




点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
今天自动驾驶之心为大家分享北航&小米名为MV2DFusion的多模态检测框架。全面利用模态特定的目标语义,实现了全面的多模态检测!如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
论文作者 | Zitian Wang等
编辑 | 自动驾驶之心
内容速览
提出了一个名为MV2DFusion的多模态检测框架,全面利用模态特定的目标语义,实现了全面的多模态检测。在nuScenes和Argoverse 2数据集上验证了框架的有效性和效率。
该框架能够灵活地与任何模态检测器配合使用,可以根据部署环境选择最合适的检测模型,以实现更好的性能。
由于融合策略的稀疏性,框架在远程场景中提供了一个可行的解决方案。
论文信息
题目:MV2DFusion: Leveraging Modality-Specific Object Semantics for Multi-Modal 3D Detection
作者:Zitian Wang, Zehao Huang, Yulu Gao, Naiyan Wang, Si Liu
机构:北京航空航天大学人工智能研究所和小米汽车
原文链接:https://arxiv.org/pdf/2408.05945v1
摘要
随着自动驾驶车辆的发展,对稳定精确的三维目标检测系统的需求日益增长。尽管相机和激光雷达(LiDAR)传感器各自具有其独特的优势——例如相机能提供丰富的纹理信息,而激光雷达则能提供精确的三维空间数据——但过分依赖单一的传感模态常常会遇到性能上的局限。本文提出了一个名为MV2DFusion的多模态检测框架,它通过一种先进的基于查询的融合机制,整合了两种传感器的优势。该框架引入了图像查询生成器来对齐图像特有的属性,并通过点云查询生成器,有效地结合了不同模态下目标的特定语义,避免了对单一模态的偏好。基于这些宝贵的目标语义,能够实现基于稀疏表示的融合过程,确保在多样化的场景中都能进行高效且准确的目标检测。作者所提出的框架在灵活性方面表现出色,能够与任何基于图像和点云的检测器集成,显示出其适应性以及未来发展潜力。在nuScenes和Argoverse2数据集上的广泛评估结果表明,MV2DFusion在多模态3D检测方面达到了最先进的性能,特别是在长距离检测场景中表现突出。
文章简介
自动驾驶车辆的发展极大地推动了对三维目标检测技术的需求。不同的传感器,如相机和激光雷达(LiDAR),基于其成像原理的不同,能够捕获现实世界中物体的不同特征。这些不同模态的固有特性使它们能够从不同的视角区分物体。例如,物体在图像中以富含纹理的像素区域呈现,而在点云中则以一组3D点的形式呈现。近年来,无论是基于相机的检测还是基于激光雷达的检测,都取得了显著的进展。然而,依赖单一传感模态的检测方法存在其固有的局限性。图像缺乏深度信息,无法指示物体的三维位置;而点云则缺少丰富的语义信息,且在捕捉远距离物体时因稀疏性而受限。
为了充分发挥两种传感模态的优势,研究者们提出了多模态融合方法,旨在结合两种模态的优势。当前的多模态融合方法主要分为两大类:特征级融合和提议级融合。特征级融合方法通过构建统一的特征空间,提取不同模态的特征以形成多模态特征体。例如,DeepFusion和AutoAlign利用点云特征查询图像特征,增强了点云特征的表示。BEVFusion将图像和点云特征转换到鸟瞰图(BEV)空间并进行融合。CMT不构建统一的特征空间,而是采用统一的注意力机制来聚合图像和点云特征。尽管特征级融合方法在目标识别和定位方面表现出直观的优势,但它们并未完全挖掘原始模态数据中嵌入的目标先验信息,有时甚至会在融合过程中损害强烈的模态特定语义信息。
与此相对,提议级融合方法利用特定于模态的提议,以最大限度地利用模态数据。例如,F-PointNet将检测到的图像边界框转换为截头锥体,以便从点云中提取物体。FSF和SparseFusion首先分别从图像和点云中生成提议,然后将它们统一为基于点云的实例表示,以进行多模态交互。然而,在这些方法中,表示往往会偏向于某一模态,如在FSF中相机提议主导了多模态融合过程,而在SparseFusion中,图像提议实质上被转换为与点云提议相同的表示。
为应对这些挑战,本文提出了一个名为MV2DFusion的多模态检测框架。该框架扩展了MV2D以纳入多模态检测,采用目标即查询的设计,便于自然地扩展到多模态环境。作者重新设计了图像查询生成器,使其更贴合图像模态的特性,引入了不确定性感知的图像查询,以保留图像中的目标语义,并继承了丰富的投影视图语义。通过引入点云查询生成器,作者还能够获取来自点云的目标语义,并将其与图像查询结合。然后,通过注意力机制进行融合过程,从而轻松地整合来自两种模态的信息。
本文提出的框架设计精心,充分利用了模态特定的目标语义,不受特定表示空间的限制。此外,它还允许集成任何类型的图像检测器和点云检测器,展示了框架的通用性和扩展性。得益于融合策略的稀疏性,作者的框架也适用于远程场景,避免了内存消耗和计算成本的二次增长。通过最小的修改,该框架还可以轻松地结合基于查询的方法,有效利用历史信息,如StreamPETR。作者在nuScenes和Argoverse 2等大规模三维检测基准上评估了作者提出的方法,实现了最先进的性能。
作者的贡献可以概括为:
提出了一个框架,全面利用模态特定的目标语义,实现了全面的多模态检测。在nuScenes和Argoverse 2数据集上验证了框架的有效性和效率。
该框架能够灵活地与任何模态检测器配合使用,可以根据部署环境选择最合适的检测模型,以实现更好的性能。
由于融合策略的稀疏性,框架在远程场景中提供了一个可行的解决方案。
总结来说,作者的方法在多模态三维检测方面取得了进步,提供了一个既稳健又多功能的解决方案,充分利用了相机和激光雷达两种传感模态的优势。
详解MV2DFusion
概述
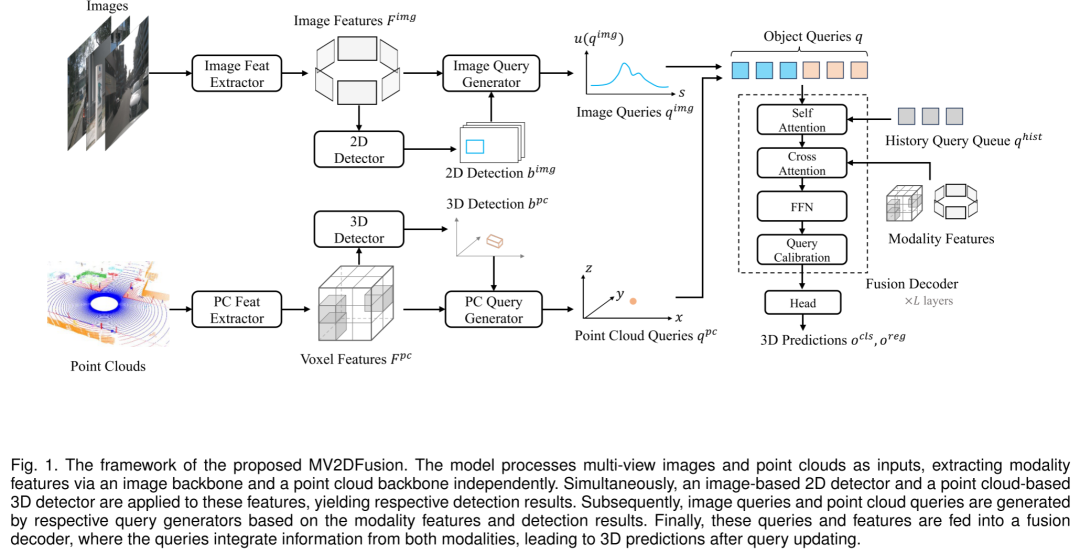
图 1 展示了 MV2DFusion 的整体流程。该模型接收 个多视角图像和点云数据作为输入,并通过独立的图像和点云网络主干提取各自的特征。利用这些特征,模型分别应用 2D 图像检测器和 3D 点云检测器,得到各自的检测结果。然后,基于这些特征和检测结果,生成图像查询和点云查询,这些查询随后输入到融合解码器中。在解码器中,查询会整合两种模态的信息,进而生成 3D 预测结果。以下各节将详细描述每个部分的详细信息和设计原则。
利用模态特定的目标语义
作者设计了一种融合策略,它能够在不偏向任何单一模态的情况下,挖掘并融合不同模态中的原始信息。具体来说,作者不是在 3D 空间中直接表示和融合整个场景,而是通过提取并融合各自模态的目标语义来进行多模态 3D 检测。这种策略不仅保留了每种模态的独特优势,而且通过稀疏性降低了计算成本和内
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1039
1039

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









