



 本文介绍了自动驾驶中的多模态三维目标检测技术,强调其在环境感知、准确性提升和复杂场景应对中的优势。同时,文章针对初学者提出了一个详细的教学课程,由华中科技大学的博士专家授课,涵盖了从入门到深入的多模态融合3D检测技术。
本文介绍了自动驾驶中的多模态三维目标检测技术,强调其在环境感知、准确性提升和复杂场景应对中的优势。同时,文章针对初学者提出了一个详细的教学课程,由华中科技大学的博士专家授课,涵盖了从入门到深入的多模态融合3D检测技术。
目前自动驾驶的感知解决方案中,存在两大主要路线:一个是纯视觉的路线,即基于BEV感知和单目3D的方法,其主要优点是成本低,代表性的业界公司为Telsa;另一个便是多模态融合感知路线,其主要优点是性能好且系统鲁棒性高,代表性科技公司为Google Waymo。目前而言,这两个方案没有绝对的好坏之分。多模态3D检测由于引入了其它传感器的数据,在性能上相比于纯视觉方案有明显优势,是各大自动驾驶公司研究的热点,都在抢滩落地!偷偷告诉大家,多模态融合岗位也是今年为数不多持续在招人的细分领域~~~
多模态三维目标检测在自动驾驶中扮演着重要的角色,优势非常突出,和视觉方案取长补短:
1. 环境感知能力提升:自动驾驶系统需要准确地感知和理解道路环境,包括检测和跟踪其他车辆、行人、自行车、交通标志等。多模态三维目标检测结合了多个感知模态(如图像、点云、声音等),能够提供更全面、准确的环境感知信息,帮助自动驾驶系统更好地理解周围环境。
2. 目标检测准确性增强:传统的基于摄像头的二维目标检测容易受到光照、遮挡等因素的影响,可能导致误检或漏检。而多模态三维目标检测结合了多个感知模态的信息,可以提供更多的几何和语义特征,从而提高目标检测的准确性和鲁棒性。这对于自动驾驶系统的安全性和可靠性至关重要。
3. 复杂场景和挑战的应对:自动驾驶面临着各种复杂的驾驶场景和挑战,如夜间驾驶、恶劣天气条件、遮挡物等。多模态三维目标检测技术通过结合多个感知模态的信息,能够克服这些挑战,提供更可靠的目标检测结果。例如,在夜间驾驶中,通过结合红外图像和点云数据,可以有效地检测到障碍物和行人,提高驾驶系统的安全性。
4. 智能决策和规划的支持:多模态三维目标检测为自动驾驶系统提供了更准确的目标信息,有助于系统进行智能决策和规划。通过准确地检测和跟踪周围的车辆、行人和障碍物,自动驾驶系统可以更好地预测它们的行为,并做出相应的决策,如避让、变道、停车等,以确保行驶的安全性和效率。
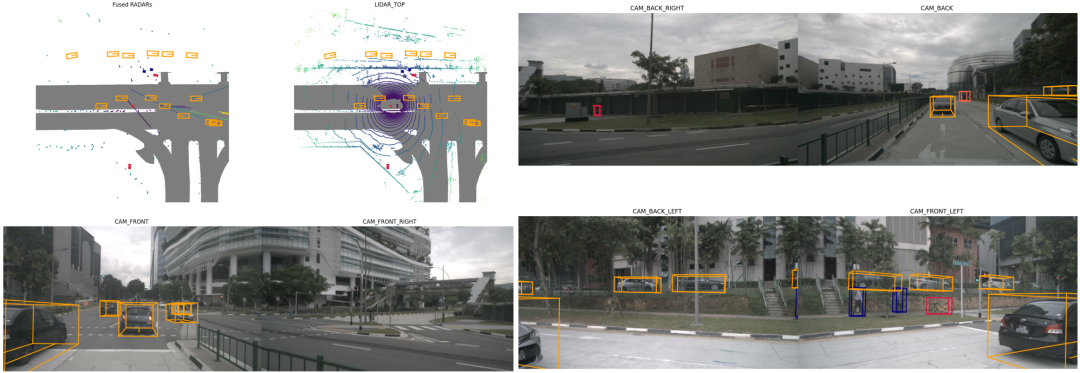
如何入门学习?
多模态3D融合入门非常困难,在数据和算法层面的理解上难倒了一大帮人!许多同学在刚学习多模态感知算法的时候往往不知道如何下手,大多数人不清楚如何建立不同模态之间的关系,如何选择合适的融合方法以及如何实现高效的融合?
在深入调研大家的需求后,我们选择了行业几乎所有主流多模态三维目标检测算法,其主要包括基于深度学习的前融合,深度特征融合以及后期结果融合三个层面。从0到1为大家详细展开网络结构设计、算法优化、实战等方方面面,内容非常详细,这是国内首门完整的多模态融合3D检测教程,一骑绝尘!最适合刚入门的小白以及需要在业务上从事多模态感知算法的同学,大纲如下:

主讲老师
阡陌,华中科技大学大学在读博士,国内首批研究多模态3D检测的技术专家,深耕自动驾驶算法领域多年。以主要作者(一作/同一/通讯)在TAPMI,ECCV,AAAI,ICRA等计算机视觉或机器人顶级会议发表多篇论文,担任ICCV,TCSVT,AAAI,IJCAI,ICRA, RAL等多个期刊或会议审稿人,Google Sholar引用量600+。在自动驾驶三维目标检测、三维目标跟踪、多模态融合等方面有着丰富的经验。
本课程适合人群
计算机视觉与自动驾驶感知相关研究方向的本科/硕士/博士;
自动驾驶2D/3D感知相关算法工程人员;
想要转入自动驾驶与多模态融合感知算法的小伙伴;
工作上需要提升的算法工程人员及企业技术管理人员;
本课程需要具备的基础
具有一定的python和pyTorch基础,熟悉深度学习常用的一些基础算法;
对2D/3D感知以及多模态融合的应用和基础方案有一定了解;
一定的线性代数和矩阵论基础;
电脑需要自带GPU,能够通过CUDA加速(显存至少12GB);
学后收获
对多模态融合三维目标检测的主流方案有着深入理解;
学习到多模态融合感知的设计思想,从根本上学会如何设计一个有效的多模态融合的三维目标检测框架;
能够精通自动驾驶通用算法,理论实践并重,无论是学术界抑或工业界都能直接复用;
学完本课程能够达到1~2年左右自动驾驶融合感知工程师水平;
能够结识许多行业从业人员与学习合作伙伴!
开课时间
2023.8.20号正式开课,早鸟价加入我们一起学习基础,开课后2个月结课,离线教学,微信群内答疑(交流环境非常好,非常重要的部分)!
课程咨询

扫码学习课程!

扫码添加助理咨询课程!
(微信:AIDriver004)
版权声明
自动驾驶之心所有课程最终版权均归自动驾驶之心团队及旗下公司所属,我们强烈谴责非法盗录行为,对违法行为将第一时间寄出律师函。也欢迎同学们监督举报,对热心监督举报的同学,我们将予以重报!

















 1674
1674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









