



作者 | 有车有据 编辑 | 智能车参考
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【全栈算法】技术交流群
本文只做学术分享,如有侵权,联系删文
没想到啊没想到,看似常规的自动驾驶技术分享,竟然意外曝出了行业内幕???
“今年开始,有一些自动驾驶驾驶供应商用传统CNN包装所谓「无图方案」忽悠车企。”
“很多AEB「五星」测试结果,实际是在用场景识别的方式作弊!”
“一些本来被认为做得还不错的玩家,向车企兜售劣质方案,拿用户性命开玩笑!”
这可能是今年最直白,最激烈自动驾驶前沿现场。

智驾科技的创始人、CEO周圣砚,毫不客气地揭了“老底”。
所以问题来了,智驾科技为什么这么刚?它说的都是真的吗?
以及,指出问题外,智驾科技有没有解决问题的方法?
揭了哪些底?
主要的问题有两个,都是针对今年自动驾驶大热的趋势或议题。
首先,是去高精地图依赖。意思是高阶智驾功能,尤其是拓展到城市道路的领航辅助,今年正走向轻高精地图化,甚至是去高精地图的技术路线。
原因也很简单,一是道路基建更新快,高精地图的采集更新不及时;二是高精地图本身的制作,需要投入巨大的成本;第三点,高精地图信息的采集、制作、使用等等环节,法规准入愈发严格。
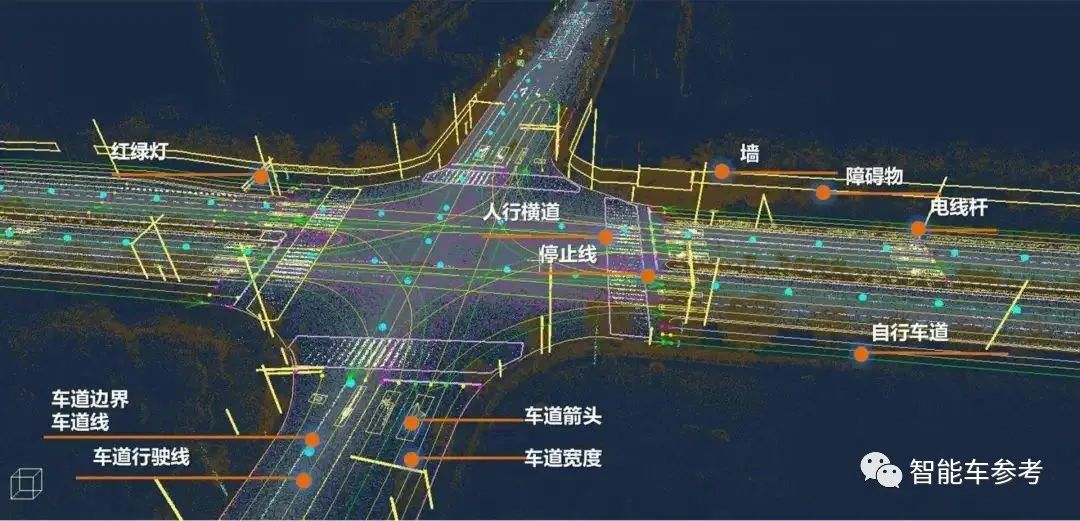
但智能驾驶的量产竞速不等人,所以轻图或无图就成了几乎所有量产玩家追求的方案,也成了主机厂卷成本的必然选项。
不过智驾科技CEO周圣砚却说,今年年初这个思路刚流行起来时,就发现行业某些玩家,拿传统的CNN,包装“无图方案”。
准确的说,是在主机厂客户看不到的底层算法上,使用成熟但能力不足的CNN,替代BEV,通过调参等手段做一个十分漂亮的Demo。
CNN就是卷积神经网络的简称,也是传统图像特征识别、提取的手段。但其局限性在于对目标的识别基于单帧数据,没有时序特征,也难以建立起不同目标之间的关系特征。
举个例子,“无图”情况下需要系统实时感知生成道路拓扑结构,CNN只能通过岔路口始终不变的“点”来识别。
但如果有目标经过这个“点”,造成短暂的遮挡,CNN就会瞬间失去对道路范围、车道线的正确识别,造成变道失败、紧急退出等等情况。
紧急情况下,隐藏着巨大的安全隐患。
第二点,是最近频频吵上热搜的AEB功能。智驾科技曝了一个更猛却令人哭笑不得的内幕:
实际上一些所谓C-NCAP五星级AEB功能,都在使用“场景识别”作弊。
啥是场景识别?就是通过特殊的场景触发特定机制。

因为无论是C-NCAP或是任何-NCAP的标准AEB测试中,假人目标永远是黑上衣蓝裤子,一旦系统识别到黑上衣蓝裤子人形目标,立刻提高AEB系统灵敏度,多快速度都能刹住。
但这样的系统是无法正常使用的,误触发太多。所以用户正常使用中,所谓“五星”AEB,根本没有任何作用。
简单到令人瞠目结舌。
智驾科技认为,现在行业出现了这种低成本“劣币驱逐良币”的隐患。
而真正有积累且负责任的自动驾驶公司,会用技术解决问题。
搞了什么新动作?
智驾科技首先科普了区别真无图和假无图方案的最直观方法,就是看系统有没有实时感知生成的道路拓扑结果:

支撑这项能力的,是以Transformer架构为基础的BEV算法。
BEV是将传统自动驾驶2D图像的感知方式,转换为在鸟瞰图视角下的3D感知。BEV空间经过处理,是可被算法理解和应用的。
在BEV框架下,所有后续的感知、预测、规划都可以在同一个空间进行,减少了上层对不同空间结果进行判断决策的麻烦。

再进一步,BEV将不同传感器输入在同一空间进行了统一,一些事情就更容易了。比如对物体的深度、体积、位置处理。
另外,BEV不仅有更丰富准确3D信息, 4D信息的提供也更容易——即时序融合。
由于BEV将各传感器数据都拉到了统一空间,并统一了形式,就更容易得到不同源的信息或特征,更容易知道不同目标在时间先后以及空间相对关系。
再再进一步,时间和空间做到了更好的统一,那么很多传统感知的短板也能弥补了。
首先是对于运动物体的估计会更准确,预测算法也会更稳定、高效;另外因为BEV算法是基于学习而来,那么对于遮挡场景以及物体状态可以做出推理,脑补出完整形态等等。

周圣砚认为,BEV给了自动驾驶一把新的钥匙,实现了自动驾驶端到端的重新定义。
智驾科技从2020年开始,做的最重要的一件事,就是用BEV+Transformer重构了自己的全部技术体系,成果是青云Hyperspace架构。
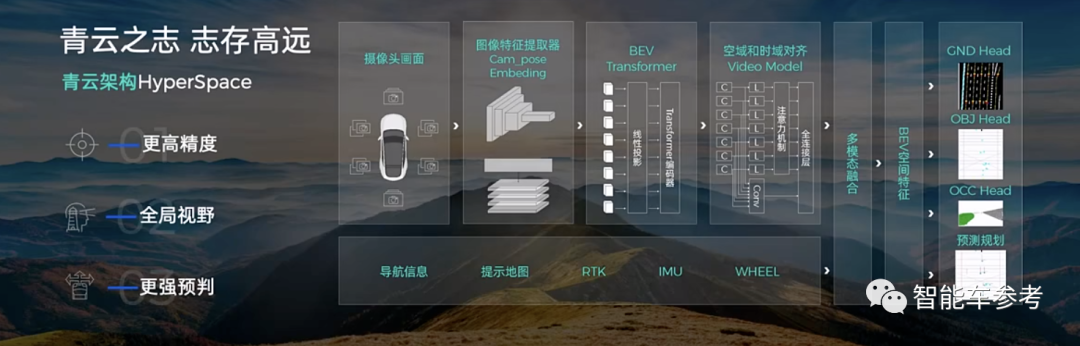
融合道路拓扑、目标轨迹、占用空间三大网络。
传统的L2系统,或基于高精度地图的智驾,道路拓扑的关系不需要车端感知完成,但在无图情况下,道路拓扑的关系检测就交给了BEV。
青云BEV架构的感知系统,精度上可以达到横向5公分,纵向1/1000的精度。千分之一就相当于在100米发现了一个道路的分叉点,而这个关于分叉点的误差不会超过10公分。
其次,青云BEV架构能输出车道线、地面箭头、斑马线、停止线等等目标,多达100多种交通要素属性,这些要素足够做无图 NOA 的需求。
第三,青云BEV具备超视距的能力,在6V(摄像头) 的基础上,向后可以最远看到100米,向前可以看到150米,且精度不打折扣。
最后,由于添加了时序信息,青云BEV目标遮挡,能够自行“脑补”,还原整个道路拓扑的完整性。

目标轨迹网络,是青云 BEV 架构的第二个模块。在传统的CNN网络下下,目标检测仅仅停留在历史和当下的单个目标的轨迹,对未来的轨迹,只能用基于规则的卡尔曼滤波的方式进行线性预测,往往是不准的。
青云 BEV 则利用生成式的方式解决了目标轨迹的预测问题。可以准确的预测目标 3 秒后的轨迹。相当于AI司机也具备了防御性驾驶能力。
青云 BEV 架构的第三个亮点,也是行业目前最期待的一个技术点=创新,就是纯视觉占用空间。

直观的说,就是将车辆周围的世界用 10 公分的立方体组成了网格,像搭乐高积木一样把它搭出来。除了能部分替代激光雷达的的作用,降低成本。
更重要的是系统不区分车辆、行人等不同目标,直接网格化表达,当系统发现前面有一个障碍物,不用经过感知识别等一系列决策链条,系统直接进行进行自动刹车。
通过智驾科技的青云架构也能看出,BEV+Transformer带来的不仅仅是技术创新,而是颠覆了传统CNN算法模块化累加造成的不确定性,可以理解为一种绝对意义上的底层技术创新重构。

智驾科技也基于此提出了一种很新的城市NOA实现方法——记忆共享:青云BEV架构利用拓扑元素,加之组合导航算法,可支持一次性完成自动化建图记忆,这是记忆共享技术实现的基础。
然后,通过MAXIPILOT®全系智能驾驶产品的投放市场,实现不同级别价位车型覆盖,这意味着入门级配置即可支持城区建图,能够帮助车厂客户以80%的规模化量产方案为基础,构建20%高配方案所需要的核心场景数据。
这套MAXIPILOT®全系智能驾驶产品的逻辑,就是基于这样的思路诞生。
MAXIPILOT®2.0 Lite主打城市增强L2方案,依托青云BEV技术解决当下L2体验不连续的产品痛点,例如L2系统在路口场景容易退出/道路拓扑变化体验不佳等。

包含BEV一体机和MDU20域控两种产品形态,覆盖20万元以下车型细分市场实现智慧化升级,支持极高性价比的轻地图高速NOM(Navigate on MAXIPILOT®)应用落地。
同时,MAXIPILOT®2.0 Lite也是行业内唯一支持BEV部署的前视一体机高性价比算力平台方案,定位覆盖日常行车70%以上场景的千元级别产品。基于单个BEV一体机数据闭环,快速获取关键路口/特殊道路拓扑等场景数据,高效开城。
MAXIPILOT®2.0 Pro,基于5R6V的传感器配置,单SOC实现行泊高度合一,是中算力平台性价比之选,支持实现全场景高速NOM、记忆行泊车等智慧化功能方案。
MAXIPILOT®2.0 Pro支持占用空间网络部署,支持输出BEV特征抽取后的特征地图(DREM-Deep learning REM),以数据合规方式上传云端,同样通过记忆地图共享实现高效开城。

MAXIPILOT®2.0 MAX主推nR9V的传感器配置方案,支持轻地图拓展城区NOM领航辅助驾驶方案,能够更好应对城区复杂环境及交互。同时方案可选前向激光雷达,作为城区视觉冗余的多重保障。
MAXIPILOT®2.0 MAX的亮点在于可以通过复用2.0 Lite和2.0 Pro积累的海量价值数据,实现成本可控、节奏可控的开城。
总结一下,智驾科技现在在做一件足够超前且又很决绝的事——果断扔掉CNN的包袱,用BEV+Transformer重构之前所有产品。
而BEV+Transformer带来的,不仅仅是智驾功能体验上的大幅改善,还指向了一条统一技术框架、数据高度复用的量产之路。几乎完美解决了入门智驾系统装机量大但数据价值不高,而高阶系统装机量小数据不足的问题。
智驾科技为啥这么刚?
智驾科技之前在自动驾驶圈曝光率、话题性并没有其他明星公司那样高,是一个十足低调但实力不容小觑的“扫地僧”。
创始人、CEO周圣砚,毕业于北京理工大学、MIT,2016年就创办了智驾科技。

智驾科技从一开始就坚定的走渐进式自动驾驶路线,并且和其他所有创业公司不同,打了一个提前量,几乎独自吃下了一片蓝海——
商用车主动安全系统。
2020年起,我国强制中大型商用车标配主动刹车、车道偏离预警等等功能,智驾科技迅速抓住这一机遇,客运货运双管齐下,提供AEB、LCC等基础L2功能,几年内覆盖了市面80%以上商用车品牌,出货量遥遥领先。

借助商用车ADAS历史机遇起飞后,智驾科技还是以熟悉的L2切入乘用车市场,并且在这两年中,实现了数十款量产车型的产品搭载,同时自动驾驶里程累积,也超过了3亿公里。
“智驾模式”,是一条独特的“商用包围乘用,L2包围L3”的“升维”路线,以技术补成本,快速规模量产的模式。开创了自动驾驶创业的一个新“门派”
而在如今BEV成为主流后,智驾科技以几乎相同的底层逻辑,给出了量产高阶智驾的新思路:低阶带动高阶,以规模化“拼图”的方式,实现NOA快速开城。
同样也提供了量产智驾的一种新参考。
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!


















 5657
5657

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









