




 深度强化学习面临样本数据有效性低的问题,本文介绍EpisodeDeepRL和MetaRL两种解决方案。EpisodeDeepRL利用经验池加速新状态评估,MetaRL通过外部循环神经网络如LSTM,学习相似任务的统计特征,加速内部RL的收敛。
深度强化学习面临样本数据有效性低的问题,本文介绍EpisodeDeepRL和MetaRL两种解决方案。EpisodeDeepRL利用经验池加速新状态评估,MetaRL通过外部循环神经网络如LSTM,学习相似任务的统计特征,加速内部RL的收敛。
Reinforcement Learning, Fast and Slow
摘要:
深度强化学习已经取得很大成就,但是最大的缺陷在于样本数据的有效性低。主要有两种方法来解决这个问题:
- Episode Deep RL
- Meta RL
- 深度强化学习样本数据的有效性低的原因
- 梯度下降。需要对参数进行迭代更新直到收敛。学习率不能太大否则无法收敛,学习率太小则收敛速度慢。
- 弱偏置假设。机器学习模型都是要设定一个偏置假设即设定一个模型的假设空间(即假设模型的具体形式,参数未知),然后根据数据训练在这个空间中找出最符合样本数据的那个假设的具体模型(即学习出具体的参数)。如果偏置假设越强(即假设空间越小)则所需的样本数据就比较少,学习的比较快,否则就慢。深度强化学习采用深度神经网络形式复杂,参数众多,要使模型参数收敛并且不过拟合就需要更多地样本数据,当然训练的时间就比较长。
二、Episode Deep RL
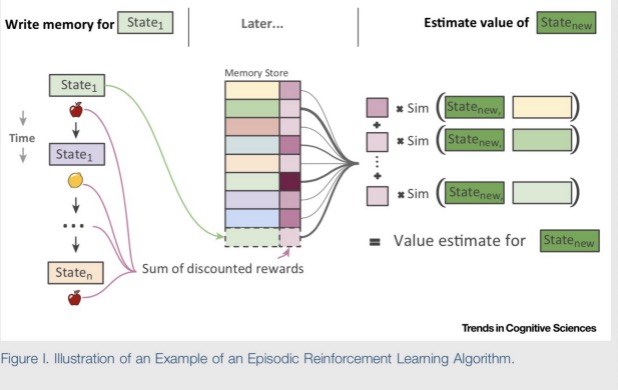
(1)在经验池保存好经历过的状态跟该状态所对应的收益。
(2)一个新的状态,通过特征提取(该特征提取是通过RL里的状态-收益估计网络来计算提取的)然后在经验池中比较计算新的状态与经验状态时间的特征差异,根据差异计算新的状态的收益。
问题:Episode RL是直接根据经验来得出在新状态下应该采取的策略,或者估计出新状态下的收益,没有对RL的参数进行更新?如果没有更新参数如何学习呢?
三、 Meta RL,通过学会学习加快深度强化学习的收敛
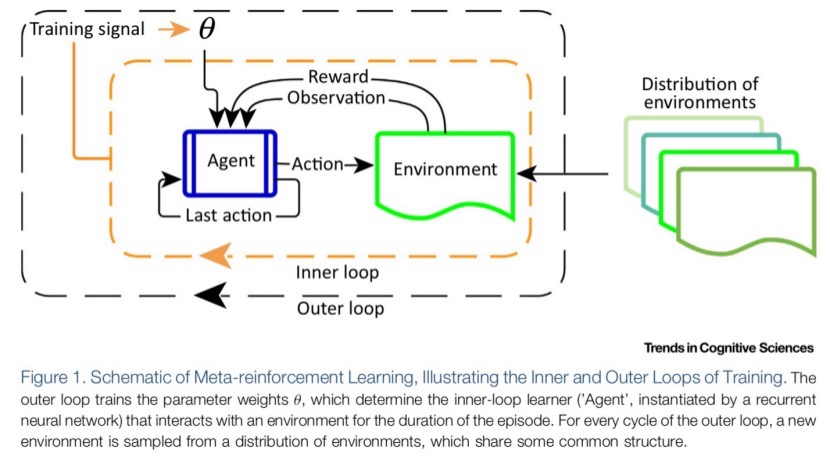
外部的循环(递归)神经网络在学习一系列相关或者类似的强化学习任务过程中是缓慢训练的,其参数的迭代更新收敛是缓慢的,因此这个网络可以学习到这一系列相关或者类似的强化学习任务的独立而相同分布的统计特征。这个网络的参数用来激励内部的RL快速学习每一个新的类似任务,从而加快内部RL的收敛。外部的循环神经网络其实是用经验数据进行训练的。
典型例子是LSTM。
应用例子:
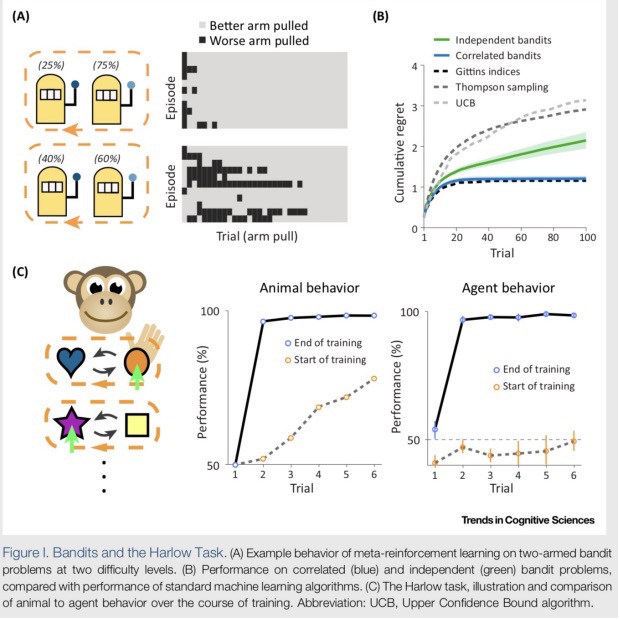
在两臂遥感游戏中,每一个臂都有一定的几率获得奖励。设置一系列的游戏学习任务即在每个任务中摇臂的获奖几率不同,用一个循环神经网络来学习这一系列游戏任务。在训练过程中,这个循环神经网络的参数可以直接用来给内部的RL作为参数加快内部RL的收敛。
- Episode Meta-RL
将Episode RL与Meta RL相结合。提取状态的特征的时候用的是外部循环神经网络的隐藏层的输出。

















 1214
1214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









