






导读
生成式AI作为当前人工智能领域的前沿技术,已被广泛的应用于各类视觉合成任务。随着DALL-E2,Stable Diffusion和DreamFusion的发布,AI 作画和3D 合成实现了令人惊叹的视觉效果并且在全球范围内的爆炸式增长。这些生成式AI技术深刻地拓展了人们对于AI图像生成能力的认识,那么这些生成式AI方法是如何生成以假乱真的视觉效果?又是如何利用深度学习和神经网络技术来实现画作、3D生成以及其他创造性任务的呢?我们的综述论文将会给您提供这些问题的答案。
论文地址:https://arxiv.org/abs/2112.13592
代码地址:https://github.com/fnzhan/Generative-AI
项目地址:https://fnzhan.com/Generative-AI/
在第一章节,我们将为您描述多模态图像合成与编辑任务的意义和整体发展,以及本论文的贡献与总体结构。
在第二章节,根据引导图片合成与编辑的数据模态,该综述论文介绍了比较常用的视觉引导,文字引导,语音引导,还有近期DragGAN提出的控制点引导等,并且介绍了相应模态数据的处理方法。

在第三章节,根据图像合成与编辑的模型框架,该论文对目前的各种方法进行了分类,包括基于GAN的方法,扩散模型方法,自回归方法,和神经辐射场(NeRF)方法。
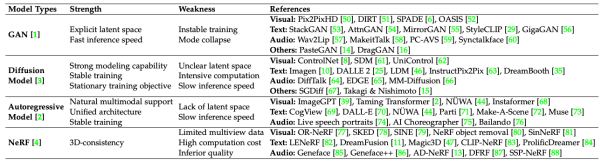
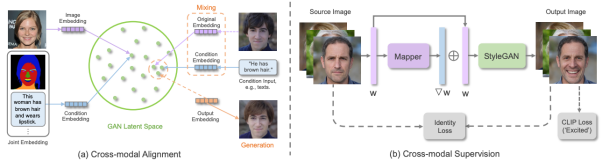
由于基于 GAN 的方法一般使用条件 GAN 和 GAN 反演,因此该论文进一步根据 控制条件的融合方式,模型的结构,损失函数设计,多模态对齐,和跨模态监督进行了详细描述。
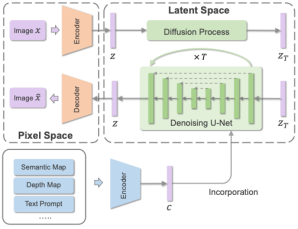
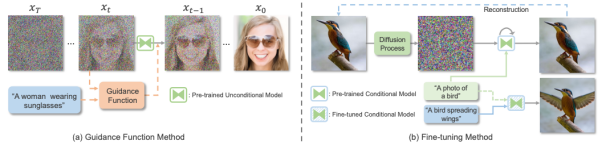
近期,火热的扩散模型也被广泛应用于多模态合成与编辑任务。例如效果惊人的DALLE-2和Imagen都是基于扩散模型实现的。相比于GAN,扩散式生成模型拥有一些良好的性质,比如静态的训练目标和易扩展性。该论文依据条件扩散模型和预训练扩散模型对现有方法进行了分类与详细分析。
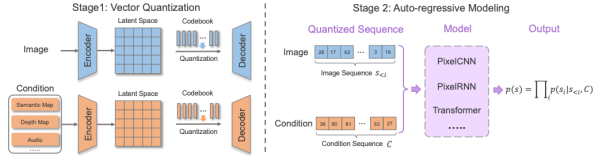
相比于基于GAN和扩散模型的方法,自回归模型方法能够更加自然的处理多模态数据,以及利用目前流行的Transformer模型。自回归方法一般先学习一个向量量化编码器将图片离散地表示为token序列,然后自回归式地建模token的分布。由于文本和语音等数据都能表示为token并作为自回归建模的条件,因此各种多模态图片合成与编辑任务都能统一到一个框架当中。
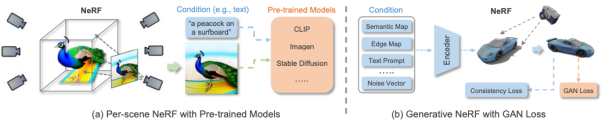
以上方法主要聚焦于2D图像的多模态合成与编辑。近期随着神经辐射场(NeRF)的迅速发展,3D感知的多模态合成与编辑也吸引了越来越多的关注。由于需要考虑多视角一致性,3D感知的多模态合成与编辑是更具挑战性的任务。本文针对单场景优化NeRF,生成式NeRF两种方法对现有工作进行了分类与总结。
随后,该综述对以上四种模型方法的进行了比较和讨论。总体而言,相比于GAN,目前最先进的模型更加偏爱自回归模型和扩散模型。而NeRF在多模态合成与编辑任务的应用为这个领域的研究打开了一扇新的窗户。
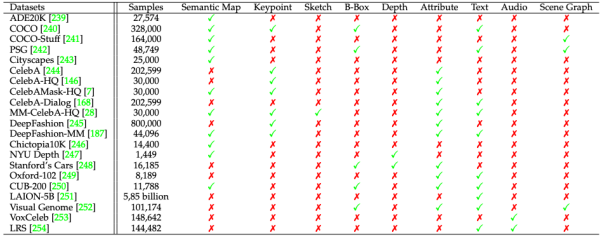
在第四章节,该综述汇集了多模态合成与编辑领域流行的数据集以及相应的模态标注,并且针对各模态典型任务(语义图像合成,文字到图像合成,语音引导图像编辑)对当前方法进行了定量的比较。同时也对多种模态同时控制生成的结果进行了可视化。

在第五章节,该综述对此领域目前的挑战和未来方向进行了探讨和分析,包括大规模的多模态数据集,准确可靠的评估指标,高效的网络架构,以及3D感知的发展方向。
在第六和第七章节,该综述分别阐述了此领域潜在的社会影响和总结了文章的内容与贡献。
对本综述感兴趣的小伙伴欢迎点击文末阅读原文。


















 1735
1735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











