



去年的618,那个时候没有什么大礼给到大家。课程开发的不完善、运营不成熟、星球也不好意思拿出手,而到今年的618,一切都有转机了。这一年可以说非常充实忙碌,自动驾驶之心的小伙伴们忙着调研、开发新课程、对接各类投诉、处理各类盗版问题。从懵懵懂到现在轻车熟路,质疑的次数、被投诉和举报的次数,不断在推着我们前进。自动驾驶之心将会一直处于创业的状态,危机意识、不断创新与突破是整个团队定下的基调。坚持做最有价值的事情,不惧怕,不逃避。
这一整年我们对接了几百名学生和老师,以及数十家自动驾驶公司,对我们的评价最多的是:“你们拉近了工业界和学术界的距离”,让很多以前在学校学不到的东西披露给大家,这样真的好吗hhh,很多已经工作的朋友被这些年轻人卷的不行啦!面试的时候,我们很难想象这是一个应届毕业生,看起来有好像有1-2年的工作经验。
说到这里,也和大家谈一下我们课程和星球学员后面都去哪里高就了。首先国内领先的自动驾驶公司:像百度、Momenta、蔚来、小鹏等是我们同学经常光顾的地方;一些芯片和AI公司,比如地平线、商汤科技、旷视等也是大家经常去搬砖的地方;还有很多去博世、NVIDIA等外企高就的;以及清华、港科大、新加坡国立、UC 伯克利、卡耐基等名校继续深造的。不多不少,满满的成就感!
主要涉猎了哪些方向呢?
相比于去年,我们今年的技术方向已经形成了闭环:涉及感知、定位、融合、规划、仿真、预测、部署、cuda、端到端、论文辅导、开发语言等,涵盖了近30个自动驾驶子领域,无论你想选择哪个方向都能找到对应的答案。
五月底的时候就已经有很多同学咨询我们618活动,今天也正式公布下。作为6.18提前批专场,自动驾驶之心为大家准备了上半年课程和星球的最大力度优惠:8.08折与6.8折!还在犹豫课程价格的同学建议火速入手啦,最好的机会。除此之外,我们也推出了课程畅学卡,近30门课程,随时随地学习!
618课程大额优惠券,微信扫码领取

1)自动驾驶感知系列
| BEV感知全栈系列教程 | 毫米波雷达视觉融合 | 激光雷达视觉融合 |
|---|---|---|
| 3D&4D毫米波雷达 | 面向量产的车道线检测 | Occupancy占用网络 |
| Occupancy数据生成 | 单目3D感知 | 点云3D目标检测 |
| Transformer与大模型 | YOLO系列全家桶 |
2)多传感器标定融合
| 面向工程和量产级的相机标定实战 | 多传感器标定全栈系统学习教程 |
|---|---|
| 多传感器融合跟踪全栈教程 |
3)模型部署
4)自动驾驶规划控制与预测
| 规划控制理论&实战教程 | 轨迹预测理论与实战教程 |
|---|---|
| 轨迹预测论文带读教程 | 自动驾驶规划控制小班课程 |
5)自动驾驶仿真与开发
6)端到端与在线地图
7)大模型与自动驾驶
8)科研辅导与其它
聊聊我们是怎么学习和讨论交流的?
其实课程视频代码学习是一方面,我们更看重交流本身。每个课程都配有专属vip交流群,主讲老师每天群内会和大家交流,不定期线上直播答疑。主要解决几类关键问题:小白常踩的坑、工程上常遇到的问题、后续的研究方向等等;
这里也给大家展示下我们比较活跃的交流群,一览日常交流状态:
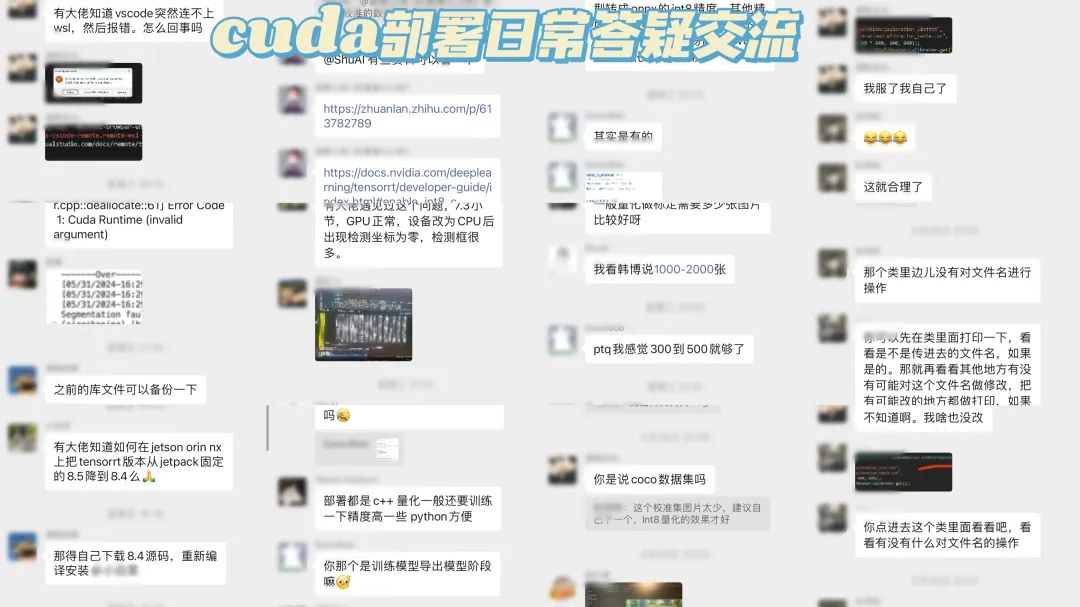
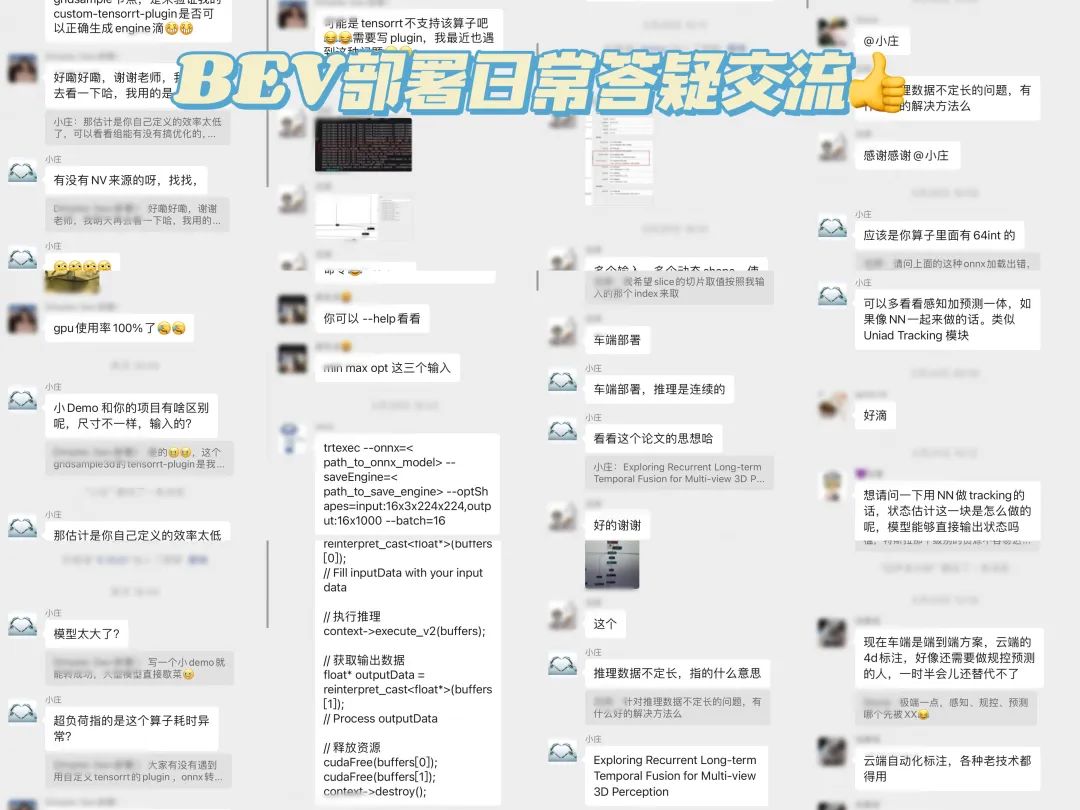
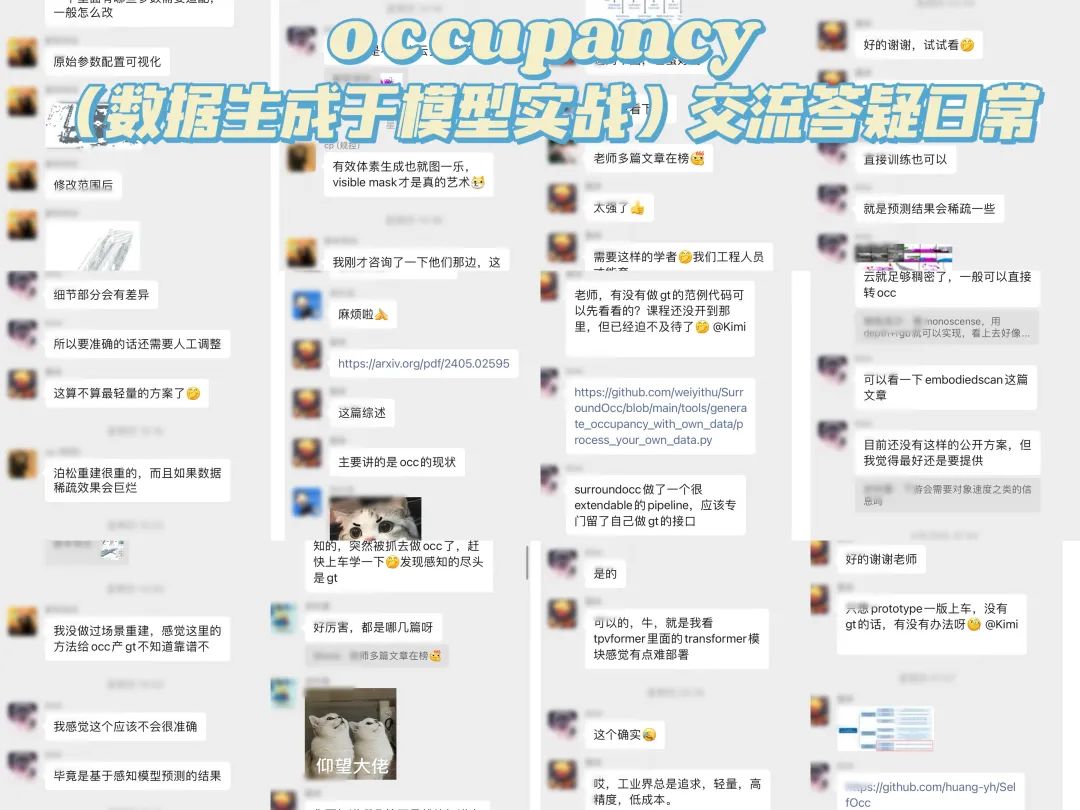
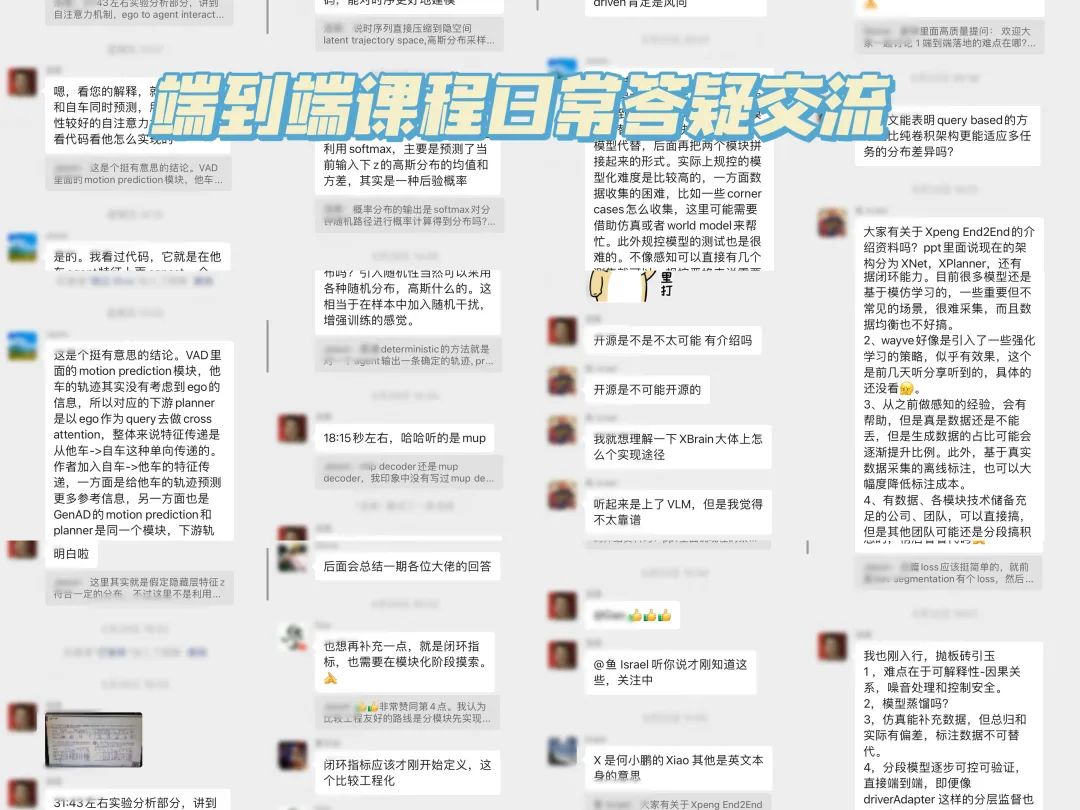
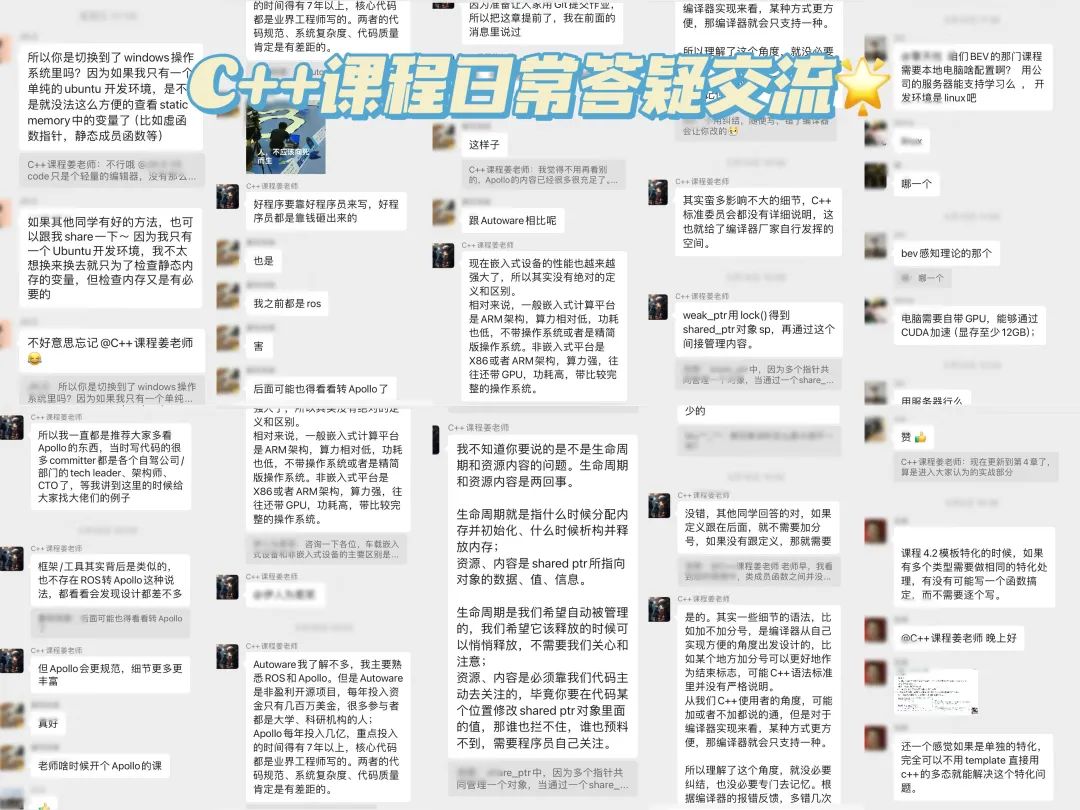
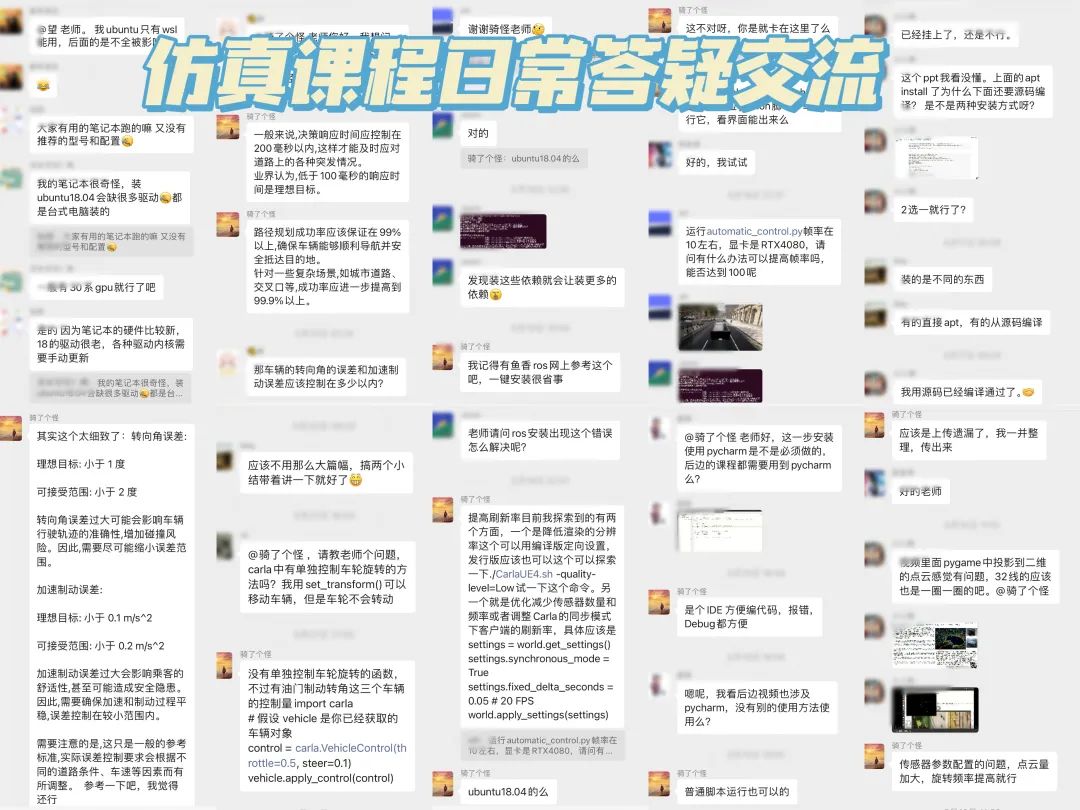
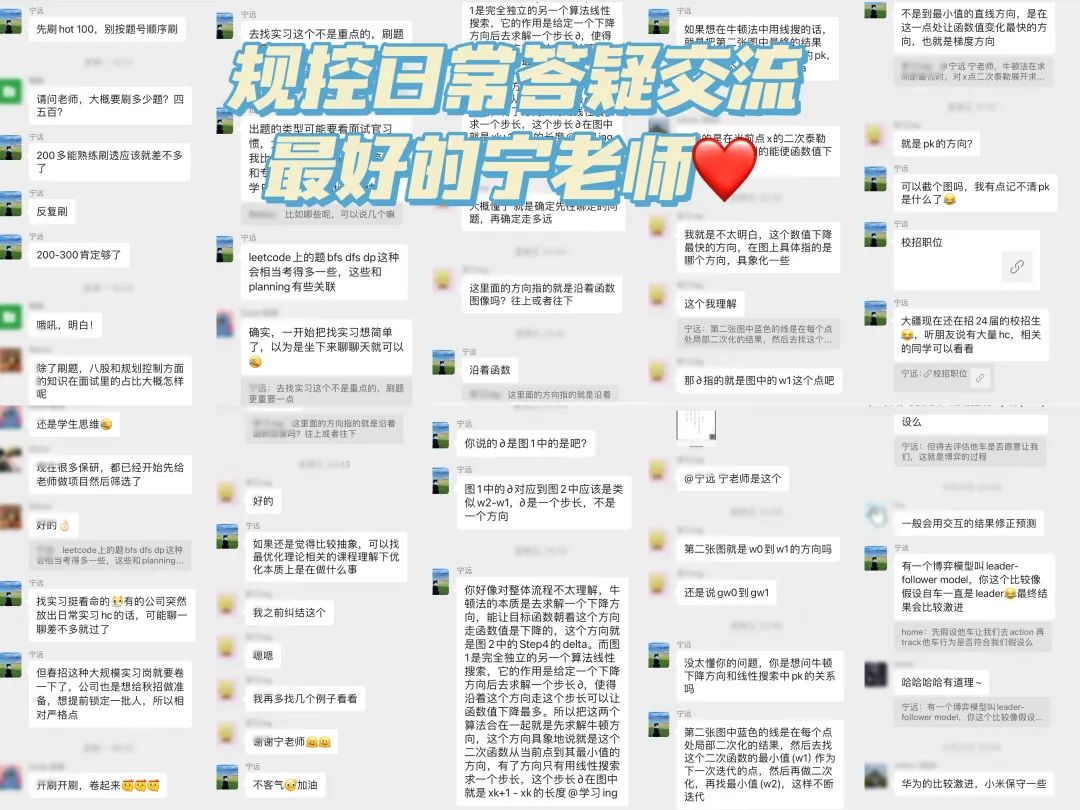
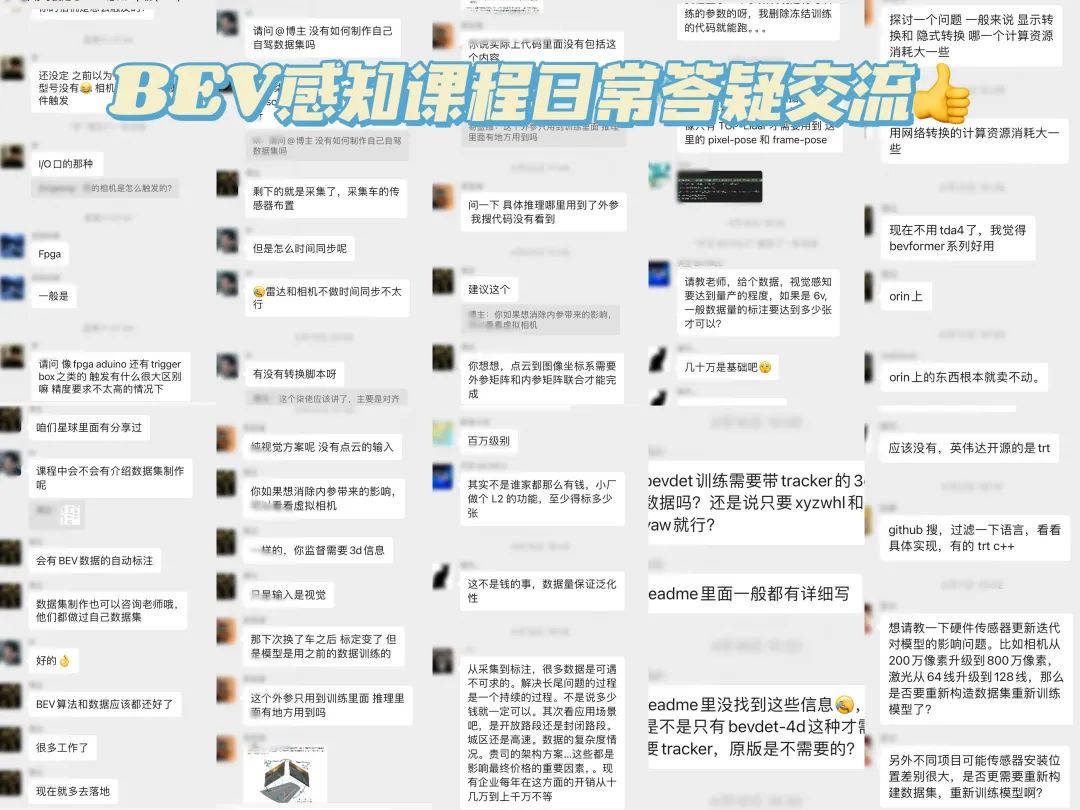
介绍下我们的畅学卡
2024开年后,我们收到了很多同学的诉求,你们自动驾驶之心的课程都还不错,能不能让我们随便学呀?当时我们突然惊呆了,近30门课程,怎么会有精力都学完?
后来经过深入了解,发现大多数同学都是刚入门的小白,不知道怎么选择方向。比如一个感知大方向下面就有近十几个小方向,如何选适合自己的方向呢?特别是在导师不熟悉、导师放养的情况下。能不能让小白先去涉猎下,看看这些子方向都是讲什么的?自己再判断真正喜欢哪个?
后面自动驾驶之心团队在内部沟通后,决定给大家开放所有课程,正式推出了畅学卡。我们考虑到大家不同的需求,设置了1年卡和2年卡。在对应年限范围内,可以任意选择所有已有课程学习(除小班课外),除此之外,也包括当年开发的所有新课。畅享任意学习,学得越多越省钱!未来可能更赚钱!直到确定自己的学习方向为止。适合刚开始找方向的小白、技术管理人员学习。
 微信扫码学习!一年期畅学卡
微信扫码学习!一年期畅学卡
 微信扫码学习!二年期畅学卡
微信扫码学习!二年期畅学卡
后面怎么找工作呢?
聊完课程学习,大家最关注的莫过于如何找到理想的工作。其实我们从一开始就不仅仅关注技术学习本身,在早期的时候就对接了很多自动驾驶公司,也结识了很多自动驾驶公司的算法主管、HR等。所以我们能第一时间接触到各家公司的需求,这也给我们的很多同学提供了岗位。
目前我们对接的公司和机构主要包括地平线、百度、上海人工智能实验室、蔚来汽车、小鹏汽车、哪吒汽车、华为车BU、大疆、文远、宏景智驾、AutoX等。课程学员在完成课程学习之后,可以联系我们进行岗位推荐,我们将第一时间递交给对应算法开发负责人,绕开官网投递。
也欢迎大家加入我们的【自动驾驶之心知识星球】和【自动驾驶之薪知识星球】,第一时间获取最新岗位和技术。


再强调下6.18大优惠!!!
618,我们推出了上半年最大的优惠!即将进入到下半年了,也是找工作和求职比较密集的时间点。欢迎加入自动驾驶大家庭一起进步,切勿独自踩坑!


















 1020
1020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









