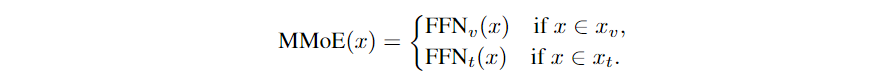
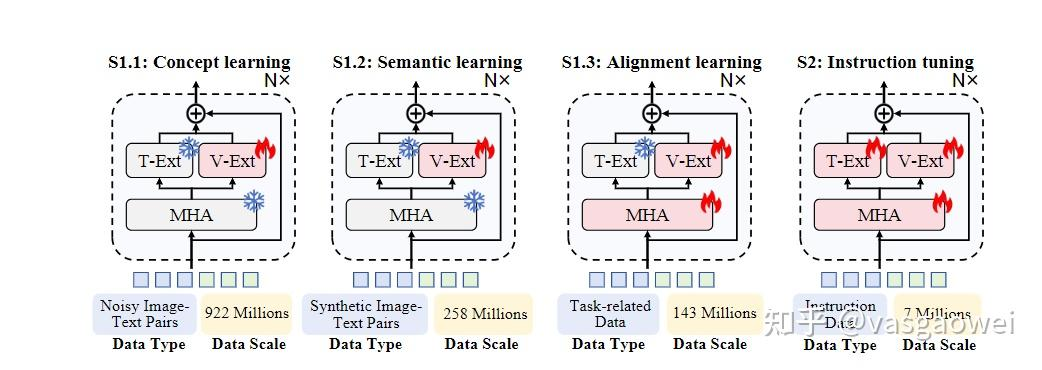
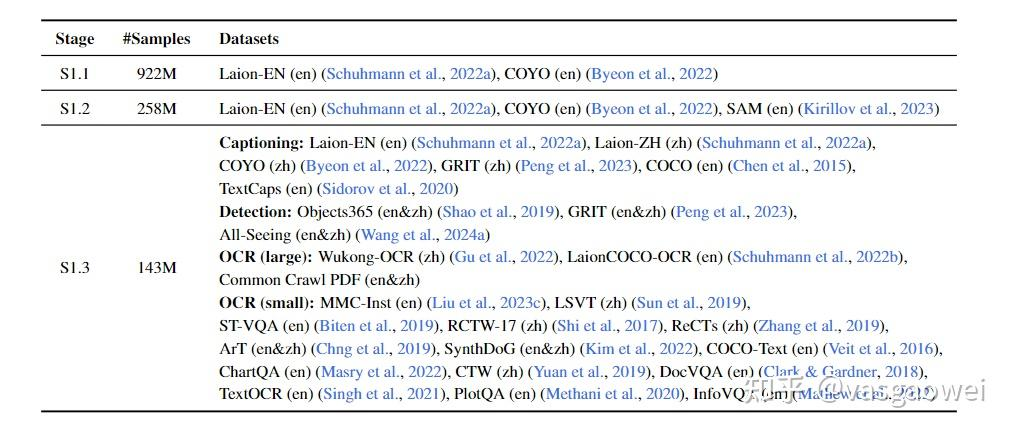
模型的训练也是采用了预训练和指令微调的范式,其中预训练包含三个阶段的训练,训练数据量以及相关的优化参数如图Fig 4所示。
模型预训练阶段分为概念学习(S1.1)、语义学习(S1.2)和对齐学习(S1.3)三个步骤,具体如下:
概念学习(S1.1)
目标:鼓励模型学习基本视觉概念,如对象类别或基本形状。
数据:使用约 9.22 亿个噪声样本,这些样本来自 Laion - 2B 和 Coyo - 700M。
训练策略:采用简单提示进行生成式学习,例如 “为图像提供一个句子的字幕”。为提高训练效率,将视觉标记器的图像块最大数量限制为 1,280。在概念学习期间,整个 LLM的参数保持不变,优化patch embedding和visual experts的参数。
语义学习(S1.2)
目标:在模型理解图像基本概念的基础上,实现更高级的视觉理解。
数据:利用预训练的 InternVL - 8B 为 2.58 亿张图像生成合成字幕,这些字幕包含更复杂的视觉知识且噪声信息较少。
训练策略:与概念学习采用相同的优化策略,但将图像块的最大数量增加到 1,792。
对齐学习(S1.3)
目标:使模型满足下游任务的视觉要求。
数据:从 InternVL - 1.5 的预训练数据中采样 1.43 亿个样本,包括图像字幕、检测和光学字符识别(OCR)数据,其中字幕数据、检测数据和 OCR 数据分别约占总数的 53.9%、5.2% 和 40.9%。
训练策略:利用 InternVL - 1.5 的特定任务提示进行生成式学习,并将图像块的最大数量增加到 3,328。与前两个阶段不同,此阶段还额外优化多头注意力层,以实现更好的视觉 - 语言对齐。
在预训练的各个阶段用到的训练数据如图Fig 5所示。
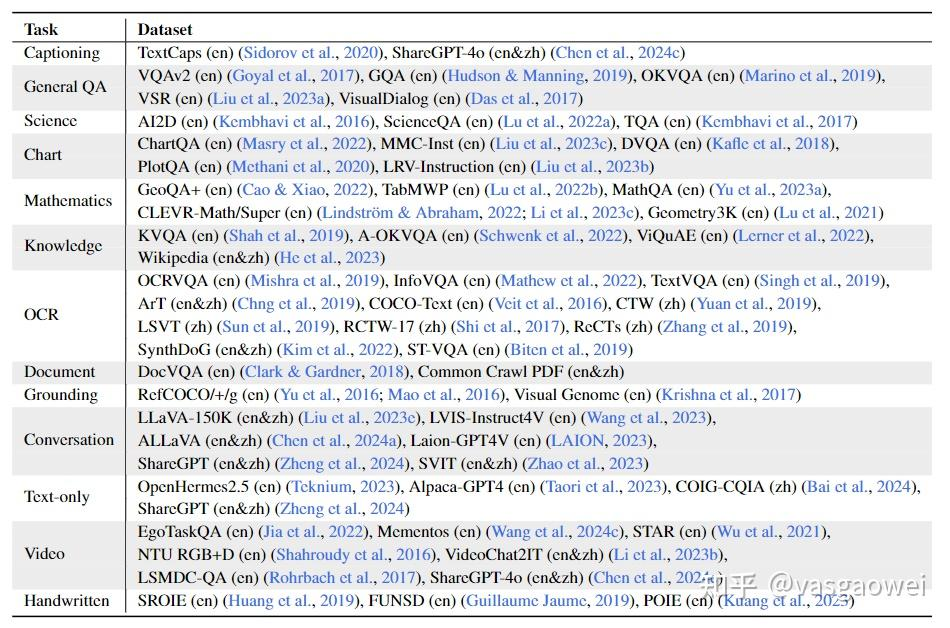
在指令微调的各个阶段用到的数据如图Fig 6所示。
『自动驾驶之心知识星球』欢迎加入交流!重磅,自动驾驶之心科研论文辅导来啦,申博、CCF系列、SCI、EI、毕业论文、比赛辅导等多个方向,欢迎联系我们!

① 全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内外最大最专业,近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵


















 347
347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









