 CNN优化技术概览:模型、算术与实现层面策略
CNN优化技术概览:模型、算术与实现层面策略




作者 | 守夜人 编辑 | 自动驾驶与AI
原文链接:https://zhuanlan.zhihu.com/p/642606748
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
本文只做学术分享,如有侵权,联系删文
点击进入→自动驾驶之心技术交流群
“Lee et al., “Resource-Efficient Convolutional Networks: A Survey on Model-, Arithmetic-, and Implementation-Level Techniques,” ACM Comput. Surv., p. 3587095, Mar. 2023, doi: 10.1145/3587095.
”
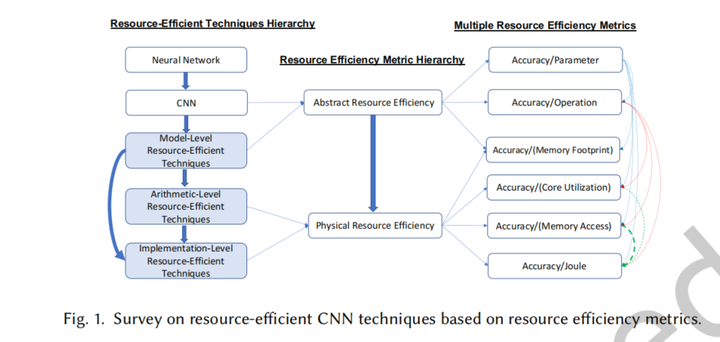
CNN部署的三层优化:
模型级:对模型架构的改进
算术级:使用低精度算法减少内存占用和数据传输
实现级:功能相同的情况下采用更有效的实现算法
模型级优化
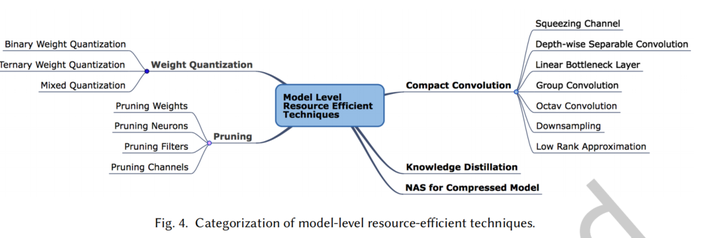
权重量化
二值量化
使用一位bit来表示权重中的一个元素。二值量化消除了MAC计算中的乘法,若激活也被量化,则CNN中所有MAC操作可以通过XNOR和计数器实现。
三元量化
相比二值量化提高了精度,所有权值可以量化为三个值,只需要两个bit来表示量化权重。
混合量化
将激活和权重量化为任意低精度格式。例如将权值量化到1位,激活到2位提高了精度。
剪枝
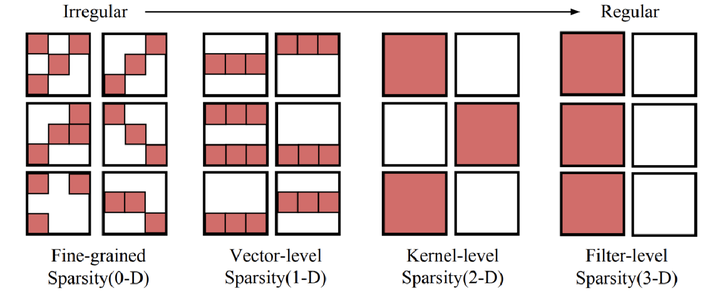
剪枝有多种粒度,越规则化就越粗粒度,可能导致较低的精度和剪枝率,但易加速。
紧凑卷积
压缩通道
SqueezeNet每个网络块利用小于输入通道数量的1×1 filter来减少挤压阶段的网络宽度,然后在扩展阶段利用多个1×1和3×3 kernel。通过挤压宽度,计算复杂度明显降低,同时补偿了扩展阶段的精度。SqueezeNext在扩展阶段利用了可分离的卷积;一个k×k的filter被分为一个k×1和一个1×k的filter。与SqueezeNet相比,这种可分离的卷积进一步减少了参数的数量。
深度可分离卷积
深度可分离卷积由Depthwise Convolution和Pointwise Convolution两部分构成。Depthwise Convolution的计算非常简单,它对输入feature map的每个通道分别使用一个卷积核,然后将所有卷积核的输出再进行拼接得到它的最终输出,Pointwise Convolution实际为1×1卷积。最大优点是计算效率非常高。典型实例如 Xception、MobileNet。
线性瓶颈层
瓶颈结构是指将高维空间映射到低维空间,缩减通道数。线性瓶颈结构,就是末层卷积使用线性激活的瓶颈结构(将 ReLU 函数替换为线性函数)。该方法在MobileNet V2中提出,为了减缓在MobileNet V1中出现的Relu激活函数导致的信息丢失现象。
组卷积
在组卷积方法中,输入通道分为几组,每组的通道分别与其他组进行卷积。例如,带有三组的输入通道需要三个独立的卷积。由于组卷积不与其他组中的通道进行交互,所以不同的组之间的交互将在单独的卷积之后进行。与使用常规卷积的cnn相比,组卷积方法减少了MAC操作的数量
Octave 卷积
通过在卷积中分离高频和低频信息,压缩模型参数个数,节省特征图的内存占用。
降采样
例如更大的卷积步长
低秩近似
利用奇异值分解压缩卷积层的参数
知识蒸馏
主要思想是:学生模型模仿教师模型,并获得近似甚至更优越的性能表现。关键问题是如何将大教师模型转移到小的学生模型上。知识蒸馏系统基本由三个关键部分组成:知识、蒸馏算法、教师-学生结构
神经架构搜索
在精度、资源约束、推理性能的要求下,自动搜索出一个可用的小型网络。
算术级优化
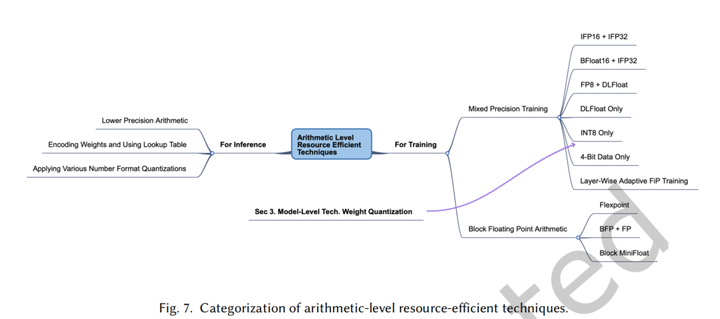
数值类型
半精度、单精度和双精度
BFloat16(Brain Float-Point using 16 Bits)
谷歌提出的浮点数值类型,支持比FP16更广泛的动态数据类型。目前已用于NVIDIA A100、Google TPU
DLFloat
TF32(TensorFloat32)
Nvidia提出,在其显卡上有专门硬件支持
推理
低精度算术
权重编码
利用大多数权重的指数值位于一个狭窄的范围内这一事实,使用Hufman编码方案对权重的频繁指数值进行编码。位于内存和FP算术单元之间的查找表被用来将编码后的指数值转换为FP指数值。
训练
根据前向传播、激活梯度更新、权值更新等不同的训练过程来调整算术精度,可以加速CNN的训练。
混合精度训练
1)IFP16+IFP32;2)BFloat16+IFP32;3)FP8+DLFloat;4)DLFloat Only;5)INT8 Only;6)逐层自适应量化
实现级优化
数据重用
使用靠近PE的SRAM本地内存、
利用空间体系结构
采用脉动阵列等设计
电路优化
快速卷积算法
转换为矩阵乘法,利用高度优化的矩阵计算库来加速
im2col
FFT
Winograd
利用权重和激活的稀疏性
运行时跳过操作
当使用Relu后许多值变为0,可以在运行时动态跳过
编码稀疏权值、激活值、特征图
稀疏矩阵编码
自适应计算资源分配
早期退出
用于分布式计算系统
运行时通道宽度自适应
在运行时修剪了不重要的filter
运行时模型切换
DNN的推理延迟由于新分配的工作负载而增加时,运行时决策者在运行期间降级当前DNN以满足延迟约束。当内存资源充足时,这种模型切换方法在运行时是合适的,因为多个dnn应该预装在DRAM中。
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)


















 498
498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









