



作者 | 黄浴 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/661365935
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【3D目标检测】技术交流群
本文只做学术分享,如有侵权,联系删文
10月10号的论文“Uni3D: Exploring Unified 3D Representation At Scale“,来自北京智源、清华和北大。

在过去的几年里,对图像或文本的放大表征进行了广泛的研究,并带来了视觉和语言学习的革命。然而,3D目标和场景的可伸缩表征相对来说还未被探索。这项工作提出Uni3D,一个三维基础模型,探索规模上的统一三维表征。Uni3D用2D初始化的ViT(vision Transformer)端到端预训练,将3D点云特征与图像-文本对齐特征进行对齐。通过简单的架构和pretext任务,Uni3D可以利用丰富的2D预训练模型作为初始化,并将图像-文本对齐模型作为目标,释放2D模型的巨大潜力,并将策略扩展到3D世界。有效地将Uni3D扩展到10亿个参数,并在广泛的3D任务上创下新纪录,如零样本分类、少样本分类、开放世界理解和部分分割。强大的Uni3D表示也支持3D绘画和野外检索等应用。
过去几年中,扩大的预训练语言模型(Brown2020;Liu2019;Raffel2020)在很大程度上彻底改变了自然语言处理。最近的一些工作(Rad-ford2021;Dosovitskiy2020;Bao2021;He2022;Fang2022)通过模型和数据规模化将语言的进步转化到2D视觉。从2D提升到3D,即学习一个可以在3D世界中迁移的可扩展3D表示模型,也是很吸引人的。最近,随着大规模3D数据集Objaverse的发布(Deitke 2023b),一些工作试图探索3D中的可扩展预训练,但是,要么仍然局限于小规模的3D主干(Xue 2021;b),要么很难扩展到相对较大的模型(Li2022),例如图中的72M。
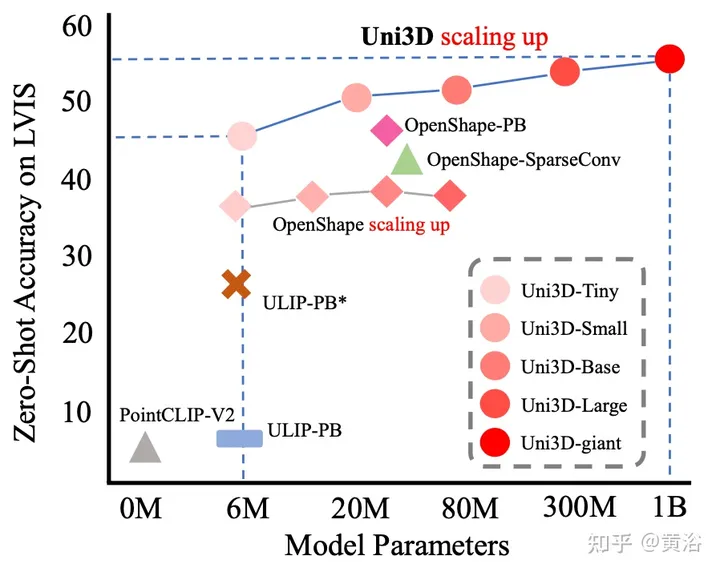
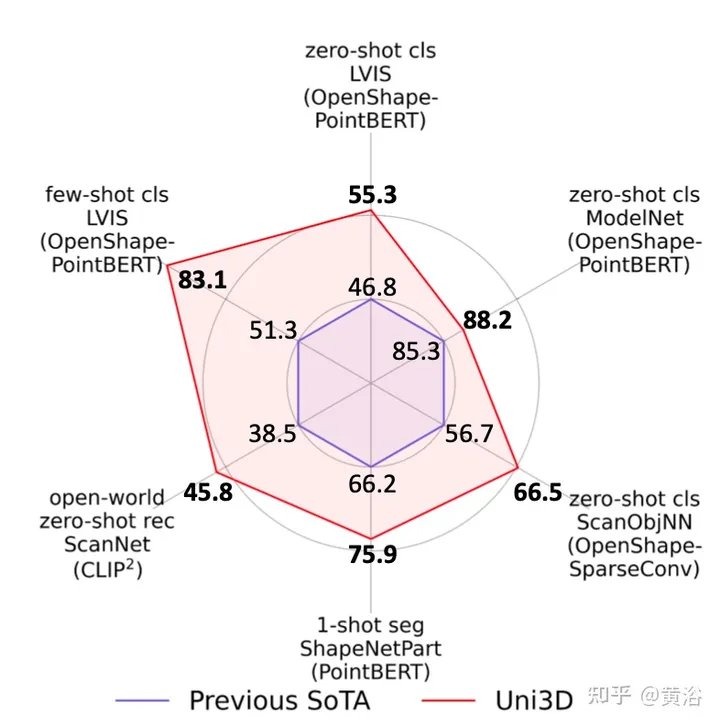
本文首次展示了一个十亿规模的3D表示模型,该模型可以很好地迁移到不同的下游任务和场景。如图所示,与现有技术相比,Uni3D在各种零样本和少样本3D任务中产生了性能提升。具体而言,Uni3D在ModelNet上实现了88.2%的零样本分类准确率,这令人惊讶地与一些监督学习方法不相上下。Uni3D在其他具有代表性的3D任务上也取得了最先进的性能,如开放世界理解、部分分割等。
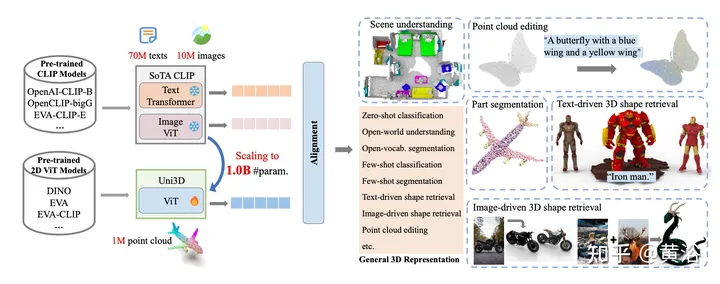
如图所示:Uni3D是一个用于大规模3D表示学习的统一且可扩展的3D预训练框架。把100万个3D形状与1000万个图像和7000万个文本进行配对,Uni3D扩展到10亿个参数。Uni3D用2D ViT作为3D编码器,通过丰富的2D预训练模型最佳2D先验进行初始化,然后再进行端到端预训练,将3D点云特征与来自CLIP模型的图像-文本对齐的特征再进行对齐。
实验中冻结了CLIP文本和图像编码器,同时专注于利用跨模态对比损失训练3D编码器。采用Adam(Kingma&Ba2014)优化器,其峰值学习率为1e-3,并随余弦学习率时间表逐渐降低。为了增强训练稳定性,我采用随机深度(Huang 2016)正则化。还利用了FLIP(Li 2023)技术,在训练期间随机屏蔽50%的点tokens,将时间复杂性降低了一半。预缓存所有形状的文本和图像CLIP嵌入,这样能够将总批量大小增加到1152,并大大加快训练。为了进一步改进训练过程,采用了带ZeRO一阶段优化器的DeepSpeed(Rasley2020)和带有动态损失伸缩的fp16精度(Rajbhandari2020)。利用上述策略,最大的模型,即具有10亿个参数的Uni3D-g,在24个NVIDIA 100-SXM4-40GB GPU运行大约20小时内收敛。
先前的方法(Rao2022;Yang2022)已经证明,从图像-文本对比学习中获得的知识,即CLIP,迁移的话,可以在2D密集预测任务(例如分割和检测)中产生显著的性能改进。然而,将这些知识迁移到3D密集预测任务中的研究很少。将Uni3D学习的全局点云-文本对齐,转换为局部点-文本对齐。目的是证明Uni3D中的目标级预训练足以学习详细的局部3D视觉概念。具体而言,选择Uni3D中ViT的第4层、第8层和最后一层的特征,表示为H4、H8和H12。根据PointNet++(Qi 2017b),用特征传播将群组特征H4、H8和H12上采样为逐点特征。在训练过程中,冻结Uni3D主干,只优化特征传播层中的参数,并监督对齐逐点特征和CLIP文本编码器提取的真值部分标签的文本特征。通过冻结学习的Uni3D参数,专注于有效地探索预训练的细粒度知识。
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!


















 2601
2601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









