



 提出一种新的知识蒸馏方法,利用结构相似度(SSIM)改进了传统l(p)-范数的距离度量,有效提升了目标检测任务中小型模型的表现。
提出一种新的知识蒸馏方法,利用结构相似度(SSIM)改进了传统l(p)-范数的距离度量,有效提升了目标检测任务中小型模型的表现。
点击进入→自动驾驶之心【目标检测】技术交流群

摘要:
知识蒸馏(KD)是深度神经网络中著名的训练,它将由一个大的教师模型获得的知识传递给一个小的学生。KD已经被证明是一种有效的技术,可以显著提高学生在各种任务中的表现,包括目标检测。因此,KD技术主要依赖于中间特征水平的指导,这通常是通过最小化训练期间教师和学生激活之间的l(p)-范数距离来实现的。本文提出了一种基于结构相似度(SSIM)[28]的像素独立l(P)-范数的替代方法。在损失公式中考虑了附加的对比度和结构线索,并考虑了特征空间中的重要性、相关性和空间依赖性。在MSCOCO[16]上的大量实验证明了本文的方法在不同的训练方案和体系结构中的有效性。本文的方法只增加了很少的计算开销,实现简单,同时性能显著优于标准的l(p)-范数。此外,使用基于注意力的采样机制的更复杂的最先进的KD方法[13,33]的性能优于普通模型,包括使用Faster R-CNN R-50[21]的+3.5AP增益。
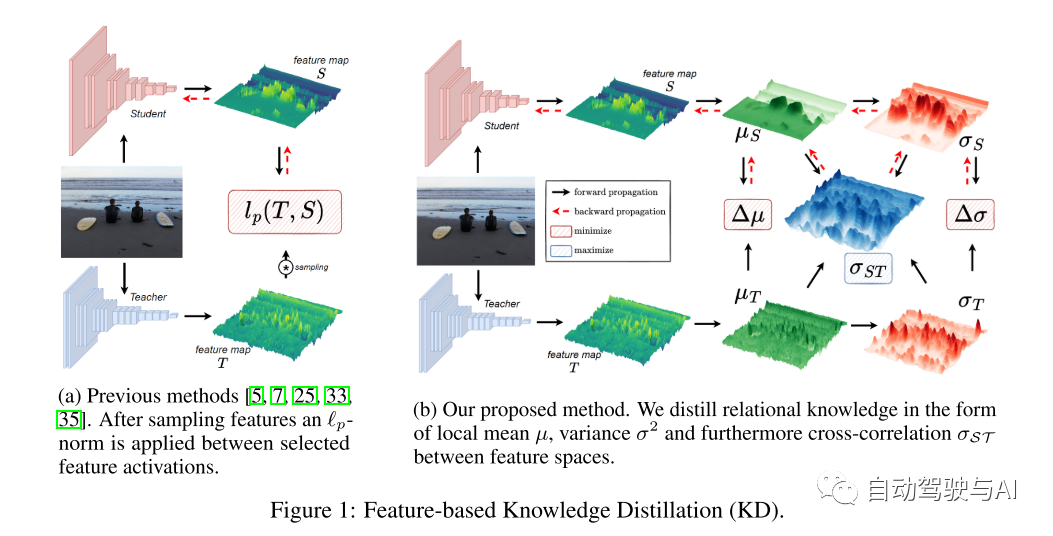
介绍:
在过去的十年中,卷积神经网络(CNNs)已被证明是解决计算机视觉基本任务的一个非常有效的工具[14]。CNNs的一个主要应用包括实时感知系统,例如自动驾驶汽车,在自动驾驶汽车中,目标检测通常是一项非常重要的任务。然而,将CNNs部署到实时应用程序中,会对内存和延迟带来严格的限制。另一方面,最先进的检测器性能的提高通常伴随着内存需求和推断时间的增加[12]。因此,网络模型的选择及其相应的检测性能受到严格限制。为了解决这一问题,人们提出了一些技术,如剪枝[8]、权重量化[9]、参数预测[6]和知识蒸馏(KD)[11]。在这项工作中,本文对后者特别感兴趣,因为它提供了一种直观的性能改进方式,而不需要对现有网络进行体系结构修改。
使用KD,在训练期间,由计算开销较大的教师模型获得的知识被转移到较小的学生模型中。KD已被证明在分类[11]、分割[19]等任务中非常有效,尤其是最近在检测方面取得了相当大的进展[5,7,13,33,35]。由于典型检测模型输出空间的复杂性,在中间特征层应用KD是必要的,因为仅仅依靠基于输出的KD已经被证明是无效的[3,5,7,13,15,25,33,35]。在基于特征的KD中,除了现有的目标外,还引入了一个训练目标,它使教师和学生激活之间的误差最小化,并且是由单个特征激活之间的l(p)-范数距离定义的事实上的标准[5,7,13,25,33,35],如图所示 1a. 然而,l(p)-范数 忽略了特征图中存在的三个重要信息:(i)特征之间的空间关系,(ii)教师和学生特征之间的相关性,(iii)个体(individual)特征的重要性。本文注意到最近的工作(含蓄地)侧重于通过假设目标区域更“知识密集”[5,13,25,35]来通过抽样特征激活的机制绕过后一点。然而,正如Guo et al. [7] (2021)所论证的那样,即使只提取背景特征激活也可以导致显著的性能改进,因此不能假设仅目标区域包含有用的知识。采样机制还引入了其他缺陷,这些缺陷可能限制了它们在现实世界应用中的更广泛实施,例如需要标记数据[7,13,25]。
在这项工作中,本文提出了结构知识蒸馏,它旨在改善作为KD方法核心驱动的l(p)-范数相关的缺点,而不是设计一个越来越复杂的采样机制。本文的主要洞察力在图1b得到了说明:CNN的特征空间可以局部分解为亮度(均值)、对比度(方差)和结构(互相关)分量,这种策略在图像域中以SSIM[28]的形式得到了成功的应用。新的训练目标变成最小化均值和方差的局部差异,最大化教师和学生激活之间的局部零归一化互相关。这样做使本文能够捕捉包含在空间关系中的额外知识,以及教师和学生的特征激活之间的相关性,而不是直接最小化个体激活的差异。
主要贡献:
本文提出了结构知识蒸馏,它引入了l(SSIM)和变量(variations),作为目标模型中基于特征的KD的l(p)-范数的替代。这使得在学生和教师网络的特征空间中捕获表现为局部均值、方差和互相关关系的额外知识。
本文通过对特征空间的分析说明,本文的方法与l(p)-范数相比侧重于不同的区域,因此仅从目标区域采样是次优的,因为整个特征空间可能包含依赖于激活模式的有用知识。
本文通过在MSCOCO上进行广泛的实验,证明了对于各种训练设置和模型体系结构,检测精度有一致的定量改进[16]。本文的方法甚至可以达到或超过经过精心调优的最先进的目标采样机制[13,33],并且只需引入一行代码就可以从根本上实现这一点。
论文设计:
总览
本文从定义基于特征的蒸馏损失的一般形式开始。为了这项工作的目的,本文将检测器分为三个部分:(i)主干,用于提取特征;(ii)颈部,用于在不同尺度上融合特征(通常是FPN[17]),以及(iii)头部,用于生成回归和分类分数。对于基于特征的KD,本文在颈部的输出分别从教师和学生中选择中间表示 和。基于特征的T和S之间的蒸馏损失可随后表示为:
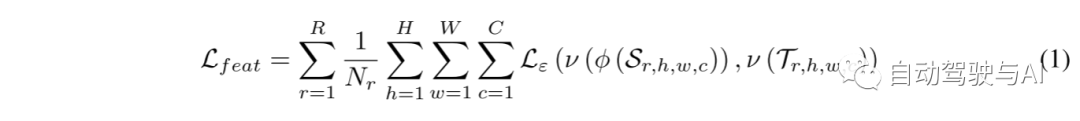
测量差异
正如所确定的,Lε的事实上的标准选择是p范数。p=2惩罚大的错误,但对小的错误更容易容忍。另一方面,p=1不会对大错误进行过度惩罚,但对较小的错误进行更严厉的惩罚。一般形式的P范数由下式给出
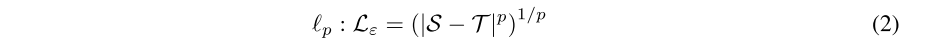
显然,这样的函数不能捕捉特征之间的空间关系。为了捕获二阶信息,本文需要至少涉及两个特征位置,因此本文将问题陈述从逐点 (point-wise) 比较改为局部逐块 (patch-wise) 比较。对于每一个这样的patch,本文提取三个基本性质:均值μ、方差σ2 和捕捉S和T之间关系的 互相关σ(st)。本文遵循[28]并使用大小为11×11的高斯加权patch F(σF)和σ(F) = 1.5计算这些量。所提出的SSIM框架[28]比较了每一个属性,因此由三个分量组成:亮度L、对比度C和结构S,其定义如下:
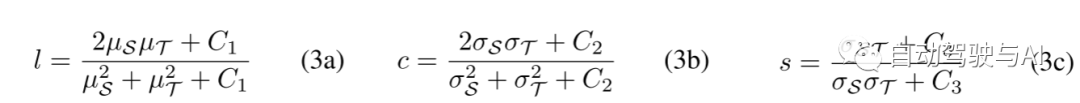
方程(3)的一个重要性质。由于分母中的二次项,它对L和C的相对变化赋予了更大的重要性。此外,s是S和T之间的零归一化相关系数的直接度量,因此被公式化为它们的协方差和标准差的乘积之间的比率。当eq. (3)的范围是[−1, 1](As the range of eq. (3) is [−1, 1]),组合三个分量l,c,s得到以下目标:
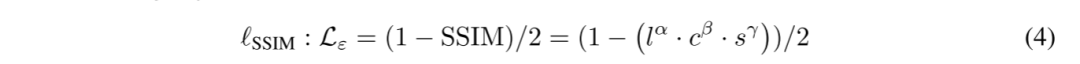
因为本文的方法是纯粹基于特征,因此独立于类型的头或边界框的标签,本文只需将L(feat)添加到现有的检测目标函数L(det)(通常是L(cls)和L(reg))并使用加权因子λ, 导出总体训练目标如下:
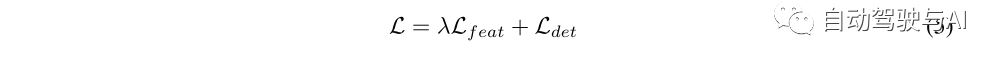
实验结果:
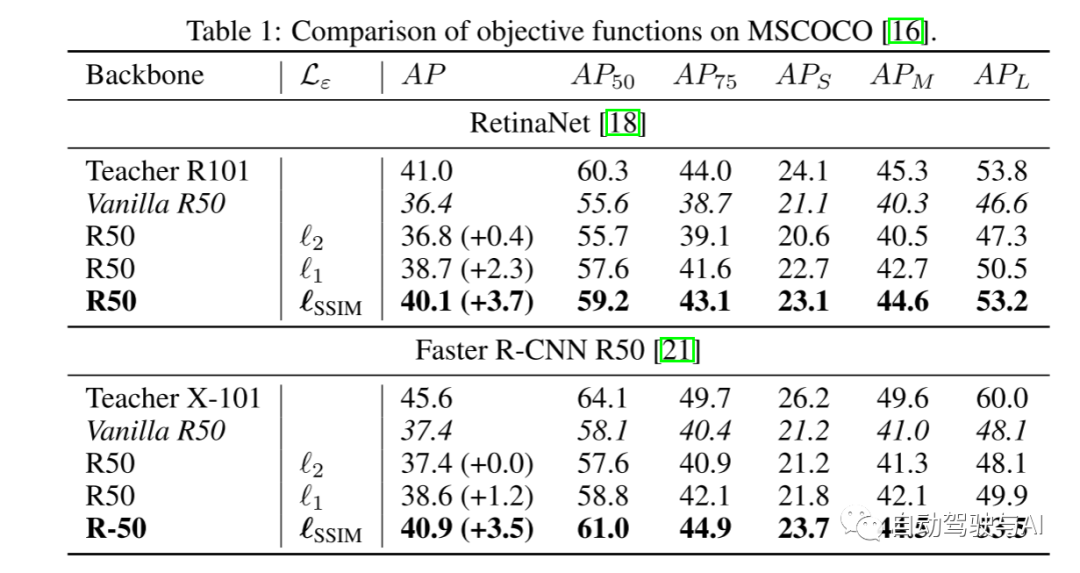
图2:在输出尺度 r = 1下,不同图像的特征空间中损失幅度的分布,在MSCOCO上的所有通道和12个训练时期上取平均值[16]。从左至右:图像,学生用 l(2) 训练,学生用 l(ssim) 训练。较深的颜色表示较高的损失,对象区域已用边界框高亮显示,并且特征图已被归一化。

图3:从RetinaNet [18]中间颈部输出尺度r = 1随机采样的通道的定性比较。颜色越浅表示激活值越高。

图4:每个单独组件亮度、对比度和结构的通道平均损失幅度分布,在MSCOCO [16]上的12个训练时段内取平均值。

表2:RetinaNet[18]在MSCOCO[16]上的目标函数比较。α调节亮度,β调节对比度,γ调节结构。
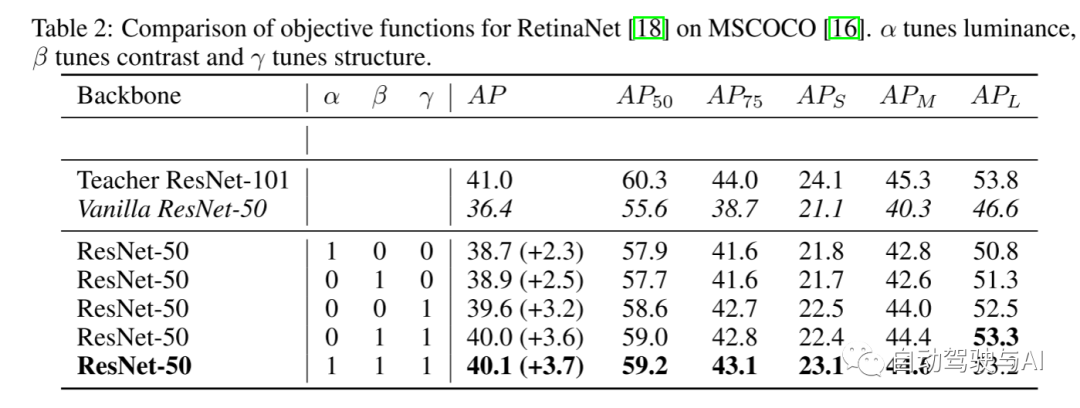
图5:顶部行:RetinaNet R101[18]教师中的通道平均激活。随后的行说明了教师和学生之间激活的通道平均差异,分别表示用 第2行:亮度(α)。第三行:对比度(β)。第4行:结构(γ) 进行蒸馏。r 表示特征映射的输出尺度(公式1)。差异已经归一化,颜色越深表示值越高。

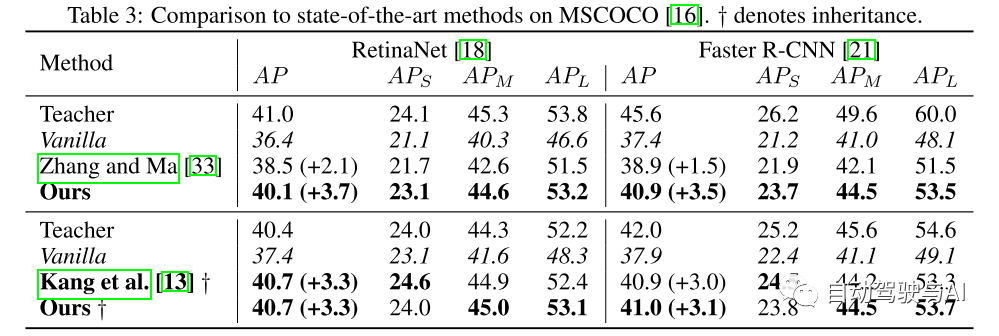
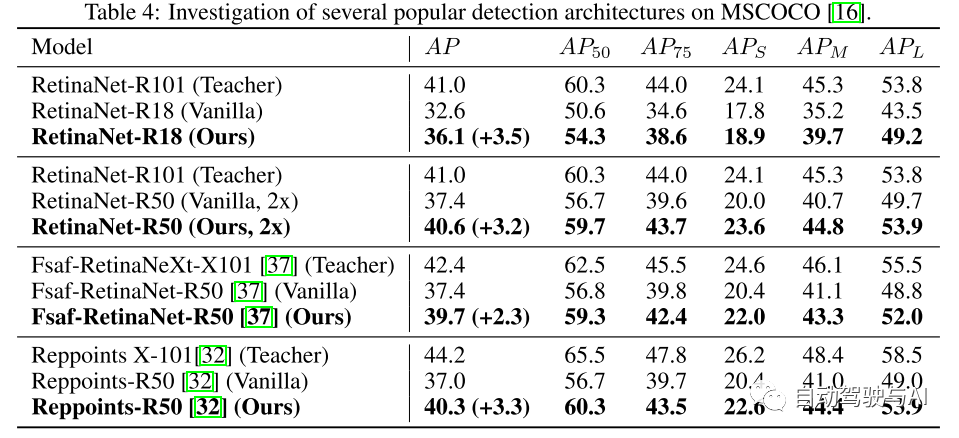

图6:改变超参数时的性能差异。顶部:KD loss prevalence λ。底部:内核大小F。
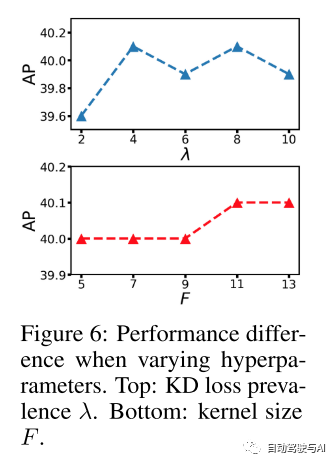
图7:RetinaNet R-50[18]AP评分不同的盒子大小。阴影区域代表普通模型,实心区域代表通过本文的蒸馏方法获得的性能增加。
重现性陈述
本文所有的实验都基于公开可用的框架[4,29]和数据集[16]。教师和学生特征之间KD损失的示例实现如下所示。省略导入并使用Kornia[22]这样的库,从l(2)到l(SSIM)的更改只需要更改一行代码。

参考
[1] Structural Knowledge Distillation for Object Detection
往期回顾
Radar-LiDAR BEV融合!RaLiBEV:恶劣天气下3D检测的不二之选
【知识星球】日常干货分享


【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、规划控制、模型部署落地、自动驾驶仿真测试、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!


















 441
441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









