



点击下方卡片,关注“具身智能之心”公众号
作者 | 具身智能之心 编辑 | 具身智能之心
本文只做学术分享,如有侵权,联系删文
写在前面
现代机器学习系统依赖于大型数据集来实现广泛的泛化能力,这在机器人学习中往往构成挑战,因为每个机器人平台和任务可能只有小型数据集。通过在多种不同类型的机器人上训练单一策略,机器人学习方法可以利用更广泛且更多样化的数据集,这反过来又能提高泛化能力和鲁棒性。然而,在多机器人数据上训练单一策略具有挑战性,因为机器人的传感器、执行器和控制频率可能差异很大。本文提出了CrossFormer,这是一种可扩展且灵活的基于Transformer的策略,能够利用来自任何实体的数据。我们在迄今为止规模最大、最多样化的数据集上训练CrossFormer,该数据集包含20种不同机器人实体的90万条轨迹。论文证明,相同的网络权重可以控制截然不同的机器人,包括单臂和双臂操控系统、轮式机器人、四旋翼无人机和四足机器人。与以往的工作不同,我们的模型无需手动对齐观测或动作空间。在现实世界中进行的大量实验表明,我们的方法性能与为每个实体量身定制的专业策略相当,同时显著优于以往跨实体学习的最先进技术。
更多具身智能内容,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球,这里包含所有你想要的。
一些介绍
近年来,机器学习领域的许多成功都得益于在越来越多样化和多任务的数据上训练通用模型。例如,曾经由特定任务方法处理的视觉和语言任务,现在由能够跨任务迁移知识的通用视觉语言模型更有效地执行。同样,在机器人领域,近期的数据聚合工作使得能够在跨多个实体、任务和环境收集的机器人数据上训练通用策略成为可能。这些通用策略通过迁移视觉表征和技能,其性能超过了仅使用目标机器人和任务数据训练的专用策略。除了正向迁移带来的好处外,训练通用跨实体策略还最大限度地减少了为每个机器人设计和调整策略架构所需的工程量。然而,训练通用机器人策略具有独特的挑战性,因为机器人系统在相机视角、本体感受输入、关节配置、动作输出和控制频率等方面可能存在很大差异。在训练大规模跨实体策略的初步尝试中,通常仅限于单个机械臂或地面导航机器人,这些机器人可以通过单个相机视角和相对于基座或末端执行器的相对路径点动作来控制。要进一步提高这些策略能够控制的实体的多样性,需要一个支持根据任意数量的相机视角或本体感受观测进行条件设置,并预测任意维度动作的模型架构。
遵循先前的工作,我们采用序列建模方法来进行跨实体模仿学习。提出了一个基于Transformer的策略,通过将输入和输出转换为序列来支持可变观测和动作。我们将这种方法扩展到用单个策略控制迄今为止最多样化的实体集合,包括单臂和双臂机器人、地面导航机器人、四旋翼无人机和四足机器人。
使用提出的Transformer策略,只需将观测值标记化并排列成序列,就可以在具有任意数量相机视角或感知传感器的机器人数据上进行训练。同时,可以预测任意维度的动作,关键是不需要手动对齐不同实体的动作空间。对于每种动作类型,我们将一组动作读出tokens插入到输入tokens序列中。然后,将相应的输出嵌入传递到特定于动作空间的头部,以生成正确维度的向量。我们的策略可以接受以语言指令或目标图像形式的任务,从而允许用户为给定实体选择最自然的任务模态。
本文主要贡献是在迄今为止规模最大、最多样化的机器人数据集上训练的跨实体机器人策略,该数据集包含90万条轨迹和20个不同的实体。我们的策略可以控制具有不同观测和动作类型的机器人,从具有本体感受传感器和12个关节的四足机器人到具有3个相机和14个关节的双臂机器人。在大量的现实世界实验中,发现我们的策略与仅在目标机器人数据上训练的相同架构的性能相当,同时也优于每个设置中的最佳先前方法,这表明我们的架构能够吸收异构机器人数据而不会发生负迁移,同时性能与为每个机器人量身定制的最先进专业方法相当。此外,我们还发现我们的方法在跨实体学习方面优于最先进的方法,同时减轻了手动对齐观测和动作空间的需求。
相关工作
早期关于跨实体机器人策略学习的研究已经探索了多种技术,包括基于实体明确或学习到的表示进行条件设定、领域随机化和适应、模块化策略或基于模型的强化学习。通常,这些先前的研究项目规模较小,仅在模拟环境中进行评估,或仅使用少量机器人数据训练策略以控制少数机器人完成几项任务。
一些先前的工作试图通过使用来自单个机器人实体的大量数据来扩大机器人学习的规模,这些数据是自主收集的,或通过人类远程操作收集的。我们解决了在包含多种不同类型机器人的更广泛机器人数据上训练策略所面临的挑战。其他先前的工作使用来自多个机器人的数据进行训练,但要求每个机器人具有相同的观测和动作空间。例如,Shah等人使用以ego为中心的相机视角和二维路径点动作,在多个导航机器人上训练了一个策略,而RT-X模型则使用第三人称相机视角和7自由度末端执行器位置动作,在单个机械臂上进行了训练。本文的方法不需要数据具有共同的观测和动作空间,因此可以同时控制具有不相交传感器和执行器集合的机器人,例如机械臂和四足机器人。
已经有一些大规模的研究尝试在具有不同观测和动作空间的机器人数据上训练单一策略。Octo可以在具有与预训练期间所见不同的观测和动作的机器人上进行微调。然而,Octo仅使用来自单个机械臂的数据进行预训练,并未探索在更多异构数据上的联合训练。Reed等人和Bousmalis等人提出了一种灵活的基于Transformer的策略,该策略可以处理预训练期间不同的观测和动作空间。他们证明了他们的策略可以控制具有不同动作空间的机械臂,包括4自由度(4-DoF)、6自由度(6-DoF)、7自由度(7-DoF)和14自由度(使用三指手)。
本文探索了增加单个策略可以操作的实体和环境多样性的挑战。除了增加我们可以控制的机械臂实体的数量(例如高频双臂机械臂)之外,还展示了导航和四足行走,并在广泛的真实世界环境中进行了评估,而他们将评估限制在标准化的笼子中。我们还通过比较有无跨实体联合训练的策略来明确评估跨实体的迁移能力,而他们的重点是自主ego改进。
与我们的工作最相关的是Yang等人的研究,他们研究了操控和导航数据之间的迁移。然而,他们的重点是利用这样一个事实:导航中的以自我为中心的运动看起来与操控中来自手腕相机的以ego为中心的运动相似,并且他们手动对这两个实体中的动作进行了对齐。相反,我们的重点是训练一种可以控制超出机械臂和地面导航机器人的实体的策略,包括那些其观测和动作空间无法转换为通用格式的实体。CrossFormer是第一个在四个不同的动作空间(单臂操控、地面导航、双臂操控和四足行走)上进行联合训练的方法,同时没有任何观测空间限制或动作空间对齐,同时在每个机器人上保持最先进的性能。
训练通用、跨实体的策略需要多机器人数据集,并且已有一些工作致力于收集此类大规模跨实体数据集。特别是,Open Cross-Embodiment数据集(OXE)汇集了150万集机器人数据,而我们则在90万轨迹的子集上进行了训练。这里注意到,Octo和RT-X模型也在OXE数据集上进行了训练,但它们仅使用了包含单个机械臂的子集。此外,本文还使用了GNM导航数据集和DROID(大规模Franka机器人操控)数据集,以及为本项目收集的Go1四足机器人和ALOHA双臂数据。
设计跨实体策略
在多实体机器人学习中,主要挑战在于处理广泛变化的观测空间和动作空间,以及机器人系统在控制频率和其他方面的差异。机器人系统可能具有不同数量的相机视图或本体感受传感器,并且它们可能由各种不同的动作表示来控制,包括关节角度、笛卡尔位置和电机扭矩。为了将数据标准化为通用格式,一些先前关于训练跨实体策略的工作忽略了某些观测类型(例如在操控中的手腕视图或第三人称视图)或跨机器人对齐动作空间。相反,我们遵循其他先前的工作[9, 10, 6],将跨实体模仿学习视为序列到序列问题,并选择基于Transformer的策略架构,该架构可以处理不同长度的序列输入和输出。
由于其序列性质,Transformer策略能够通过将它们序列化为平面序列来编码来自每个实体的所有可用观测类型。同样,我们可以解码可变长度的动作,这使我们能够为每个实体使用最佳动作类型。使用这种灵活的输出,我们还可以预测大小可变的动作块。动作分块提高了动作的时间一致性,并减少了累积误差,这对于高频精细操控尤为重要。综上所述,Transformer主干网络和动作分块使我们的策略能够控制从具有20Hz关节位置控制的双臂ALOHA系统,到具有5Hz二维航点控制的地面和空中导航机器人等各种机器人。
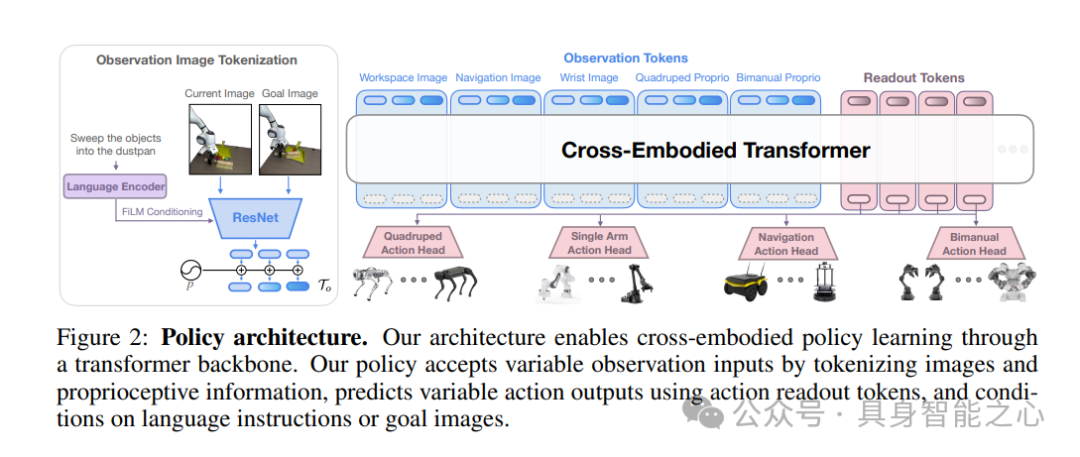
从高层次来看,本文的Transformer策略遵循了先前在多模态数据上训练Transformer的工作。观测和任务规范通过特定模态的分词器进行分词,组装成词序列,并输入到所有实体共享的因果、仅解码器的Transformer主干网络中。然后,将输出嵌入分别输入到每个实体类别的独立动作Head中,以生成相应维度的动作。架构概述如图2所示。
1)Training data
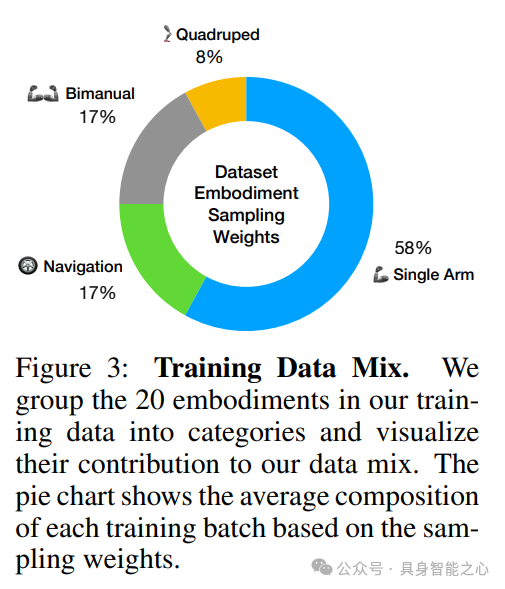
训练数据混合涵盖了20种不同的机器人实体,这些实体在观测空间、动作空间和控制频率上差异很大。我们从Octo使用的Open Cross-Embodiment数据集中的单臂操控子集开始。然后,添加了DROID Franka操控数据集、在两个机构收集的7000条ALOHA数据(称为ALOHA-multi-task)、来自GNM数据集的60小时导航数据、Go1四足机器人25分钟的行走数据(称为Go1-walk),以及在我们自己实验室收集的200条额外Franka数据(称为Franka-tabletop)。将与每个评估设置最相关的数据集分类为目标数据集,并在训练期间相对于其他数据集对其赋予更高的权重。目标数据集包括用于WidowX评估的BridgeData、用于ALOHA评估的ALOHA-multi-task、用于导航评估的GNM、用于四足机器人评估的Go1-walk,以及用于Franka评估的Franka-tabletop。我们通过在模拟中训练RL专家策略来收集Go1数据。有关训练数据混合,请参见图3;
2)对可变观测类型和任务规范进行分词
训练跨实体策略的第一步是创建输入序列。机器人训练数据中的轨迹是由一系列时间步组成的,每个时间步包含图像观测I、本体感受观测P和一个动作。来自每个实体的数据可能每个时间步的相机视角数量不同,并且可能包含或不包含本体感受观测。为了创建输入序列,首先定义一个观测历史长度k,并将每条轨迹分割成长度为k的段,。然后,根据观测的模态对其进行分词。图像通过ResNet-26编码器处理,生成一个特征图,该特征图沿空间维度展平并投影到词嵌入大小。本体感受观测则直接投影到词嵌入大小。除了观测序列外,策略还接受任务规范。对于跨实体控制而言,重要的是,我们的策略可以接受以语言指令l或目标图像g形式的任务规范。在某些设置下,如导航,任务更自然地以图像目标的形式指定,而在其他设置下,如操控,任务则更容易用语言指定。语言指令与图像观测一起使用FiLM进行处理。目标图像在与当前图像沿通道维度堆叠后,再输入到图像编码器中。
由于训练数据包含单臂操纵器、双臂操纵器、四足机器人和地面导航机器人的数据,因此本文的策略支持以下观测类型的任何子集的调节:(1)工作空间图像:在操纵设置中采用第三人称相机视角。(2)导航图像:在导航设置中采用第一人称相机视角。(3)手腕图像:在操纵设置中采用手腕安装的相机视角。(4)四足本体感受:四足机器人的关节位置和速度估计。(5)双臂本体感受:双臂操纵设置中的关节位置。
为了最大化跨实体的迁移,我们对相同类型的相机视角共享图像编码器权重。因此,例如,在单臂和双臂操纵设置中,工作空间图像都由相同的ResNet图像编码器处理。总共使用了四个图像编码器:一个用于操纵设置中的工作空间视角,一个用于地面导航机器人的第一人称视角,两个用于操纵设置中的手腕相机视角。在输入分词后,我们得到一个观测词序列,其中L和M分别表示图像和本体感受观测的词数量。
3)预测可变长度的动作
在创建输入序列后,下一步是使用Transformer处理输入序列,以预测每个实体合适维度的动作。我们采用带有block级因果注意力掩码的Transformer,使得观测词只能关注同一或先前时间步t的观测词。遵循先前的工作,在输入词序列中每个时间步的观测词之后插入特殊的读出词R。这些读出词只能关注先前的观测词,因此它们作为预测动作的便捷表示。最终的输入序列为,其中N表示读出词的数量。将输入词序列传递给Transformer以获得嵌入序列,然后对与读出词对应的嵌入应用动作Head以产生动作。动作Head有几种可能性,过去的工作已经探索了使用L1或L2损失的回归、使用交叉熵损失的分类或扩散。这选择预测连续动作并使用L1作为损失,因为这在先前的高频双臂操纵工作中取得了成功。因此,动作Head简单地将读出词嵌入投影到动作维度。对于一些实体,我们预测一系列顺序动作。先前的工作表明,动作分块可以改善策略性能,这对于控制频率较高的实体至关重要,因为累积误差会迅速增加。由于我们的动作Head将读出词投影到动作维度大小,因此为每个实体的读出词数量与动作分块大小相匹配。本文的策略有4个动作Head,产生以下类型的分块动作:(1)单臂笛卡尔位置:一个7维动作,表示末端执行器和夹爪驱动的笛卡尔位置相对变化。预测4个动作的分块,并在5-15Hz的频率下在单臂机器人上执行。(2)导航路径点:一个2维动作,表示相对于机器人当前位置的路径点。预测4个动作的分块,并在4Hz的频率下在导航机器人上执行。(3)双臂关节位置:一个14维动作,表示双臂的关节位置。预测100个动作的分块,并在20Hz的频率下在双臂机器人上执行。(4)四足关节位置:一个12维动作,无分块预测,表示腿的关节位置。仅预测1个动作,并在20Hz的频率下在四足机器人上执行。动作分块大小取自每个机器人设置中的先前工作。

4)训练技巧
在实际操作中,我们会对某个具体实例中缺失的观测值进行掩码处理,以确保每个批次元素都包含所有类型的观测值和所有读出词组,并且这些词组在上下文窗口中占据固定位置。或者,为了提高内存效率,观测词和读出词可以紧密排列,以去除填充并适应观测类型较少的实例所需的更多上下文时间步。这是先前工作中采用的一种策略。然而,如果不将观测词和读出词类型固定在上下文窗口中的特定位置,模型将需要仅根据观测值来推断实例,以预测正确类型的动作(而不是依赖于读出词的位置嵌入)。对于一些实例,其观测值可能看起来相似(例如,仅使用手腕摄像头的导航和操纵),因此这种设计可能需要向词序列添加前缀以指示实例。
本文的Transformer主干网络具有12层、8个注意力头、2048维的多层感知机(MLP)以及512的词嵌入大小。总的来说,加上ResNet-26图像编码器和动作Head,模型共有1.3亿个参数。使用在ImageNet上预训练的权重来初始化ResNet-26编码器。使用的context窗口大小为2135个词,这可以容纳5个时间step的context,同时包含所有观测词组和读出词组。我们发现,在导航任务上取得良好性能需要5个时间step的观测历史,并且使用此context长度不会对其他实例的性能产生负面影响。以512的bs大小训练了30万个iter,在TPU V5e-256 pod上耗时47小时。使用了AdamW优化器、逆平方根衰减学习率计划、0.1的权重衰减和1.0的梯度裁剪。应用了标准的图像增强技术。
实验与评测
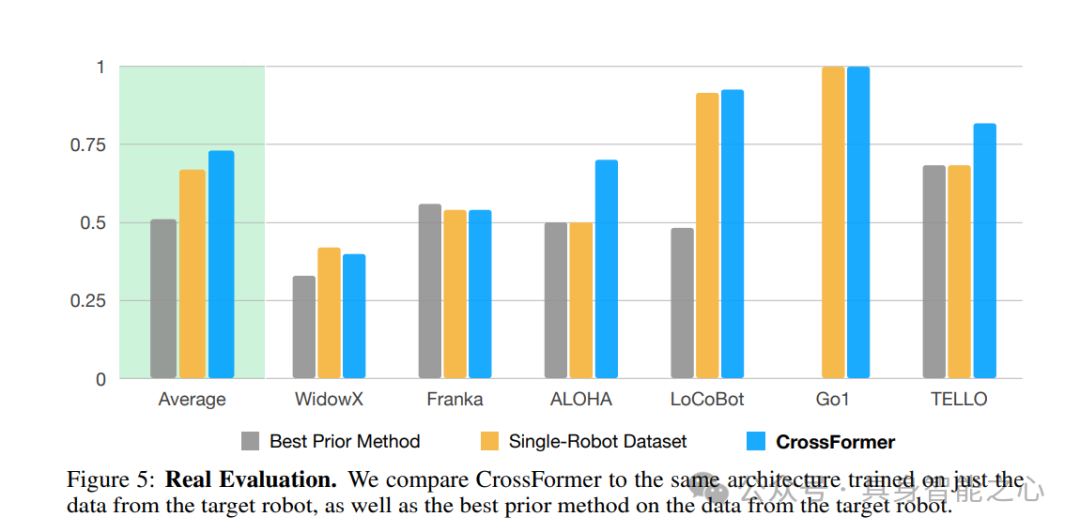
将CrossFormer与仅在目标机器人数据上训练的相同架构以及目标机器人数据上表现最佳的先前方法进行了比较。
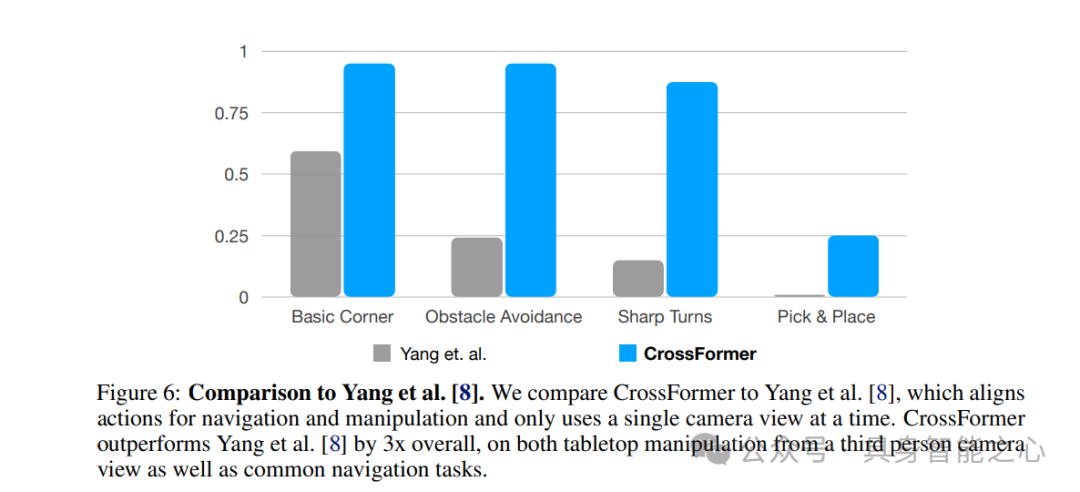
与Yang等人[8]的比较。我们将CrossFormer与Yang等人[8]的方法进行了比较,后者对导航和操作动作进行了对齐,并且每次仅使用一个摄像头视图。无论是在第三人称摄像头视角下的桌面操作任务上,还是在常见的导航任务上,CrossFormer的整体性能都比Yang等人[8]的方法高出3倍。
总结下
CrossFormer是一种可扩展且灵活的Transformer策略,它是在迄今为止最大且最多样化的数据集上训练的,该数据集包含20种不同机器人实体的90万条轨迹。本文展示了一种原则性方法,来学习一种单一策略,该策略可以控制截然不同的实体,包括单臂和双臂操纵系统、轮式机器人、四旋翼无人机和四足机器人。结果表明,CrossFormer的性能与为单个实体量身定制的专业策略相当,同时在跨实体学习方面显著优于当前最先进的技术。然而,本文的工作也存在局限性,结果尚未显示出实体之间的显著正向迁移。我们预计,随着在包含更多实体的更大机器人数据集上进行训练,将看到更大的正向迁移。另一个局限性是,我们的数据混合使用了手工挑选的采样权重,以避免在包含许多重复片段的数据集上过度训练,以及在与我们评估设置最相关的数据上训练不足。原则上,随着模型规模的扩大,策略应该能够同样良好地适应所有数据,而无需任何数据加权。最后,由于需要大模型来适应大型多机器人数据集,模型的推理速度可能成为限制因素。在这项工作中,我们成功地将策略应用于高频、细粒度的双手操纵任务,但随着模型规模的扩大,可能无法控制这些更高频率的实体。未来的硬件改进将有助于缓解这一问题,但还需要进一步研究使用大型模型控制高频机器人的技术。未来的工作还可以包括探索使实体之间实现更大正向迁移的同时保持我们架构灵活性的技术、数据整理技术,以及纳入更多样化的数据源,如次优机器人数据或无动作的人类视频。希望这项工作能够为更高效地从不同机器人实体的经验中学习和迁移知识的通用且灵活的机器人策略打开大门。
参考
[1] Scaling Cross-Embodied Learning: One Policy for Manipulation, Navigation, Locomotion and Aviation.
“具身智能之心”公众号持续推送具身智能领域热点:
【具身智能之心】技术交流群
具身智能之心是首个面向具身智能领域的开发者社区,聚焦大模型、机械臂、双足机器人、四足机器人、感知融合、强化学习、模仿学习、规控与端到端、仿真、产品开发、自动标注等多个方向,目前近60+技术交流群,欢迎加入!扫码添加小助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

【具身智能之心】知识星球
具身智能之心知识星球是国内首个具身智能开发者社区,主要关注具身智能相关的数据集、开源项目、具身仿真平台、大模型、视觉语言模型、强化学习、具身智能感知定位、机器臂抓取、姿态估计、策略学习、轮式+机械臂、双足机器人、四足机器人、大模型部署、端到端、规划控制等方向。扫码加入星球,享受以下专有服务:
1. 第一时间掌握具身智能相关的学术进展、工业落地应用;
2. 和行业大佬一起交流工作与求职相关的问题;
3. 优良的学习交流环境,能结识更多同行业的伙伴;
4. 具身智能相关工作岗位推荐,第一时间对接企业;
5. 行业机会挖掘,投资与项目对接;


















 1645
1645

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









