



点击下方卡片,关注“具身智能之心”公众号
作者 | 具身智能之心 编辑 | 具身智能之心
本文只做学术分享,如有侵权,联系删文
原标题:Manipulate-Anything: Automating Real-World Robots using Vision-Language Models
论文链接:https://robot-ma.github.io/MA_paper.pdf
项目链接:https://robot-ma.github.io/
作者单位:华盛顿大学 圣巴勃罗天主教大学 艾伦人工智能研究所 NVIDIA

MANIPULATE-ANYTHING解决了什么?
大规模项目如RT-1以及社区广泛参与的项目如Open-X-Embodiment已经为扩展机器人演示数据的规模做出了贡献。然而,仍然存在提升机器人演示数据质量、数量和多样性的机会。尽管视觉-语言模型已经被证明可以自动生成演示数据,但它们的应用仅限于具有特权(privileged)状态信息的环境中,并且需要手工设计的技能,同时只限于与少量物体实例的交互。本文提出了MANIPULATE-ANYTHING,一种用于真实世界机器人操作的可扩展自动生成(scalable automated generation)方法。与以往的工作不同,本文的方法无需特权(privileged)状态信息或手工设计的技能,能够在真实环境中操作任何静态物体。在两个设置下对本文的方法进行了评估。首先,MANIPULATE-ANYTHING 成功生成了所有7个真实世界任务和14个仿真任务的轨迹,显著优于现有方法如VoxPoser。其次,MANIPULATE-ANYTHING生成的演示数据相比人类演示数据或VoxPoser、Scaling-up以及Code-As-Policies生成的数据,能够训练出更稳健的行为克隆策略。我们相信,MANIPULATE-ANYTHING 可以成为一种可扩展的方法,既能为机器人生成数据,也能在零样本环境下解决新任务。
更多具身智能内容,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球,这里有多有你想要的。
MANIPULATE-ANYTHING的设计
现代机器学习系统的成功从根本上依赖于其训练数据的数量、质量和多样性。大规模互联网数据的可用性使视觉和语言领域取得了显著进展。然而,数据匮乏阻碍了机器人领域的类似进展。人类演示数据的收集方法难以扩展到足够的数量或多样性。像RT-1这样的项目展示了收集了17个月的高质量人类数据的实用性。其他研究则开发了用于数据收集的低成本硬件。然而,这些方法都依赖于昂贵的人类数据收集过程。
自动化数据收集方法在多样性上难以实现足够的扩展。随着视觉-语言模型(VLMS)的出现,机器人领域涌现了许多利用VLMS来指导机器人行为的新系统。在这些系统中,VLMS将任务分解为语言计划或生成代码以执行预定义技能。尽管这些方法在仿真中取得了一定成功,但在现实世界中的表现不佳。有些方法依赖于仅在仿真中可用的特权(privileged)状态信息,需要手工设计的技能,或者仅限于操作已知几何形状的固定物体实例。
随着视觉-语言模型(VLMs)性能的提升,以及它们展示出的广泛常识知识,我们是否能够利用它们的能力来完成多样化任务并实现可扩展的数据生成?答案是肯定的——通过精心的系统设计以及正确的输入和输出形式,我们不仅可以利用VLMs以零样本的方式成功执行多样化任务,还可以生成大量高质量的数据,用于训练行为克隆策略。
本文提出了MANIPULATE-ANYTHING,一种可扩展的自动化演示生成方法,用于真实世界中的机器人操作。MANIPULATE-ANYTHING能够生成高质量、大规模的数据,并且能够操作多种物体来执行多样化的任务。当被置于现实环境中并给定任务时(例如,图2中的“打开上层抽屉”),MANIPULATE-ANYTHING能够有效利用视觉-语言模型(VLMS)来指导机械臂完成任务。与之前的方法不同的是,它不需要特权(privileged)状态信息、手工设计的技能,也不局限于特定的物体实例。不依赖特权(privileged)信息使得MANIPULATE-ANYTHING能够适应各种环境。MANIPULATE-ANYTHING会规划一系列子目标,并生成相应的动作来执行这些子目标。它还可以使用验证器检查机器人是否成功完成了子目标,如有需要可以从当前状态重新规划。这种错误恢复机制使得系统能够识别错误、重新规划并从失败中恢复,并且将恢复行为注入到收集的演示数据中。本文还通过引入多视角推理,进一步增强了VLM的能力,显著提升了性能。
通过两个评估设置展示了MANIPULATE-ANYTHING的实用性。首先展示了它可以应对一个全新的、前所未见的任务,并以零样本的方式完成任务。本文在7个真实世界任务和14个RLBench仿真任务中进行了量化评估,并展示了在多个日常现实任务中的能力(详见补充材料)。在零样本评估中,本文的方法在14个仿真任务中的10个任务上显著优于VoxPoser。它还能推广到VoxPoser因物体实例限制而完全失败的任务中。此外,本文展示了该方法能够以零样本方式解决真实世界中的操作任务,任务平均成功率达到38.57%。其次展示了MANIPULATE-ANYTHING可以生成有用的训练数据,用于行为克隆策略的训练。将MANIPULATE-ANYTHING生成的数据与人工收集的真实演示数据以及VoxPoser、Scaling-up和 Code-As-Policies生成的数据进行比较。令人惊讶的是,基于本文数据训练的策略在12个任务中的5个任务上表现优于人工收集数据,并且在另外4个任务中表现相当(通过RVT-2评估)。与此同时,基准方法在某些任务上无法生成训练数据。MANIPULATE-ANYTHING展示了在非结构化的现实环境中大规模部署机器人的广泛可能性,同时也突显了其作为训练数据生成器的实用性,有助于实现扩大机器人演示数据规模这一关键目标。
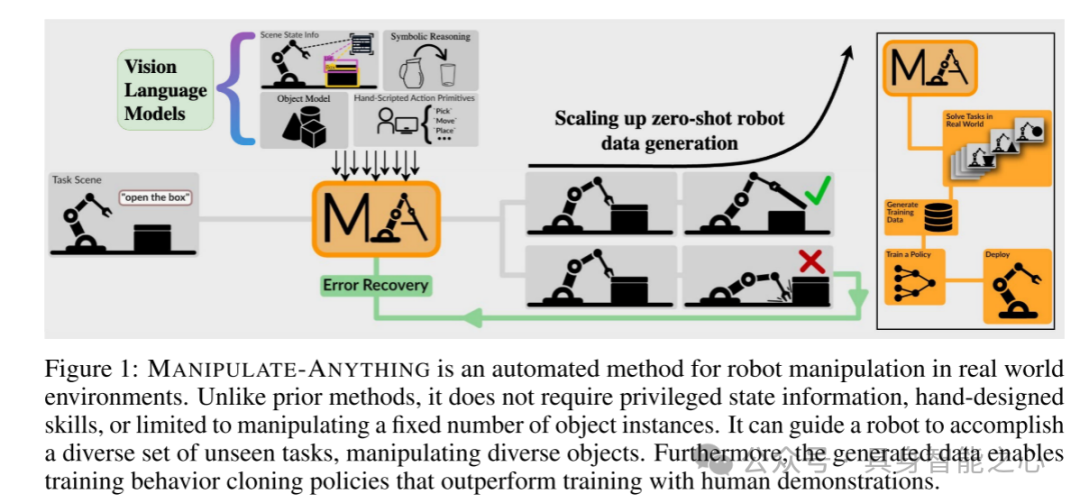
图1:MANIPULATE-ANYTHING 是一种用于真实世界环境中机器人操作的自动化方法。与之前的方法不同,它不需要特权(privileged)状态信息、手工设计的技能,也不局限于操作固定数量的物体实例。它能够引导机器人完成多样化的未见任务,操纵不同的物体。此外,生成的数据可以用于训练行为克隆策略,其效果优于使用人类演示数据进行的训练。
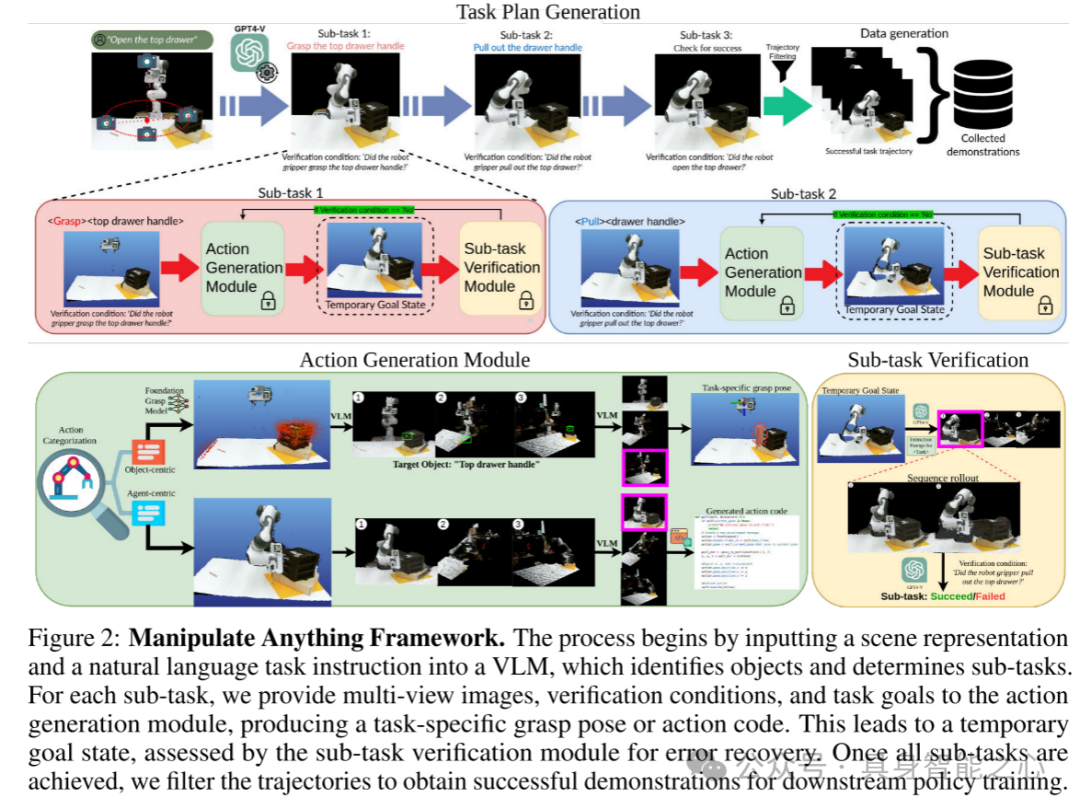
图2:MANIPULATE-ANYTHING 框架。该过程首先将场景表示和自然语言任务指令输入到视觉-语言模型(VLM),模型识别出物体并确定子任务。对于每个子任务,本文提供多视角图像、验证条件和任务目标给动作生成模块,生成与任务相关的抓取姿势或动作代码。随后达到一个临时目标状态,子任务验证模块对其进行评估以进行错误恢复。当所有子任务完成后,本文对轨迹进行筛选,获得成功的演示数据,用于后续策略训练。

图3:MANIPULATE-ANYTHING 是一个开放词汇的自主机器人演示生成系统。本文展示了14个仿真任务和7个真实世界任务的零样本演示。
实验结果分析:
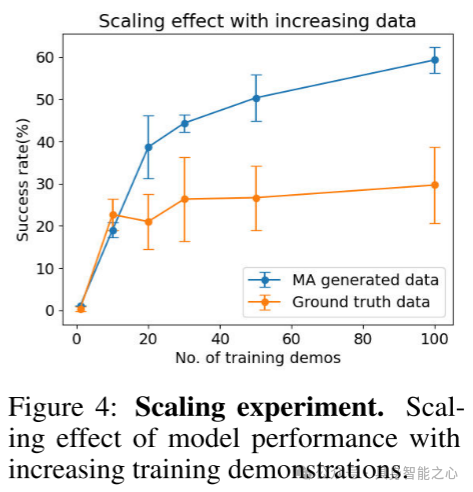
图4:扩展实验。随着训练演示数据量的增加,模型性能的扩展效果。
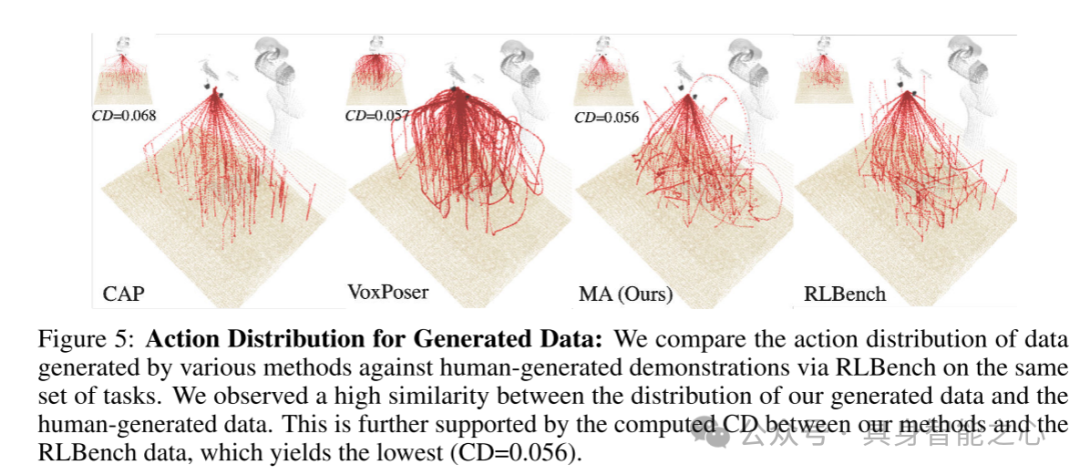
图5:生成数据的动作分布:本文比较了不同方法生成的数据与通过RLBench在人类生成的同一组任务演示中的动作分布。本文观察到本文生成的数据与人类生成的数据在分布上具有高度相似性。这一点也通过本文方法与RLBench数据之间计算出的CD得到支持,结果显示本文的方法的CD值最低(CD=0.056)。
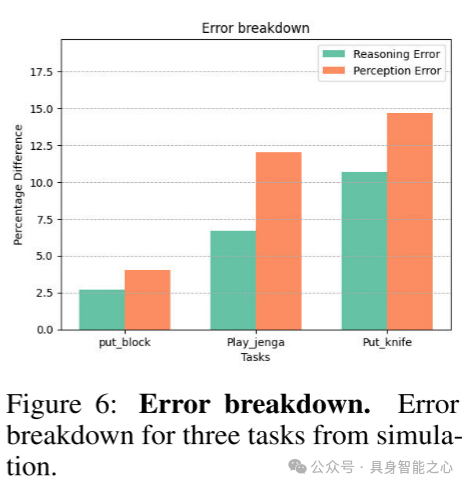
图6:错误分解。来自仿真中三个任务的错误分解。
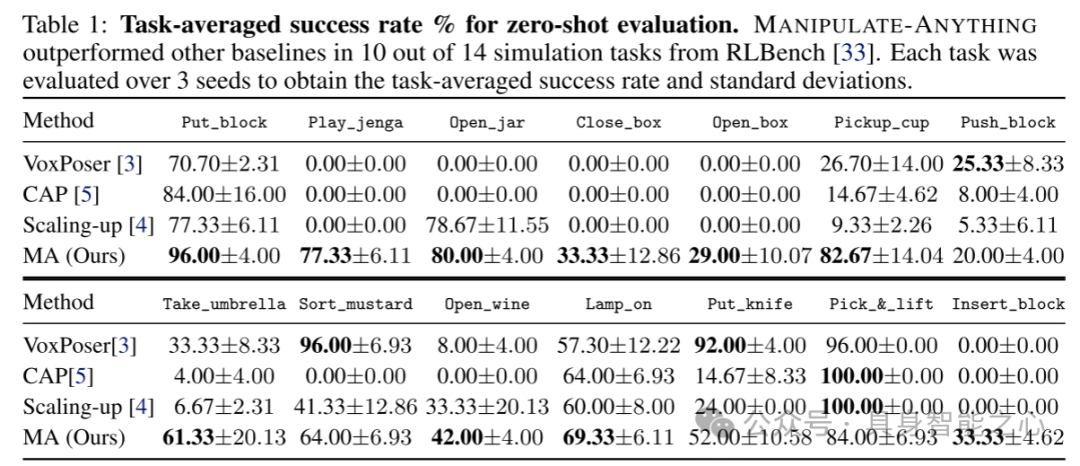
表1:零样本评估的任务平均成功率百分比。MANIPULATE-ANYTHING 在RLBench的14个仿真任务中有10个任务的表现优于其他基线方法。每个任务通过3个种子进行评估,得出任务平均成功率和标准差。
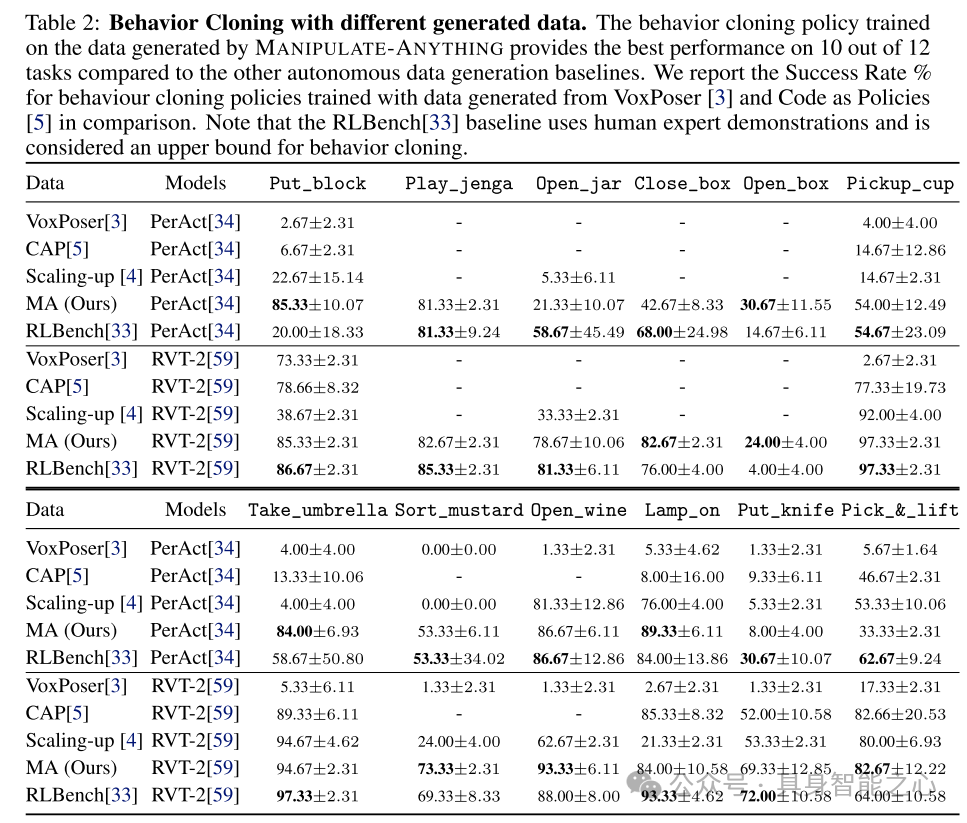
表2:使用不同生成数据的行为克隆。与其他自动数据生成基线相比,基于MANIPULATE-ANYTHING生成数据训练的行为克隆策略在12个任务中的10个任务上表现最佳。本文报告了使用VoxPoser 和 Code as Policies生成的数据训练的行为克隆策略的成功率百分比作为对比。需要注意的是,RLBench 基线使用的是人类专家演示数据,且被视为行为克隆的上限。
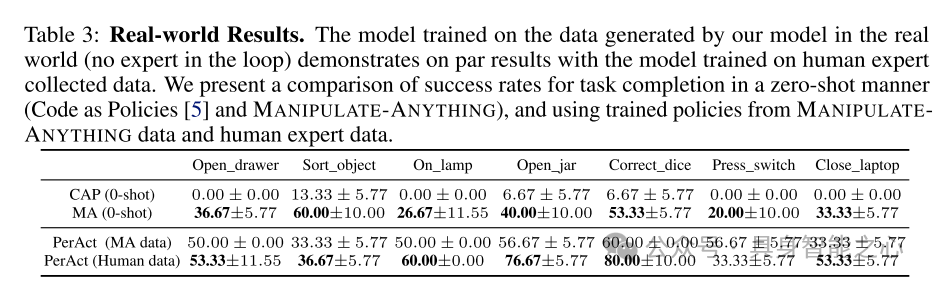
表3:真实世界结果。使用本文模型生成的真实世界数据(无专家介入)训练的模型,展示出与基于人类专家收集数据训练的模型相当的结果。本文展示了零样本任务完成成功率的比较(Code as Policies 和 MANIPULATE-ANYTHING),以及使用MANIPULATE-ANYTHING数据和人类专家数据训练的策略的成功率对比。
总结:
MANIPULATE-ANYTHING 是一种可扩展且环境无关的方法,用于生成无需特权(privileged)环境信息的零样本机器人任务演示。MANIPULATE-ANYTHING 利用视觉-语言模型(VLMs)进行高层次规划和场景理解,并具备错误恢复能力。这使其能够生成高质量的数据,用于行为克隆训练,且性能优于使用人类数据的训练结果。
引用:
@article{duan2024manipulate,
title={Manipulate-Anything: Automating Real-World Robots using Vision-Language Models},
author={Duan, Jiafei and Yuan, Wentao and Pumacay, Wilbert and Wang, Yi Ru and Ehsani, Kiana and Fox, Dieter and Krishna, Ranjay},
journal={arXiv preprint arXiv:2406.18915},
year={2024} }“具身智能之心”公众号持续推送具身智能领域热点:
【具身智能之心】技术交流群
具身智能之心是首个面向具身智能领域的开发者社区,聚焦大模型、机械臂、双足机器人、四足机器人、感知融合、强化学习、模仿学习、规控与端到端、仿真、产品开发、自动标注等多个方向,目前近60+技术交流群,欢迎加入!扫码添加小助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

【具身智能之心】知识星球
具身智能之心知识星球是国内首个具身智能开发者社区,主要关注具身智能相关的数据集、开源项目、具身仿真平台、大模型、视觉语言模型、强化学习、具身智能感知定位、机器臂抓取、姿态估计、策略学习、轮式+机械臂、双足机器人、四足机器人、大模型部署、端到端、规划控制等方向。扫码加入星球,享受以下专有服务:
1. 第一时间掌握具身智能相关的学术进展、工业落地应用;
2. 和行业大佬一起交流工作与求职相关的问题;
3. 优良的学习交流环境,能结识更多同行业的伙伴;
4. 具身智能相关工作岗位推荐,第一时间对接企业;
5. 行业机会挖掘,投资与项目对接;


















 2343
2343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









