



 本文概述了两篇关于3D多目标跟踪的论文:AB3DMOT利用卡尔曼滤波与3DIOU数据关联,而EagerMOT则融合2D和3D检测,提出传感器融合策略。文章详细介绍了它们的运动模型、数据关联方法和改进之处,展示了在融合不同模态和解决遮挡远距问题上的优势。
本文概述了两篇关于3D多目标跟踪的论文:AB3DMOT利用卡尔曼滤波与3DIOU数据关联,而EagerMOT则融合2D和3D检测,提出传感器融合策略。文章详细介绍了它们的运动模型、数据关联方法和改进之处,展示了在融合不同模态和解决遮挡远距问题上的优势。
1. IROS 2020-AB3DMOT:A Baseline for 3D Multi-Object Tracking and New Evaluation Metrics
代码链接:https://github.com/xinshuoweng/AB3DMOT
文章链接:http://www.xinshuoweng.com/papers/AB3DMOT_eccvw/camera_ready.pdf
出发点:提供基于3d目标检测的多目标跟踪base_line。
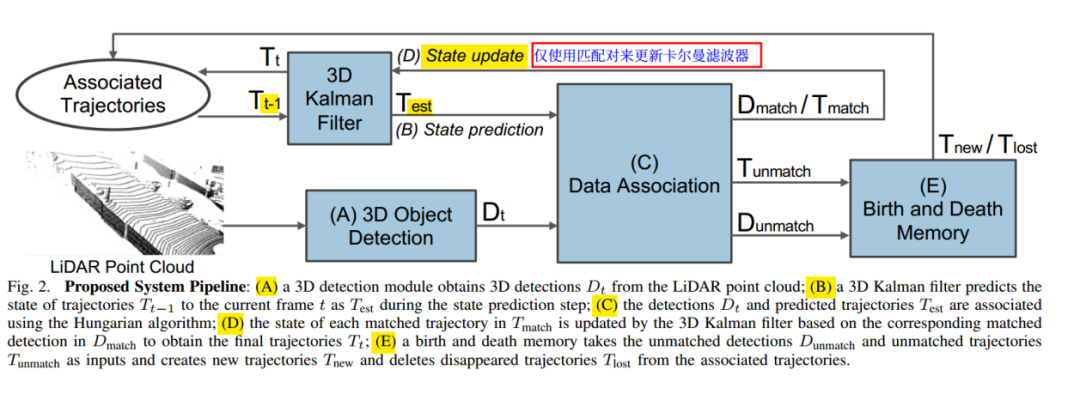
因为是baseline算法,比较简单,这边简单对要点做个描述。总体跟踪过程是Kalman滤波+匈牙利匹配,只使用匀速运动模型.
3D卡尔曼的状态变量是(x,y,z,θ,l,w,h,s,Vx,Vy,Vz),没有包含角速度是因为实验发现角速度对性能提升没有帮助。
数据关联部分,输入为卡尔曼预测结果T和当前检测结果N,首先使用3D IOU或者中心坐标距离构建关联矩阵.在这里作者丢掉了IoU小于一定阈值或者中心点距离大于一定值的匹配结果。然后就使用匈牙利匹配进行匹配,得到匹配上的障碍物和未匹配的障碍物。
对于匹配上的障碍物,使用当前检测结果作为观察,更新卡尔曼状态。
Kalman更新模块涉及到了方向校正的问题。这里为了防止检测结果中朝向角可能会出现相差180°的问题,对于预测和观测朝向角相差大于90°的情况,那么修正预测结果,会对预测变量中的朝向角增加180°。
创新
将Kalman滤波器扩展到3D领域
提供了3D MOT的评估工具
提出了新的评估指标,考虑不同的轨迹置信度阈值
2. ICRA 2021-EagerMOT: 3D Multi-Object Tracking via Sensor Fusion
1.总览:
文章链接:http://arxiv.org/pdf/2104.14682v1.pdf
代码链接:https://github.com/aleksandrkim61/EagerMOT
出发点:该算法是融合2d和3d检测来源的mot算法,且采取了两阶段的数据关联。问题:3D点云的检测和跟踪有精确的距离测量,但是远距离的物体扫到的点就很少了,经常出现漏检,而融合3D检测距离很准而2D检测看得更远的优势,提高3D目标跟踪对遮挡、远距离目标跟踪的效果。
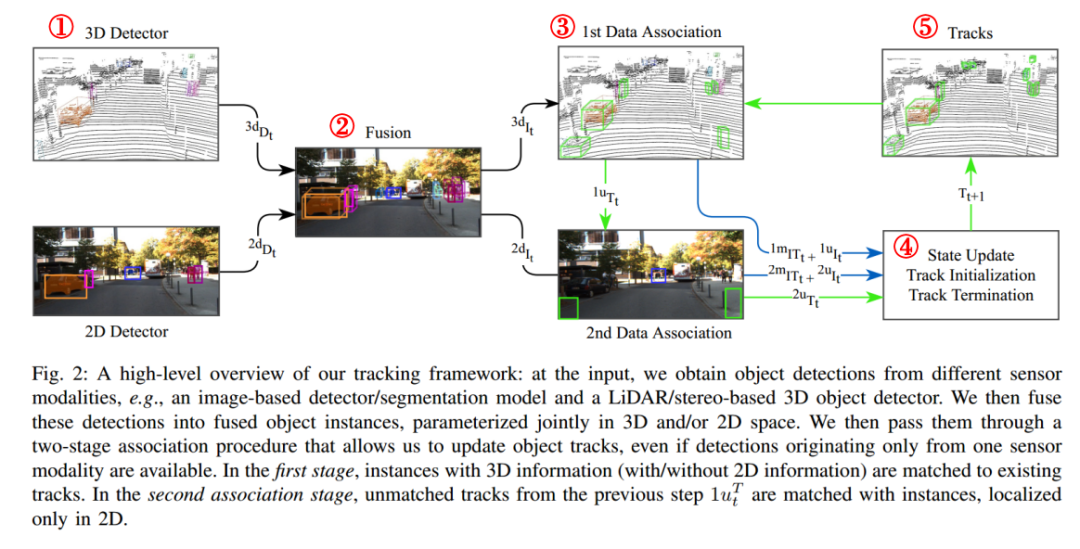
2.介绍:
基于激光雷达的3D追踪方法:对反射率敏感,信号稀疏,只能在有限范围内有效。
基于图像的2D追踪方法:无法获得3D位置信息,对部分遮挡的或者距离很远的物体具有鲁棒性。
EagerMOT提出了一个简单但有效的多阶段数据关联方法,可以使用潜在的不同模态下的不同检测器。通用性强,适配多种传感器组合方式:LiDAR+前置摄像头;LiDAR+多个非重叠摄像头;只有摄像头。
3.Method:
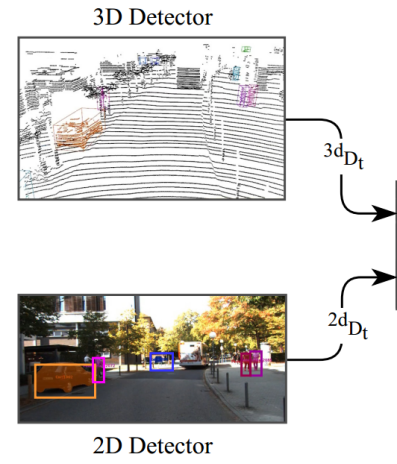
1,检测Detector
信息源:3D:多线激光雷达,产生3d检测框;2D:图像,产生2D检测框。
这两条线的信息可以不同时具备。
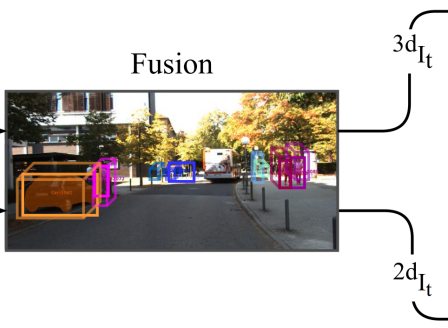
2,Fusion(融合)
不同检测器检测结果先融合后关联:
使用3D结果在图像像素坐标系下的2D投影框与2D图像检测框结果的IoU作为相似度衡量标准,
使用贪婪算法匹配2D结果 和3D结果 得到融合结果。
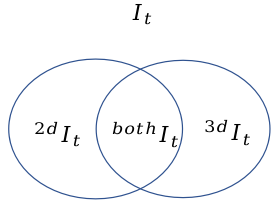
多摄像头时的策略:
对于每一个摄像头执行上述流程最终对于有多个2D结果匹配的3D结果取IoU最大的匹配。
3,Data Association(数据关联)
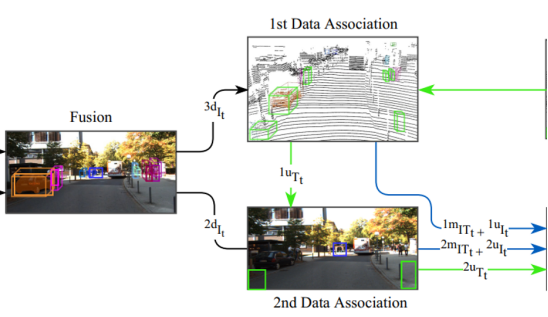
任务:将当前帧中的所有观测对象与跟踪序列的卡尔曼预测进行关联,论文的二阶段匹配可以相互独立。
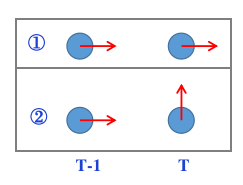
状态空间设计:3D状态,与AB3DMOT一致,3D包围框信息以及三轴速度信息使用常速度运动模型
2D状态,2D包围框信息。
第一阶段数据关联:3d关联
使用贪心算法关联检测到的3D状态和上一帧的追踪3D物体状态,使用考虑速度方向的欧式距离度量作为相似度度量。
使用贪心算法关联检测到的3D状态和上一帧的追踪3D物体状态,使用考虑速度方向的欧式距离度量作为相似度度量。
α
402 Payment Required
γ为包围框的偏航角
注意:速度方向夹角为0时α最小
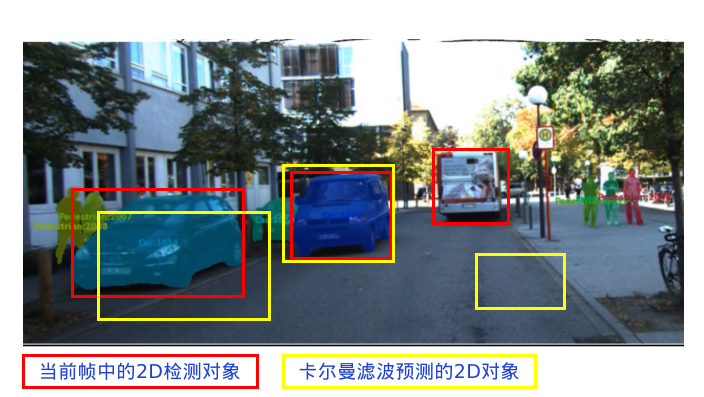
第二阶段数据关联:2d关联
关联2d检测结果与2d追踪,直接使用2D IoU作为相似度衡量标准
4,状态更新
2D、3D状态都进行更新;
2D状态直接使用当前帧中的检测结果覆盖;
3D状态需要更新卡尔曼滤波器状态,使用融合了检测结果和卡尔曼滤波预测的最优值更新;
如果某物体在当前帧没有对应的3D信息只含有2d信息,其对应序列直接使用卡尔曼滤波的预测结果更新。
跟踪周期控制:
类似于AB3DMOT:
当某一状态(2D/3D)超过Age_max帧没有更新,则删除此状态;
当某一物体由2D信息更新超过Age_2d帧后才使用关联上的3D信息进行更新;
未被关联的2D检测结果产生新的追踪状态。
主要意义:
能使用2D信息对无法获取3D信息的对象进行补盲。
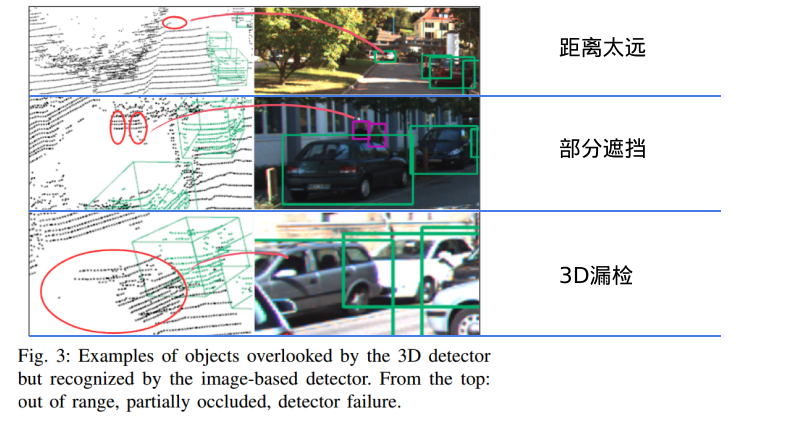
实验部分请关注原文。
3. SimpleTrack: Understanding and Rethinking 3D Multi-object Tracking
1.总览:
论文:https://arxiv.org/abs/2111.09621
代码:https://github.com/TuSimple/SimpleTrack
本文将3dmot算法分解为了四个模块:检测模块、运动模型模块、关联模块、轨迹管理,并且对四个模块现在常见的一些做法进行了分析和改进,是一篇不错的rethinking论文。在分析的基础上,作者提出相应的改进,从而形成一个强大而简单的基线:SimpleTrack。
2,运动模型模块
检测模块没啥好说的,就是接收3d检测结果,做一些坐标转换(如转到world坐标系)。
运动预测模块主要依据某些运动学模型预测后续运动,进而实现后续与观测量(检测结果)的匹配。目前常用的运动学模型分为两种,卡尔曼滤波法(KF)和速度预测模型法(CV, 如CenterPoint这样把两帧点云放进去预测速度)。其中卡尔曼滤波在观测质量较低时可以提供更平滑的预测结果,而速度预测模型法可以较好的处理突发和不可预测的运动。作者通过实验分析发现,帧率较低时(如2hz)时,CV法更占据优势,而帧率较高时,KF法更占优势。
3,Data Association(数据关联)
关联模块主要有两种做法,一种是基于IoU的关联方式,一种是基于距离的关联方式。这两种方式都可以构建cost矩阵。前者是IoU大于阈值就关联上了,反之就没有关联上。后者一般使用欧式距离或者马氏距离(也有类似EagerMot那样考虑了余弦距离和欧式距离加权的做法)。这两种方法各有优劣,对于基于IoU的方法而言,一旦IoU过小就关联不上,但是这个观测仍然是存在的,这就会导致某些目标的轨迹提前消失!而对于距离的关联方式而言,则可能会导致误检。因为如果用中心点距离,表示性不够(如物体的高度影响也很大)。基于以上问题,作者提出了GIoU进行关联,这是目标检测新常用的iou形式。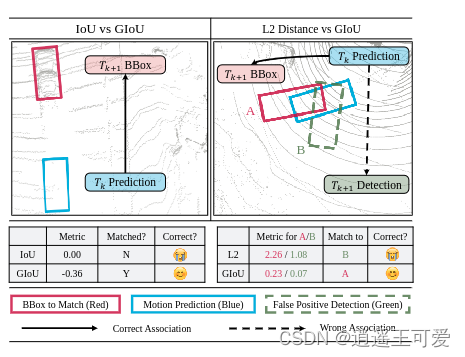
关联方式上,作者也对比了匈牙利算法和贪婪算法。
3,轨迹管理模块
在MOT中有一个重要的评价指标ID-Switches,这个指标表示预测的ID与真实的ID不匹配的次数。作者将出现这个错误的原因分为了两种,分别是1、错误关联 2、提前结束。
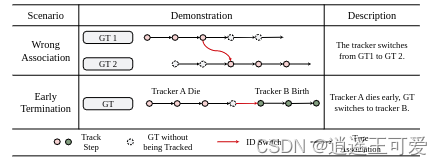
其中提前结束这种错误占了大多数。提前结束常是因为iou太低被过滤了。因而作者提出了两阶段关联,简单来说就是设置了两个高低阈值,分别是Th和Tl。首先进行对iou大于Th的Box做正常的匹配关联,在第二阶段,只要Box的置信度高于Tl就允许进行关联,但是由于这一段检测结果质量较差,所以检测结果不用于更新运动模型,而是使用运动预测结果代替检测结果输出。在使用两阶段关联后,ID-Switch指标得到了明显的提升。
【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D感知、多传感器融合、SLAM、高精地图、规划控制、AI模型部署落地等方向;
加入我们:自动驾驶之心技术交流群汇总!
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D感知、多传感器融合、目标跟踪)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!


















 579
579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









