





Title: DA-BEV : Depth Aware BEV Transformer for 3D Object Detection
Paper: https://arxiv.org/pdf/2302.13002v1.pdf
Code: coming soon!
导读
本文提出了一种隐式深度学习方法 DA-BEV,这是一种以环视图像作为输入,在 BEV 视角下利用 Transformer 进行 3D 目标检测的方法。该方法包括两个关键部分:深度感知空间交叉注意力 (Depth-Aware Spatial Cross-Attention, DA-SCA)模块和深度对比学习 (Depth-wise Contrastive Learning, DCL)。DA-SCA 模块负责将深度信息融合至 BEV 特征中,以至于能更好地捕捉目标的深度信息。而 DCL 则通过对正负 BEV 特征进行采样,进一步增强了 BEV 特征的深度感知能力。实验结果表明,DA-BEV 方法在 nuScenes 数据集上取得了 SOTA 检测性能。源码即将开源,敬请期待!
::: block-1
BEV感知

相当于给自动驾驶开启了“上帝视角”,能够让车辆无遮挡的“看清”道路上的实况信息,在BEV视角下统一完成感知和预测任务。
隐式深度学习
隐性深度学习的主要思想是在不需要显式定义输出的情况下学习目标函数。与传统的显式表示方法相比,隐性深度学习不需要人工标注的数据来指定输出,因此可以更好地适应各种复杂的任务和数据类型。
:::
创作背景
3D 目标检测是自动驾驶和机器人等许多应用中的基本任务。相较于基于激光雷达的方法,基于相机的方法具有成本低、感知范围长、可以识别纯视觉信号(如红绿灯和停止标志)等优势**。但是,相机方法面临的一个关键挑战是缺乏深度信息**。
前人研究表明,高质量的深度信息能够显著提高 3D 检测性能,因此当前许多研究工作致力于从相机图像中恢复深度信息,然而,深度估计仍是一个不适定问题。现有主流研究采用的两种方法,一种是显式深度学习方法:通过深度估计网络生成伪激光雷达信息,再用激光雷达检测器进行 3D 检测,另一种是隐式深度学习方法:直接预测三维框而不预测深度。
::: block-1
显示学习方法
结果提升方法 (Result-lifting)
将 3D 检测分解为 2D 检测和深度预测,并根据几何特性和约束条件预测对象。
特征提升方法 (Feature-lifting)
将图像特征提升到三维空间,通过预测深度图并将其提升到伪激活雷达来模拟激活雷达信号。
隐式学习方法
DETR3D、BEVFormer、PETR
使用目标查询 (object query) 来探测特征并为每个查询输出预测,而不预测深度。
:::
本文提出了一种新方法,通过在空间交叉注意力(SCA)模块中引入深度信息,同时提出了深度对比学习方法 (DCL),有效提高了 3D 检测性能。该方法在nuScenes数据集上得到了较好的性能,超过了现有的基准和最先进方法。
方法
动机
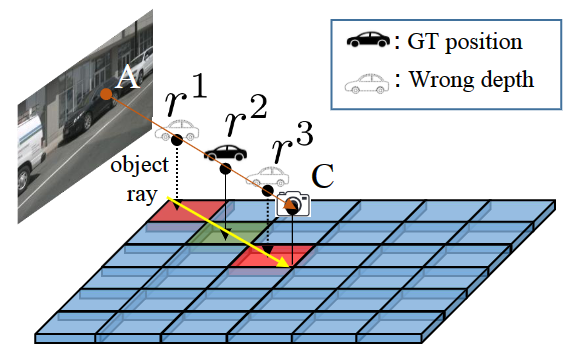
DA-BEV 的设计动机来自于以往 DETR-based 3D 检测器的常见问题。具体来说,以 BEVFormer 为例,其会将同一光线上的不同 3D 参考点被映射到相同的摄像机参考点上,导致检测头难以确定目标在深度方向上的确切位置,可能导致重复预测。
概述
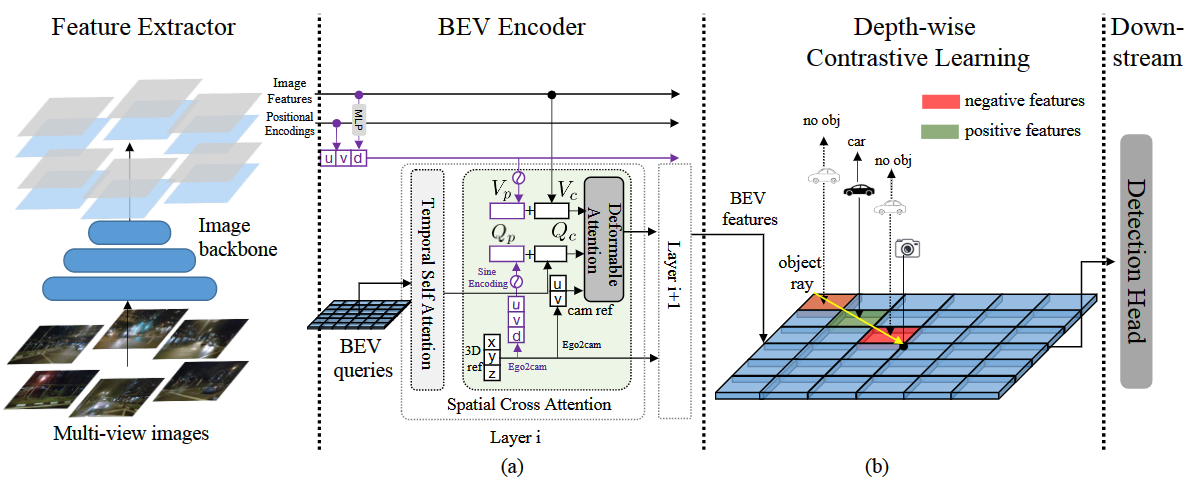
本文方法主要解决的是,之前 DETR-based 3D 检测器在处理图像特征时存在的深度信息缺失问题。本方法将深度信息编码到查询 (query) 和值 (value) 中,并提出了一个深度感知的空间交叉注意力模块和一个深度感知的对比学习方法,以增强深度信息的学习和比较。
DA-BEV 的训练流程分为四个部分,包括特征提取、BEV编码器、深度感知的空间交叉注意力模块和深度对比学习,最后通过 DETR 检测器对 BEV 特征进行预测,得出物体的 3D 边界框和类别信息。
深度感知的空间交叉注意力

在传统的 DETR-based 3D 检测器中,空间交叉注意力(SCA)没有考虑深度信息。本文提出了深度感知的空间交叉注意力(DA-SCA),通过在查询和值中引入深度编码来解决这一问题。与此前的方法相比,本文的 DA-SCA 采用的是不均匀的深度采样方式,可以更好地提取深度信息。实验结果表明,本文方法可以显著提高目标检测的性能。
在 DA-SCA中,通过将深度信息包含在位置编码中,将每个像素的深度与其位置信息一起编码。具体地,DA-SCA 采用了可变形注意力机制,使得查询点和值点可以自适应地调整形状,从而更好地适应不同的物体形状。此外,由于 DA-SCA 中的每个查询点都有自己的深度编码,因此可以更好地区分具有不同深度的像素,从而使深度信息更好地融入到空间交叉注意力中。
深度对比学习
深度对比学习 (DCL) 用于鼓励模型学习深度和其在 BEV 特征中的关系。
DCL 为每个对象分配一个对象射线,然后将其上的点映射到BEV特征上。对于每个对象,从中采样 NposN_{pos}Npos个 BEV 特征作为正样本,NnegN_{neg}Nneg个作为负样本。对于每个特征,使用其深度值和其在对象线上的 GT 深度值之差来确定其是正样本还是负样本。
通过将正样本和负样本输入到 box head 和 cls head,来进行DCL训练。对于正样本,使用对象的 GT 类别进行监督,而对于负样本则使用 “no object” 。此对比损失函数的目的是使预测深度趋近于 GT 深度,并鼓励模型为正样本输出高分类分数,为负样本输出低分类分数。
实验
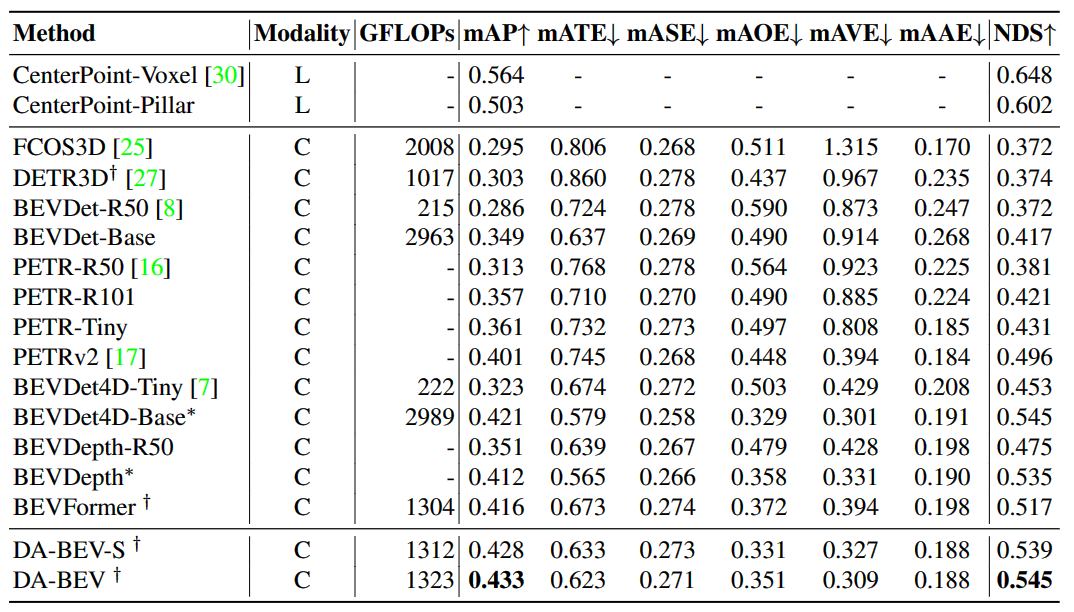
- DA-BEV-S 模型相比于 BEVFormer 模型,在NDS和mAP上分别提升了2.2和1.2个点。
- 虽然 BEVDet4D-Based 模型的 NDS 与 DA-BEV 相同,但 GFLOPS 要高得多,并且mAP 低于 DA-BEV。
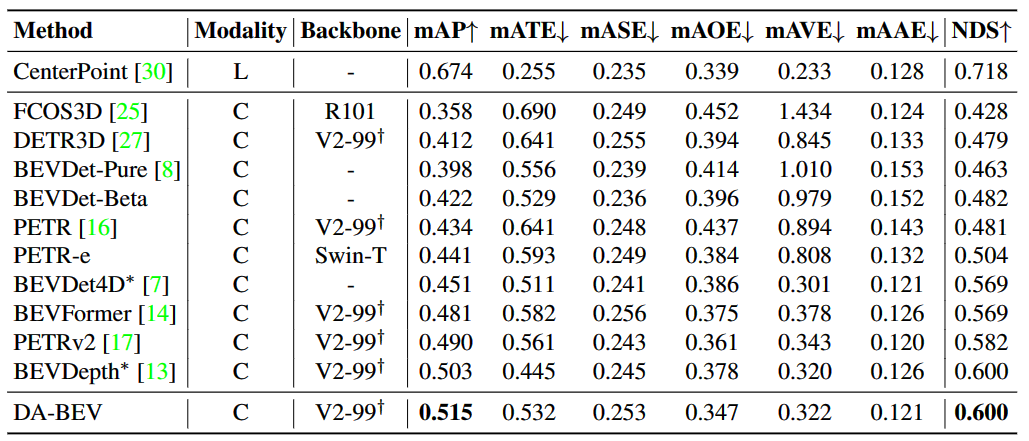
- DA-BEV 的 mAP 比之前的最优模型 BEVDepth 高1.2个点。
- 此外,之前的 baseline 模型 BEVFormer 与 DA-BEV: DA-BEV在 mAP 和 NDS 两个指标上分别比 BEVFormer 高出 3.4 和 3.1。这说明 DA-BEV 可以适应更强的预训练模型,并在各项指标上表现出色。
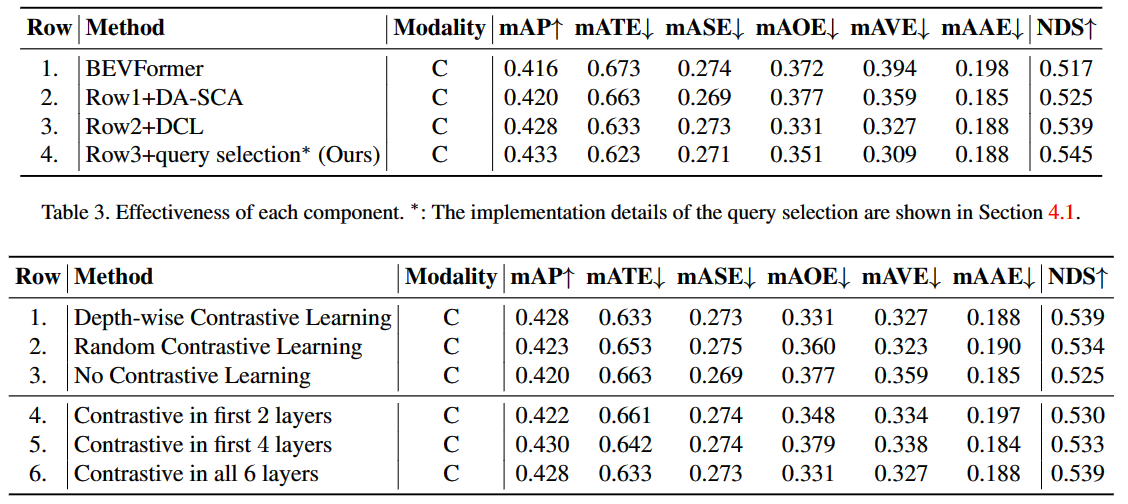
- 表.3 & 表.4 展示了模型的每个组成部分的有效性。
- 通过逐步增加不同的组件,模型性能都获得了进一步的提升。

- 在图4(b)中,沿深度轴的重复预测被减少了。这个可视化证实了我们的模型可以解决在动机小节中提到的歧义问题。
- 但是,当两个不同对象的对象光线重叠时,DA-BEV的预测也存在问题。可能存在两个潜在原因导致这个问题。首先,后面的对象被前面的对象遮挡。其次,在我们的 DCL 中,这样深度轴上的两个对象可能会成为彼此的负面例子,导致预测遗漏。
总结
本文针对之前 DETR-based 的 3D 检测器中忽略了空间交叉注意力中的深度信息,并在检测物体时产生了严重的模糊问题进行了研究。为了解决这个问题,本文提出了深度感知的空间交叉注意力(DA-SCA) 来编码深度信息,并提出了深度对比学习 (DCL) 来帮助模型以对比的方式学习深度。实验结果表明,DA-BEV 在不使用额外技巧的情况下取得了显著的改进,并达到了 SOTA 表现。未来,作者计划进一步将这种方法应用到更多检测器中,并研究隐式深度学习与显式深度学习的差异,并尝试将它们结合起来。
写在最后
如果您也对人工智能和计算机视觉全栈领域感兴趣,强烈推荐您关注有料、有趣、有爱的公众号『CVHub』,每日为大家带来精品原创、多领域、有深度的前沿科技论文解读及工业成熟解决方案!
同时欢迎添加小编微信: cv_huber,备注优快云,加入官方学术|技术|招聘交流群,一起探讨更多有趣的话题!



















 2313
2313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











