



 本文介绍了一种名为nRPN的网络,用于解决区域提议网络(RPN)中的难负样本不足问题。nRPN从RPN的误报中学习,并提供难负样本以改善RPN性能。
本文介绍了一种名为nRPN的网络,用于解决区域提议网络(RPN)中的难负样本不足问题。nRPN从RPN的误报中学习,并提供难负样本以改善RPN性能。
转自:集智书童
Region proposal task是生成一组包含目标的候选区域。在这项任务中,最重要的是在固定数量的proposal中提出尽可能多的真实候选者。然而,在一个典型的图像中,与大量简单的负样本相比,很难的负样本太少了,因此区域提议网络很难训练硬负样本。由于这个问题,网络倾向于提出
hard negatives作为proposal,而未能提出真实的候选者,这导致性能不佳。在本文中提出了一个Negative Region Proposal Network(nRPN)来改进区域提议网络(RPN)。nRPN从RPN的误报中学习,并为RPN提供难的负样本。我们提出的nRPN可以减少误报和更好的RPN性能。使用nRPN训练的RPN在PASCAL VOC 2007数据集上实现了性能改进。
1、简介
区域提议网络主要用于基于区域的目标检测器的第一阶段,通过将目标与背景区分开来。在以前的工作中,有使用穷举搜索适应分割的选择性搜索方法和从边缘生成边界框的边缘框方法。在 Ren 等人的研究中,Region Proposal Network (RPN) 可以预测目标得分和具有多个anchor比例和比率的建议的坐标。此外,Lu 等人提出了自适应搜索策略,将图像递归地划分为子区域。这些方法通过减少候选区域的数量和更好的检测器性能来提高计算效率。
区域提议网络通过在前景(正)和背景(负)两个类别之间进行分类的二元分类来学习对象性。然而,前景-背景类别不平衡是区域提议和目标检测任务中的一个具有挑战性的问题。与前景示例相比,背景示例过于简单,损失低,导致模型退化。为了解决这个问题,需要高损失的难负样本。困难负样本挖掘有很多工作,例如在线困难样本挖掘(OHEM),它通过选择使用提升决策树的表现最差的示例来仅训练高损失建议。
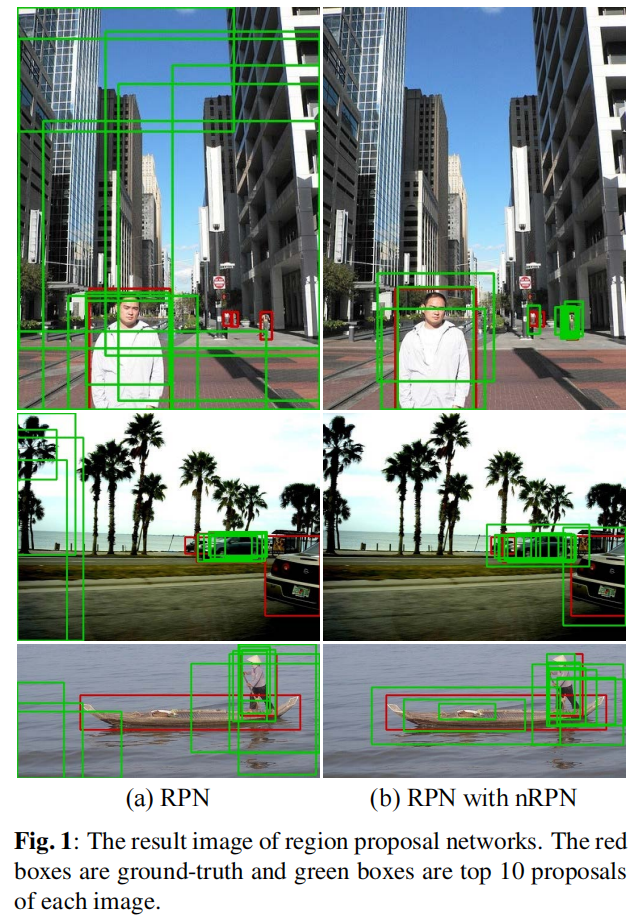
在本文中提出了一个名为 Negative Region Proposal Network (nRPN) 的困难负样本学习网络,而不是困难样本挖掘。nRPN 旨在提出 RPN 可能不正确的困难负样本。nRPN 使用来自 RPN 的误报进行训练,同时,RPN 使用 nRPN 提出的难负样本进行训练。RPN 和 nRPN 都是同时训练的,它们相互提供正例或负例,并逐渐生成更难的例子。这种方法可以提高 RPN 的召回率和更好的检测器性能(图 1)。此外,还提出了考虑每个anchor和ground-truth(GT)之间的Intersection over Union(IoU)的损失函数,以根据IoU应用不同的损失。在本文中,主要贡献是,
提出的
nRPN从RPN的误报中学习难负样本,并为RPN提供难负样本。通过将RPN和nRPN一起训练,可以很容易地从仅用于训练的nRPN中得到困难负样本。还提出了
Overlap Loss来根据anchor和GT的重叠值计算不同的损失。Overlap Loss对于学习大物体和小物体的大小都更有效。
2、本文方法
2.1、整体架构
对于基础区域提议模型,使用来自 faster-RCNN 的 RPN。RPN 通过anchor的各种比例和比例来执行区域提议,anchor位于特征图的每个像素上。RPN 通过将输入图像通过特征提取器 (VGG-16) 和滑动窗口来输出这些anchor的目标得分和坐标。
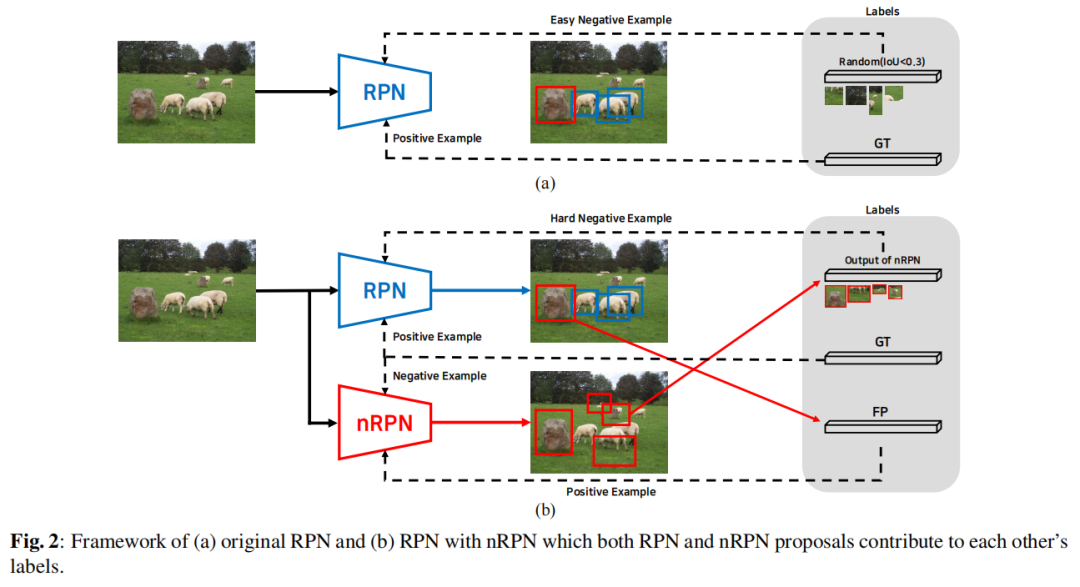
由于 Bengio 等人表明,从更容易的任务开始学习,然后逐渐增加学习难度可以提高泛化能力和更快的收敛速度,因此首先训练 RPN 而不是 nRPN。在图 2(a) 中,RPN 标签由 GT 和随机选择的与 GT 的 IoU 低于阈值(0.3)的简单负例组成。在训练少量 epoch 后,RPN 学习对象性。然后,nRPN 开始在 RPN 提议中使用误检 (FP) 进行训练。如图 2 (b) 所示,nRPN 的提议被用作 RPN 的困难负样本,RPN 的误检被用作 nRPN 的正样本。两个网络同时训练,但彼此不共享权重。
2.2、nRPN
nRPN 是一个学习困难负样本并预测 RPN 误报的网络。因此,nRPN 的正例是误检,nRPN的输入是 RPN 输出的不正确示例。与误检率非常低的检测器不同,RPN 的误检率很高。因此,很容易得到 nRPN 的误检。此外,由于 nRPN 预测困难负样本,因此 RPN 可以轻松地使用困难负样本进行训练,而不是使用其他挖掘难样本并用它们重新训练的方法。
作者将误检定义为目标得分高于 0.7 但与 GT 的 IoU 低于阈值(0.3)的anchor。另一方面,RPN的负样本是nRPN不包括GT的提议。由于 nRPN 是用于预测困难负样本的网络,它不需要边界框回归。
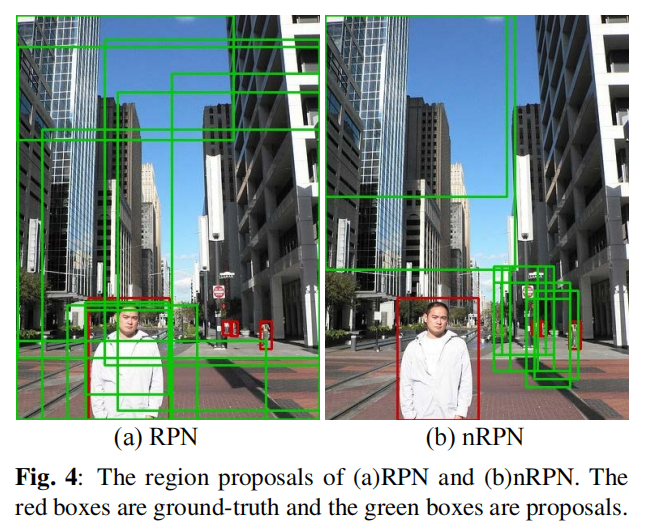
在图 4 中绘制了原始 RPN 和 nRPN 的前 10 个提议。由于 RPN 提出了很多高分的误检,它未能提出 GT。在图 4 (b) 中,表明 nRPN 的提议是非目标区域,但 RPN 可能是错误的。
2.3、Overlap Loss
正如上面提到的,每个anchor都被标记为前景和背景。每个前景anchor与GT的IoU值不同,这意味着成为目标的概率也不同。也就是说,每个前景anchor的预期objectness score应该被认为是它的IoU值而不是1。因此,根据GT和每个前景anchor之间的IoU,预测objectness score 除以方程(1)中的IoU。
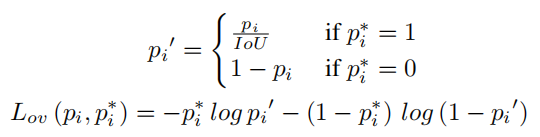
由于小目标与anchor的 IoU 往往比大目标低,因此很难在 RPN 中进行训练。然而,这种Overlap Loss可以帮助学习更平衡的目标大小。在等式(1)中, 和 表示 GT 标签和anchor i 的预测概率。将此损失称为Overlap Loss 。总损失 在等式 (2) 中,其中 是平滑 。
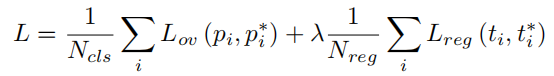
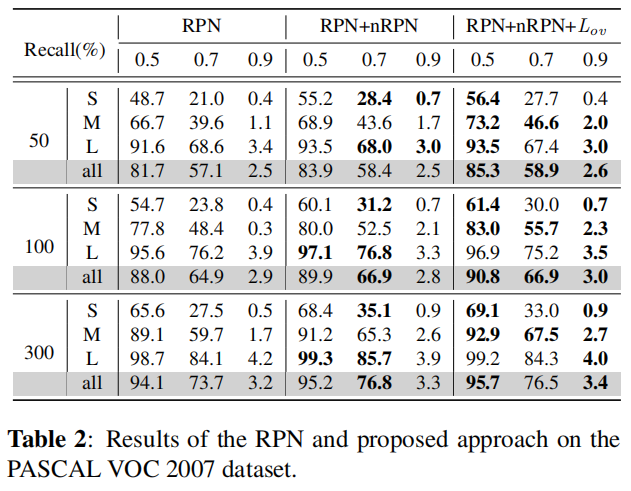
3、实验
4、参考
[1].N-RPN: HARD EXAMPLE LEARNING FOR REGION PROPOSAL NETWORKS.
【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D感知、多传感器融合、SLAM、高精地图、规划控制、AI模型部署落地等方向;
加入我们:自动驾驶之心技术交流群汇总!
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D感知、多传感器融合、目标跟踪)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









