 Transformer注意力图可视化及自动驾驶资源分享
Transformer注意力图可视化及自动驾驶资源分享




作者 | Hao Bai 编辑 | 自动驾驶之心
原文链接:https://www.zhihu.com/question/439389563/answer/3217326241
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
泻药。自从DINO被提出后,注意力图的可视化瞬间成为热点。这篇tutorial就来讨论一下训练完Transformer后,如何可视化注意力图。典型的注意力图例子如下图:

DINO首先提出了一种方法。对于ViT的第 l 层的第 k 个头,首先计算出自注意力矩阵:
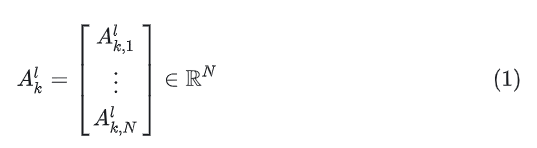
其中
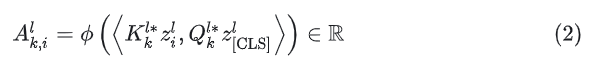
其中 为softmax函数, d 为内积, Q,K为输入 X 的线性变换,为第 l 层第 i 个token的表示。
这个式子的意思是,取出某一层中的一个token,计算这个token的仿射与[CLS] token的仿射间的相似度。算出这一层中每个token的相似度后,对全层做softmax,就可以获得每个token与[CLS] token的相对相似度。由于在ViT中token在一开始tokenization的时候就被flatten过了,所以这里的 z 都是长度为 N 的向量。最后得到的 就是一个标量。为什么这里是呢?这个操作相当于拿着[CLS]这个token的vector representation去一个database里面搜索,找到第 i 个token对应的词条的分数。
因为每个 都是标量,所以自注意力矩阵的形状是一个长度为 N 的向量。我们逆一下tokenize过程,就相当于reshape成一个 的矩阵。这个矩阵的大小就等于输入图像的patch数。因此这里每个patch的长度不能太大,否则图中的patch数会很小,导致可视化粒度太大。仔细观察上图,大概一行有64个patch,出来的粒度还可以,所以总体的可视化效果还是比较好的。
CRATE提出,将 Q,K都替换成同一个矩阵 U 之后,ViT本身很差的segmentation能力瞬间涌现了出来。一个demo可以玩:https://colab.research.google.com/drive/1rYn_NlepyW7Fu5LDliyBDmFZylHco7ss?
上图中的最右边一列就是ViT,最左边一列就是CRATE。下图里还有一些例子:
『自动驾驶之心知识星球』欢迎加入交流!重磅,自动驾驶之心科研论文辅导来啦,申博、CCF系列、SCI、EI、毕业论文、比赛辅导等多个方向,欢迎联系我们!

① 全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内外最大最专业,近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵


















 7450
7450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









