



编辑 | 3D视觉工坊
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【全栈算法】技术交流群
观点一
作者|robot9野生程序猿
https://www.zhihu.com/question/23418797/answer/39561946
答案是可以!
这方面一直是计算机视觉的研究热点,并且已经有了不错的成果!本人研究生阶段主要做三维重建,简单写一些自己所了解的。
首先三维和二维的区别,这个大家都容易理解,二维只有x、y两个轴,比如一张素描画,我们整体的感觉是“平”的,而三维则是多了一个z轴的维度,这个z轴的直观理解就是点离我们的距离,也即 “depth(深度)”。
再来看看我们人眼,人眼是一个典型的双目系统,大家可以做个小实验:闭上一只眼睛,然后左右手分别拿着一只笔,试着让笔尖相碰,哈哈,是不是有怀疑人生的感觉?我们分别用左右眼看同一个物体,可以清楚地感觉到图像的差异,这个差异就是我们形成三维视觉的基础,有了这左右眼图像的差异,配合大脑强大的识别匹配能力,我们就能基本确定物体离我们的距离,也即之前说的"深度",上个实验中我们只睁开一只眼睛,虽然能清楚的看到左右手中的笔,但是大脑没法得出深度信息,所以你在“上下左右”方向上能准确定位,但是“前后”方向上却无能为力。
现在来说说左右图像的“差异”到“深度”的转换,这里可能需要一点点空间几何知识,其实也很简单,上图
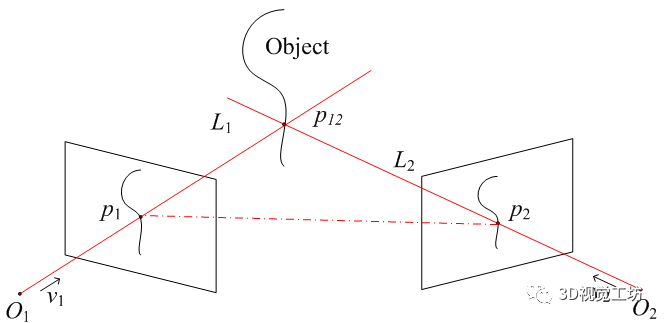
物体上的点p12分别对应左右图像上点p1和p2,求解p1、p2、p12构成的三角形,我们就能得到点p12的坐标,也就能得到p12的深度。这个计算对于人脑来说是小case,我们更多地依赖经验和强大的脑补能力,虽然我们不能计算出某个物体离我们的精确距离,我们却能非常准确地建立物体距离的相对关系,即哪个物体在前,哪个在后,这对日常生活已经足够了。
而我们做工程上的双目视觉三维重建,核心目标就是解上图所示的三角形,相机可以抽象成一个简单的透视系统:
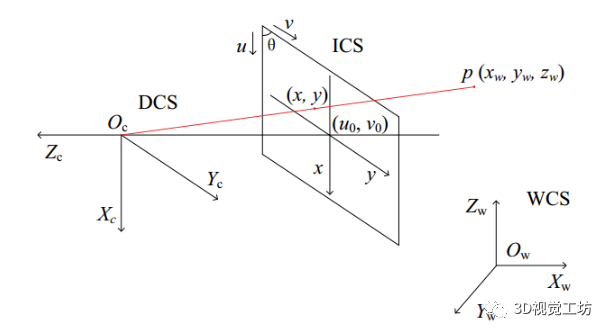
空间点p经过相机成像,映射到图像上点(x,y),其中Oc是相机光心,WCS、DCS、ICS分别是世界坐标系、设备(相机)坐标系、图像坐标系。空间点p到相机图像上点的几何变换可以用相机内参来描述,具体公式就不说了,可以简单地理解为相机拍照是对点的几何坐标变换,而相机内参就是决定这个变换的一些参数。
继续看之前的光学三角关系图,O1、O2分别是左右相机的光心,现在我们要做的就是确定这两个相机的相对位置关系:可以用旋转矩阵R和平移向量T来描述,确定了R和T,两个相机的位置关系就确定了,这个步骤叫做相机的外参标定。一般的做法是用三维重建的逆过程来做,即由一系列已知的p1、p2和p12来求解光学三角形,估计出最优的R、T。简而言之,外参标定确定相机之间的相对位置关系。
好了,现在我们只需要知道p1、p2的坐标,我们就能轻松算出p12的坐标,完成三维重建。我们把p1、p2称为一个点对(pair),他们是同一个空间点在不同相机中的成像点。寻找这样的点对的过程称为立体匹配,它是三维重建最关键,也可以说是最难的一步。我们都玩过“大家来找茬”,找的是两幅图的不同点,而立体匹配则是找“相同点”。对人脑来说,这个问题太easy了,给你同一个物体的两幅图,你能轻松找出一副图像上的点在另一幅图像中的对应点,因为我们人脑的物体识别、分割、特征提取等等能力实在太强了,而且性能特别高,估计几岁的小孩就能秒杀现有的最好的算法。
常规的匹配算法一般通过特征点来做,即分别提取左右图像的特征点(常用sift算法),然后基于特征点配合对极几何等约束条件进行匹配。不过这类匹配算法精度都不是太高,所以人们又想了其它一些方法来辅助匹配,结构光方法是目前用的比较多的,原理不难理解,就是向目标物体投射编码的光,然后对相机图像进行解码,从而得到点对,举个简单的例子,我们把一个小方块的图案用投影仪投到物体表面,然后识别左右相机图像中的小方块,如果这个小方块很小,看作一个点,那么我们就得到了一个点对。
贴个线结构光的示意图:
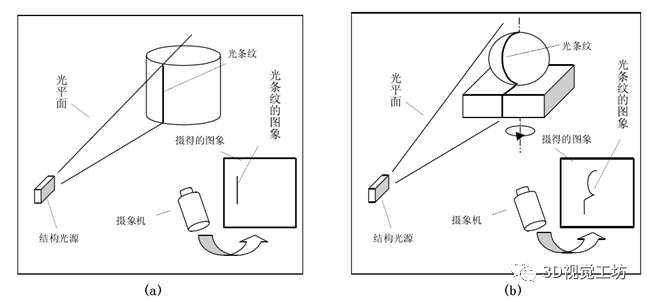
这个示意图里面只有一个相机,其实投影仪是可以看作相机的:投出的光图案照射在物体表面相当于被拍照的物体,而投影仪的输入图像则相当于相机拍出来的照片,所以投影仪也是当作相机并用同样的方法来标定内外参,即上图本质上也是双目视觉系统。
总结一下,双目视觉三维重建的基本过程:相机内参、外参标定 -> 立体匹配 -> 光学三角形求解,这里面最核心、也最影响重建效果的就是立体匹配。
贴几张本人实验的图(用的最基本的格雷码结构光):

以上说的都是双目视觉三维重建,实际上还有其它一些重建方法,如早期的探针法,简单粗暴,直接拿探针在物体表面移动,一个点一个点测坐标;还有一类通过直接测距来进行三维重建,如超声波、TOF,即对物体表面逐点用声、光程差来测距,从而得到三维点云;光学方法分为主动和被动两大类,主动和被动指的是是否向物体表面投光,主动方法有激光扫描、相位测量以及我毕设的研究课题结构光方法等,被动方法有单目视觉(如阴影法)和上文所述的立体视差方法等等。
目前还有一类三维重建方法非常火:SFM(Structure from Motion),这类方法的特点是不需要相机参数,仅仅根据一系列图像就能进行三维重建,也就是说,你随便拿个手机对着物体拍一些图片就能重建这个物体的三维模型,大家可以去体验下AutoDesk公司的Autodesk 123D Catch(http://www.123dapp.com/login.request.do?service=/catch),除了近距离物体的三维重建,SFM还有更激动人心的应用:大型场景三维重建,感兴趣的可以看看这个Building Rome in a Day,他们在flickr上搜索两百万张罗马的照片,通过亚马逊提供的计算服务,最终得出整个城市的三维模型,是不是又有云计算、大数据的感觉。。。这波人貌似有几个是Google Earth团队的。优酷上有个很短的视频:building rome in one day(https://v.youku.com/v_show/id_XMTUwMDg0OTQw.html)视频原理上其实也不难理解:从特征点对入手,反向求解出相机的内外参(选定一个相机作为世界坐标系),然后重建更多的点。
大家应该对电影《普罗米修斯》里面的用于洞穴建模的飞行器印象深刻:

再看看目前发展迅速的无人机,这方面确实有很多东西值得尝试。
最后从产品上来说,现在的三维扫描仪已经很多了,不过国内自主技术的不多(很多都是做国外产品的代理)。
观点二
作者|Tiotao
https://www.zhihu.com/question/23418797/answer/2883395278
三维重建是一个很激动人心的技术,正打算在这个方向做自己的毕设。
另外自己刚入门不久,如果讲得有错误或者不清楚的地方,欢迎指出。
三维重建有很多种方法,比如:
Binocular Stereo [1]
也就是双摄像头重建。
Depth from Focus [2]
通过不停修改摄像头的焦距,分辨出图像那里是模糊的,哪里是对焦的,从而得出对上焦的那个点和镜头之间的距离。
我想说的是:
Structure From Motion [3] 。这是一种通过摄像头在不同位置捕捉照片来对实物进行三维重建的办法。它不需要知道摄像头的位置,这些都可以通过照片本身计算出来。
要了解Structure From Motion,可以先从简单的例子开始。I是第一张照片,J是移动摄像头后的第二张照片。假设照相机没有旋转,也没有进行前后移动,或者修改焦距,只是在左右上下方向平移。那么通过点x在I和J之间的位置差,我们就可以知道摄像机移动的位置。
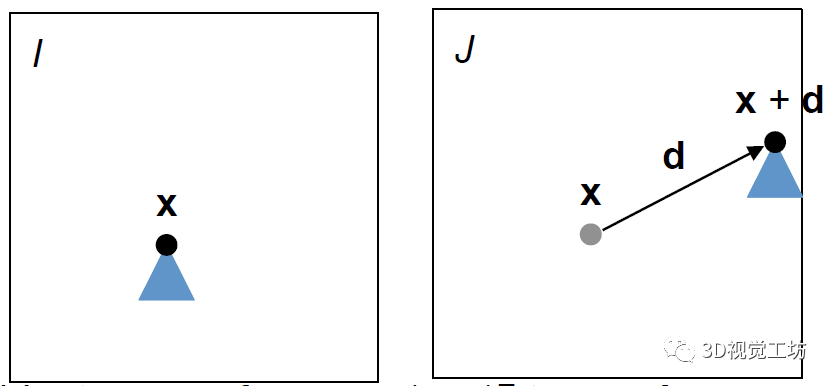
同时,x点在照相中的位置,是和相机位置,以及x点在现实世界中的位置相关的。具体下图可以解释。
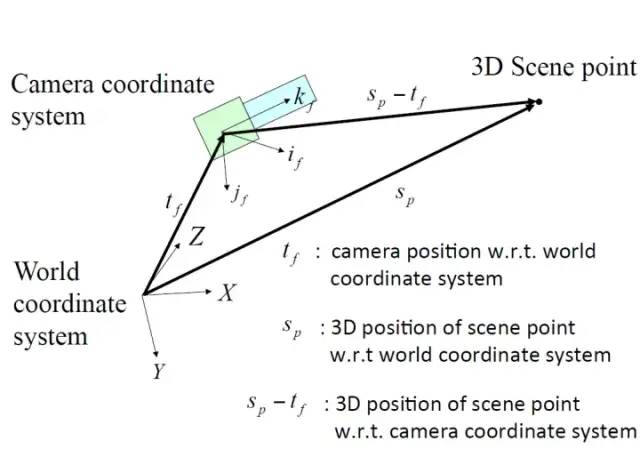
要看懂下图,先要了解几个定义。
Camera Coordinate System,就是根据相机朝向定义的坐标系。也就是照片上的坐标系。if就是照片上的x轴,jf就是照片上的y轴。
World Coordinate System,就是根据现实世界定义的坐标系。这个并没有强制什么方向是X,什么方向是Y,什么方向是Z。随便怎么定义都可以,但是一般来说Y朝下,X朝右,Z朝前。三个方向互相垂直。
观察上图我们可以发现,x点(3D Scene Point)在世界坐标系的位置,Sp,和相机在世界坐标系中的位置,也就是tf,之间的向量差,就是相机到x点的向量。这个向量正代表了x点在图像中的位置。
也就是说,通过知道相机在世界坐标轴上的位置,x点在图像的位置。我们就可以得出x点在世界坐标轴上的位置。通过求解相机运动参数获得实物的坐标,这就是SFM的精髓。
当然,现实场景中的SFM更加复杂,因为相机除了平移还会旋转。因此需要大量的数据。也就是说两张照片是远远不够的。
SFM的核心是采集特征点,选择有意义的点进行跟踪。近年来又有一种新的方法,Large-Scale Direct Monocular SLAM [4],不需要采集特征点,而是尽可能多地利用一张图片的信息,建立每一个像素的距离值。看上去需要花很多计算资源,但是事实上这种方法非常高效。相机不停地采集图片,程序根据最新的图片判断、修正依照之前图片生成的像素距离值,不断完善演进。照片拍得越多,模型越精确。具体还在研读,等到读透了再来更新。
参考
[图 1, 2] A/P Ng Teck Khim, CS4243 Computer Vision and Pattern Recognition Lecture 5, 6 , National University of Singapore
[1,2,3] R. Szeliski. Computer Vision: Algorithms and Applications. Springer, 2010.
[4] Large-Scale Direct Monocular SLAM (https://vision.in.tum.de/research/vslam/lsdslam?redirect=1)
观点三
作者|一个好人
https://www.zhihu.com/question/23418797/answer/39751292
这个问题其实是摄影测量中的“立体像对前方交会”(Forward Intersection),就是通过对某一物体从两个不同角度拍照来确认物体位置的方法。
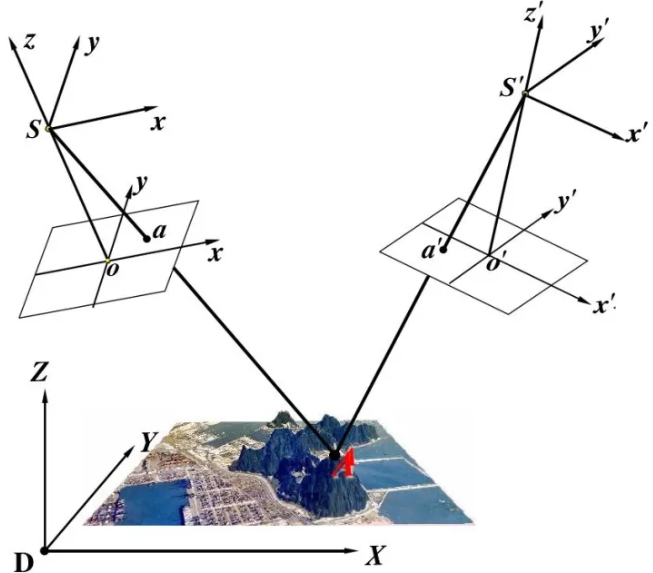
上图中是从空中俯拍地面的示意图。
A是地面上的一个点,我们需要求得它的坐标;两个白色的平行四边形是从上空不同位置拍摄A的两张相片;a和a'是A在两张相片的成像,即A的投影;S和S'是两张相片的摄影中心。可以看出SaA还有S'a'A都是共线的。
我们可以逆向的来理解求解A坐标的过程。我们学过几何学都知道一个定理:“两条直线可以确定一个点”,如果我们知道两条经过A的直线,就可以求出A的坐标;我们恰好可以从两张相片各找出一条直线,分别是SaA和S'a'A。
然而我们不知道这两条直线的几何参数,更无法求交点坐标。但是我们知道“两点可以确定一条直线”,如果我们知道直线上的两点,不就可以确定直线的几何参数了吗?所以我们可以通过S和a确定直线SaA。于是,问题的关键就是如何获取S和a的坐标。因为我们可以任意选取拍照的位置,所以S的坐标我们可以事先知道。而a的坐标呢?别忘了我们拍的照片还没派上用场,我们可以在照片上量测出a的坐标。这样整个流程就走通了。
(为了便于阅读,省略了一些重要过程。比如,即使量出a的坐标,但是和S的坐标不在同一坐标系内,所以需要坐标转换,那么我们就要知道两个坐标系的关系,所以相片平面的倾角必须已知)主要用到的数学公式是共线条件方程式( collinearity condition equation),它利用的是S,a,A三点共线的这个重要性质,它的作用是建立起摄影中心S,像点a和物点A三者的几何关系。
下面是共线条件方程式的代数形式,式子中的XYZ就是A的坐标:
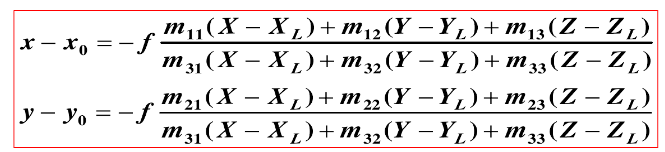
由于有左右两张相片,我们可以写出两个共线条件方程式建立方程组
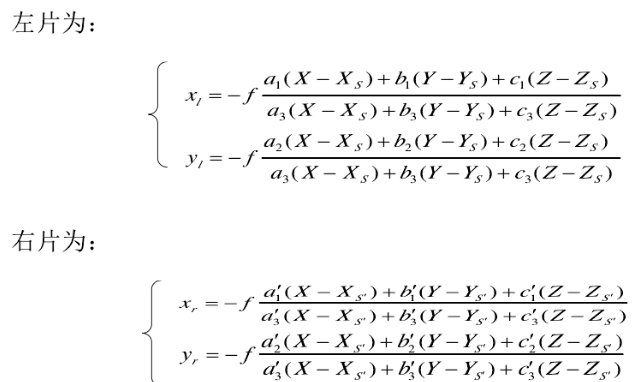
联立可以解出A的坐标(X,Y,Z)
注:
由于实际中测量误差的不可避免,直线Sa和直线S'a'一定不会严格相交,上式是无解的。所以还要运用平差知识才能求出结果。
粗浅的说,原本我们要想描述A的位置,可以直接说“A在我的南10米,东5米处”;而我们在无法直接描述A的位置的情况下,可以多绕了个弯来解决这个问题:“B在我的南5米,西5米处;而A在B的南5米,东10米处”,摄影测量中的相片就好比这个B,是一个传递位置信息的的媒介。
另外题主提到的应用问题,摄影测量从十九世纪就开始用于测量工作,并发展为测绘学科的一个方向,现在又和计算机视觉等领域结合起来,应用是十分广泛的。
往期回顾
史上最全综述 | 3D目标检测算法汇总!(单目/双目/LiDAR/多模态/时序/半弱自监督)
国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称

















 9106
9106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









