



点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
原标题:Radocc: Learning Cross-Modality Occupancy Knowledge through Rendering Assisted Distillation
论文链接:https://arxiv.org/pdf/2312.11829.pdf
作者单位:FNii, CUHK-Shenzhen SSE, CUHK-Shenzhen 华为诺亚方舟实验室
会议:AAAI 2024

论文思路:
3D 占用预测是一项新兴任务,旨在使用多视图图像估计 3D 场景的占用状态和语义。然而,由于缺乏几何先验,基于图像的场景感知在实现准确预测方面遇到了重大挑战。本文通过探索该任务中的跨模态知识蒸馏来解决这个问题,即,本文在训练过程中利用更强大的多模态模型来指导视觉模型。在实践中,本文观察到直接应用,在鸟瞰(BEV)感知中提出并广泛使用的特征或 logits 对齐,并不能产生令人满意的结果。为了克服这个问题,本文引入了 RadOcc,一种用于 3D 占用预测的渲染辅助蒸馏范式。通过采用可微体渲染(differentiable volume rendering),本文在透视图中生成深度和语义图,并提出了教师和学生模型的渲染输出之间的两个新颖的一致性标准(consistency criteria)。具体来说,深度一致性损失对齐渲染光线的终止分布(termination distributions),而语义一致性损失则模仿视觉基础模型(VLM)引导的 intra-segment 相似性。nuScenes 数据集上的实验结果证明了本文提出的方法在改进各种 3D 占用预测方法方面的有效性,例如,本文提出的方法在 mIoU 指标中将本文的基线提高了 2.2%,在 Occ3D 基准中达到了 50%。
主要贡献:
本文提出了一种用于 3D 占用预测的渲染辅助蒸馏范式,名为 RadOcc。本文是第一篇探索 3D-OP 中跨模态知识蒸馏的论文,并为现有 BEV 蒸馏技术在该任务中的应用提供了宝贵的见解。
提出了两种新颖的蒸馏约束,即渲染深度和语义一致性(RDC 和 RSC),它们通过对齐由视觉基础模型引导的 ray distribution 和 affinity matrices,有效地增强了知识迁移过程。
配备所提出的方法,RadOcc 在 Occ3D 和 nuScenes 基准上实现了密集和稀疏占用预测的最先进性能。此外,本文验证了本文提出的蒸馏方法可以有效提高几个基线模型的性能。
网络设计:
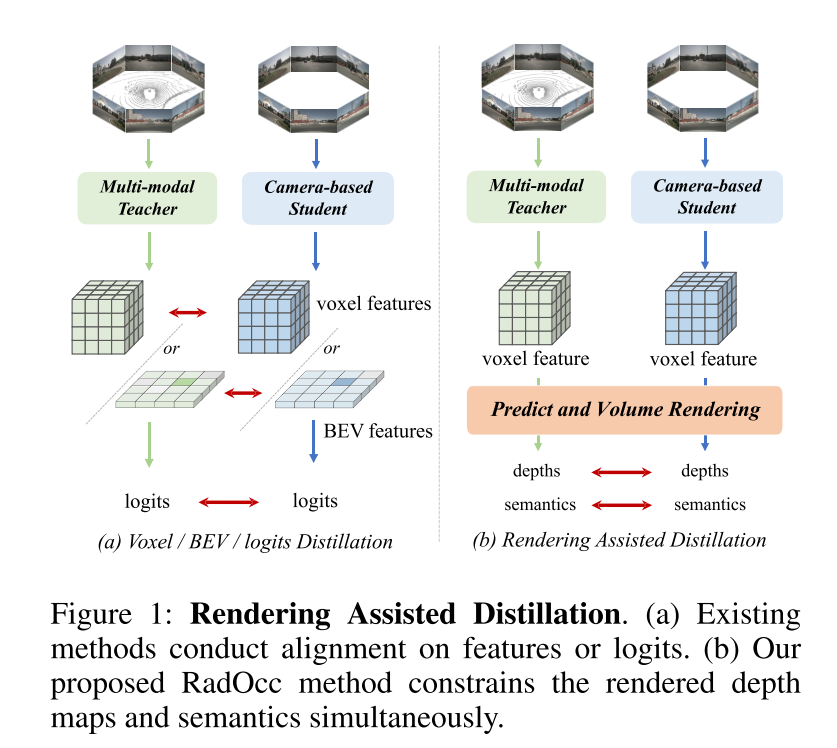
本文首次研究了针对 3D 占用预测任务的跨模态知识蒸馏。基于 BEV 感知领域现有的利用 BEV 或 logits 一致性进行知识迁移的方法,本文将这些蒸馏技术扩展到在 3D 占用预测任务中对齐体素特征和体素 logits,如图 1(a) 所示。然而,本文的初步实验表明,这些对齐技术在 3D-OP 任务中获得令人满意的结果面临着重大挑战,特别是前一种方法引入了负迁移(negative transfer)。这一挑战可能源于 3D 目标检测和占用预测之间的根本差异,后者是一项更细粒度的感知任务,需要捕获几何细节以及背景目标。
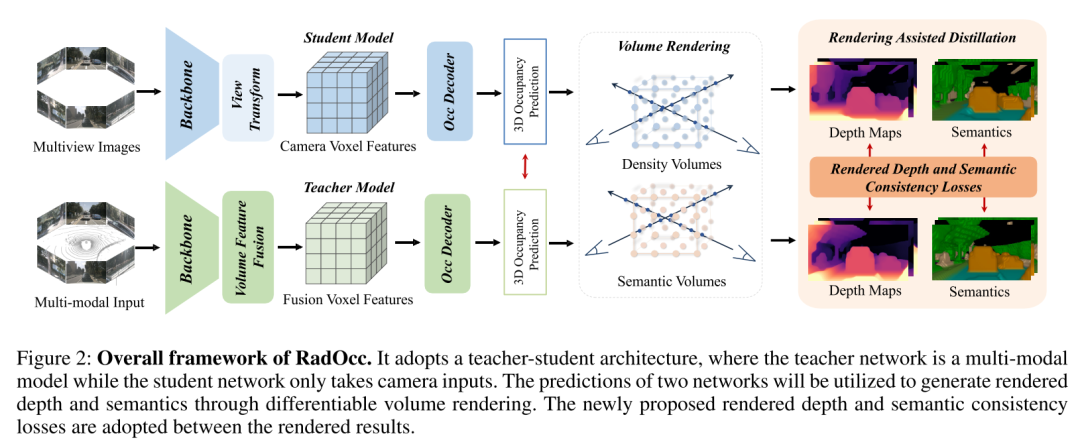
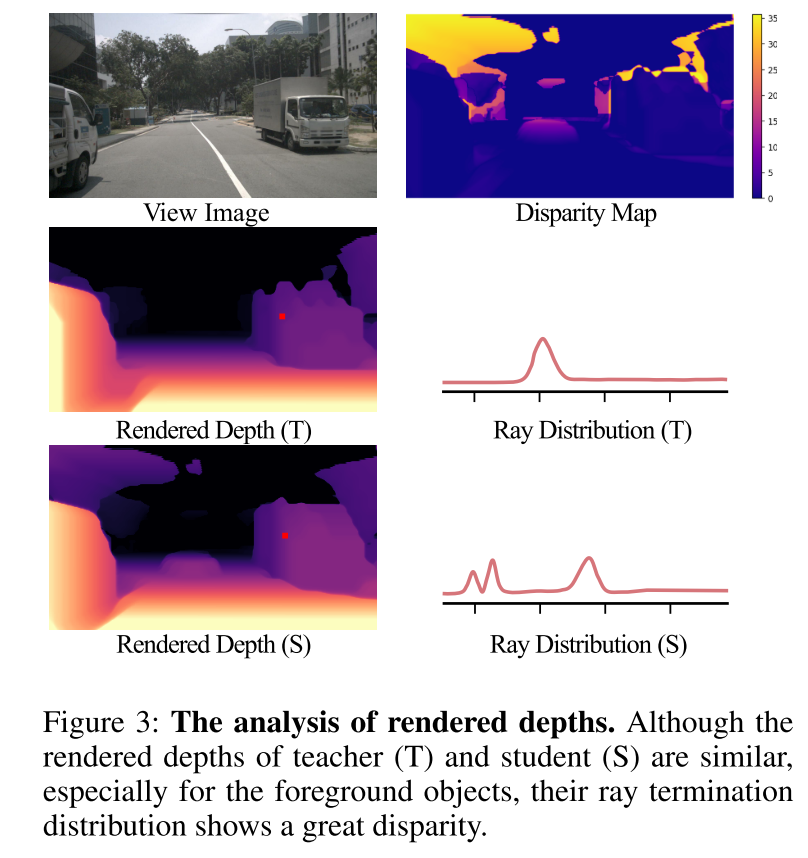
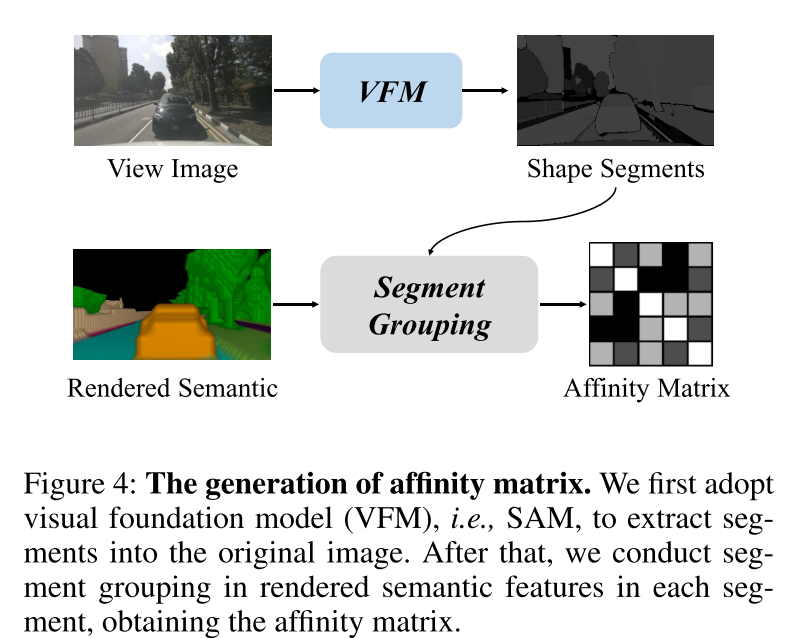
为了解决上述挑战,本文提出了 RadOcc,这是一种利用可微体渲染进行跨模态知识蒸馏的新颖方法。RadOcc的核心思想是对教师模型和学生模型生成的渲染结果进行对齐,如图1(b)所示。具体来说,本文使用相机的内参和外参对体素特征进行体渲染(Mildenhall et al. 2021),这使本文能够从不同的视点获得相应的深度图和语义图。为了实现渲染输出之间更好的对齐,本文引入了新颖的渲染深度一致性(RDC)和渲染语义一致性(RSC)损失。一方面,RDC 损失强制光线分布(ray distribution)的一致性,这使得学生模型能够捕获数据的底层结构。另一方面,RSC 损失利用了视觉基础模型的优势(Kirillov et al. 2023),并利用预先提取的 segment 进行 affinity 蒸馏。该标准允许模型学习和比较不同图像区域的语义表示,从而增强其捕获细粒度细节的能力。通过结合上述约束,本文提出的方法有效地利用了跨模态知识蒸馏,从而提高了性能并更好地优化了学生模型。本文展示了本文的方法在密集和稀疏占用预测方面的有效性,并在这两项任务上取得了最先进的结果。
实验结果:
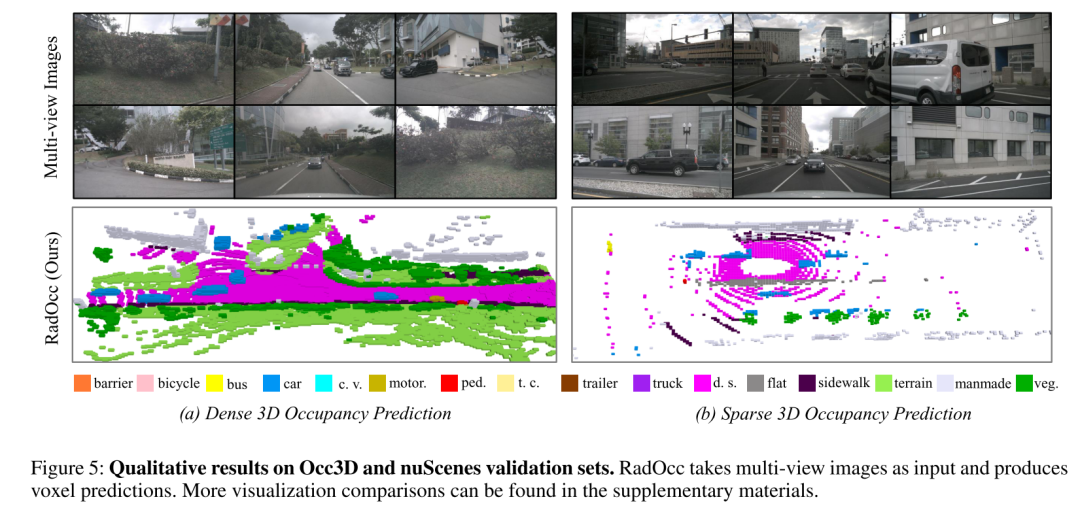
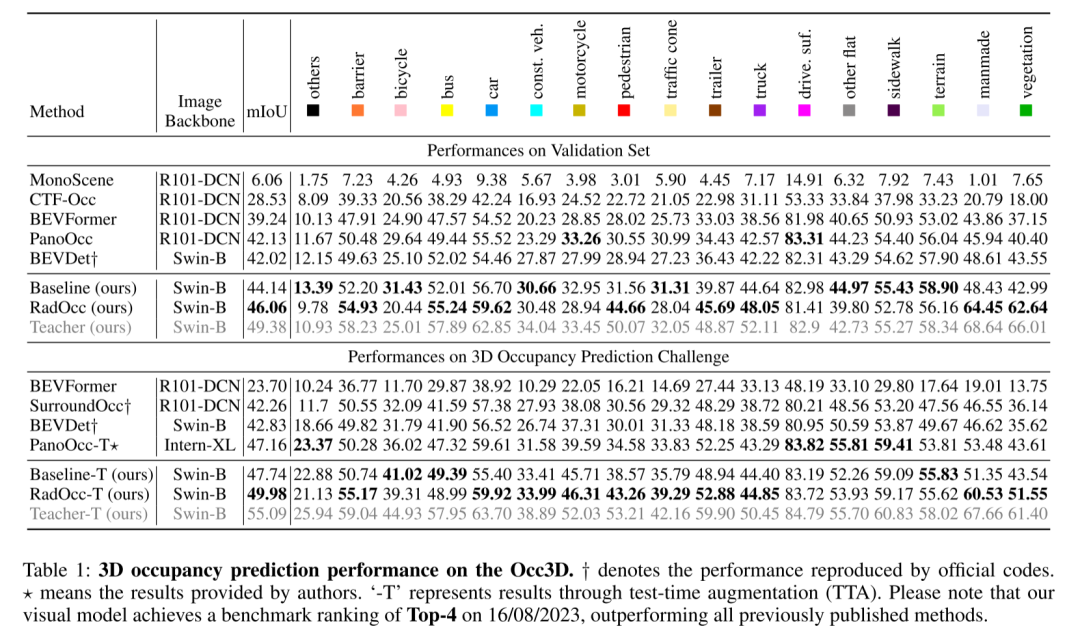
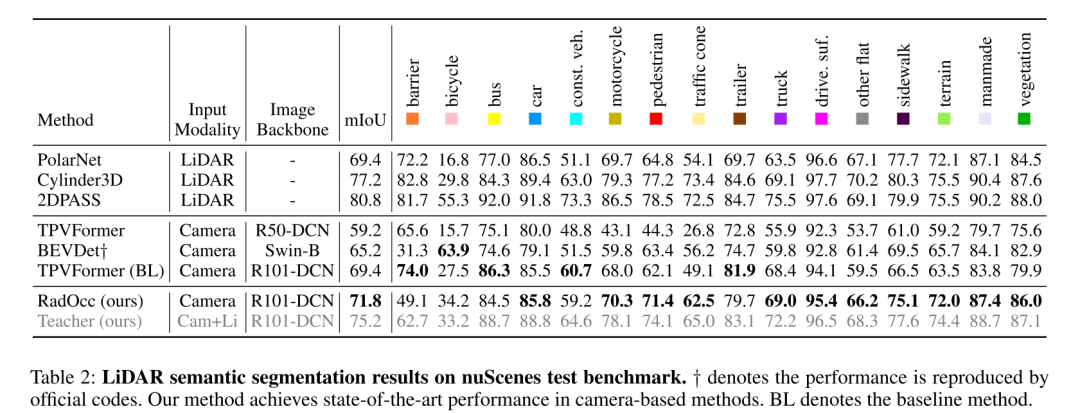
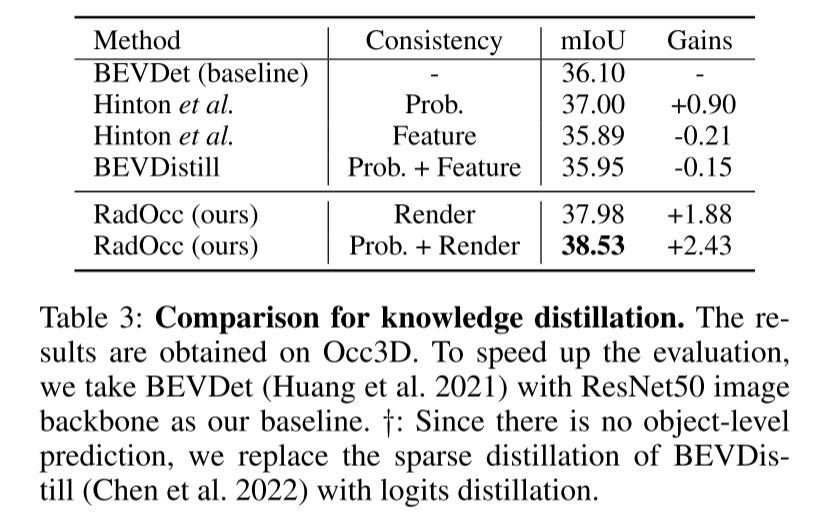
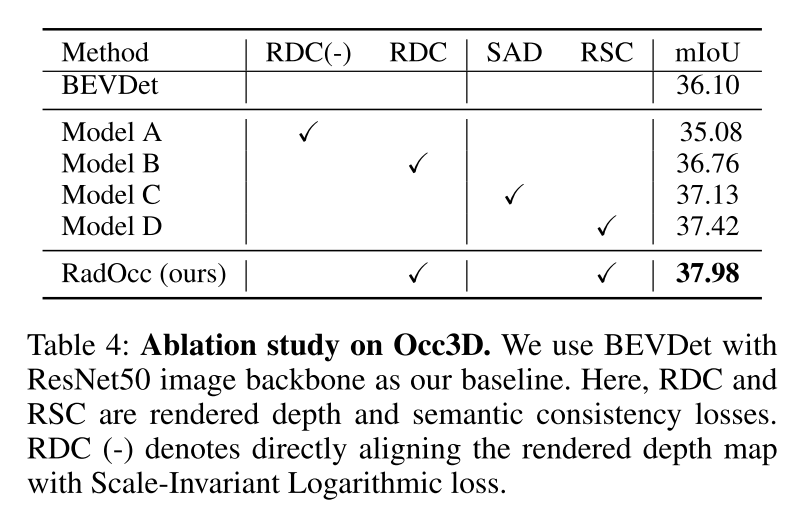
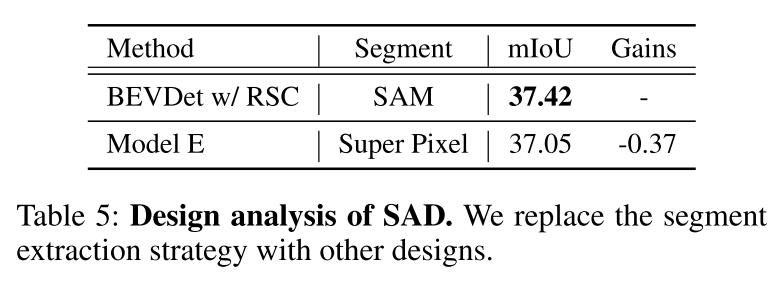
总结:
本文提出了 RadOcc,一种用于 3D 占用预测的新型跨模态知识蒸馏范式。它利用多模态教师模型通过可微分体渲染(differentiable volume rendering)为视觉学生模型提供几何和语义指导。此外,本文提出了两个新的一致性标准,深度一致性损失和语义一致性损失,以对齐教师和学生模型之间的 ray distribution 和 affinity matrix 。对 Occ3D 和 nuScenes 数据集的大量实验表明,RadOcc 可以显着提高各种 3D 占用预测方法的性能。本文的方法在 Occ3D 挑战基准上取得了最先进的结果,并且大大优于现有已发布的方法。本文相信本文的工作为场景理解中的跨模态学习开辟了新的可能性。
引用:
Zhang H, Yan X, Bai D, et al. RadOcc: Learning Cross-Modality Occupancy Knowledge through Rendering Assisted Distillation[J]. arXiv preprint arXiv:2312.11829, 2023.
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2400人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!


















 566
566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









