







 本文介绍了使用IDA分析两个FlareOn挑战的解题过程,涉及字符串操作和Base64解码。作者首先详细分析了sub_401084函数,通过字符异或和位运算得到解密脚本。接着,分析了sub_511260函数,确认其为Base64编码过程,并找到了对应的码表。最终,作者给出了解密后的挑战答案。
本文介绍了使用IDA分析两个FlareOn挑战的解题过程,涉及字符串操作和Base64解码。作者首先详细分析了sub_401084函数,通过字符异或和位运算得到解密脚本。接着,分析了sub_511260函数,确认其为Base64编码过程,并找到了对应的码表。最终,作者给出了解密后的挑战答案。
文章目录
[FlareOn2]very_success
拖入ida
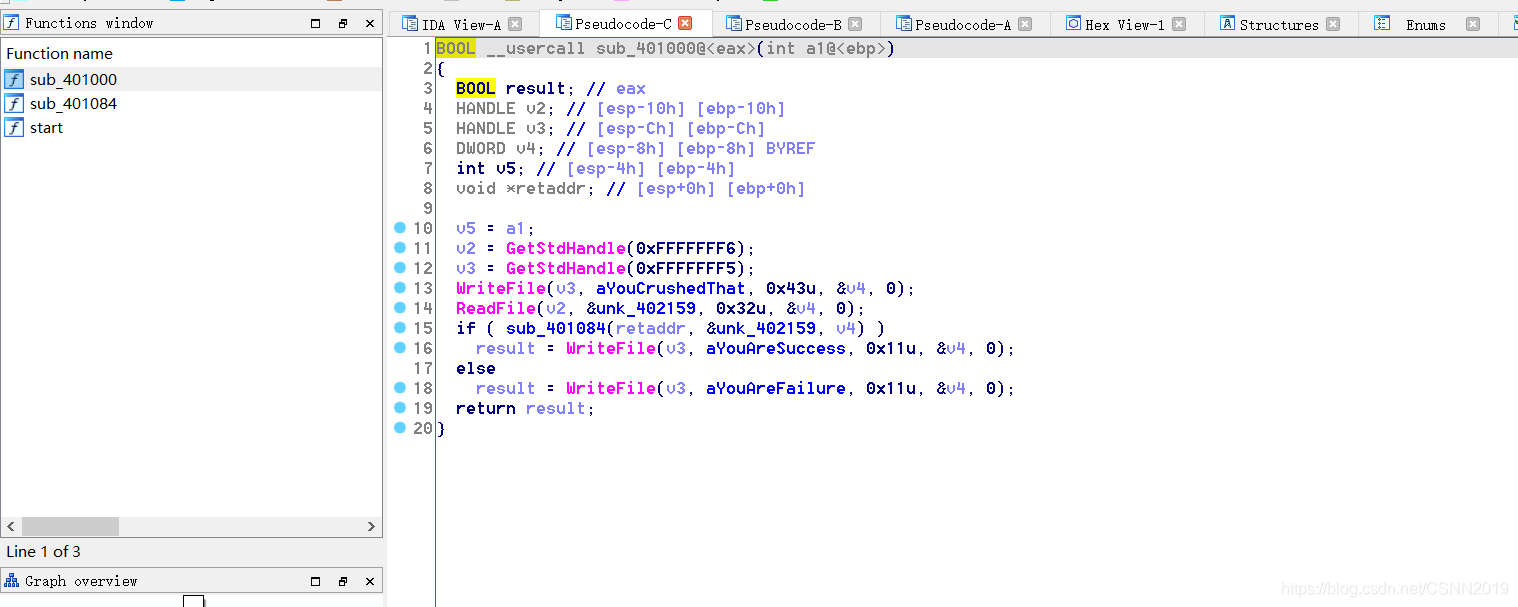
一开始我以为加壳了,就俩函数,后来仔细看了看,没有。。
这里和输入相关v4,v4的值是输入字符串的长度+2,v5是一个地址值。unk_402159是输入字符串的地址,作为参数传入了判断函数,retaddr是和输入字符串相对于判断的字符串。
分析sub_401084

v8参与运算,结果放入了v12,v11每次都是1
- v8和v15异或,看汇编就知道只运算了低8位,v15为0xc7
- v4初始为0,每次加v12,即每次加一个字节参与运算后的结果
这里a4判断了大于37,也就是说,输入字符必须是35个字符以上

这是判断字符串地址0x401108,动调取出字符串。
AA EC A4 BA AF AE AA
8A C0 A7 B0 BC 9A BA A5 A5 BA AF B8 9D B8 F9 AE
9D AB B4 BC B6 B3 90 9A A8
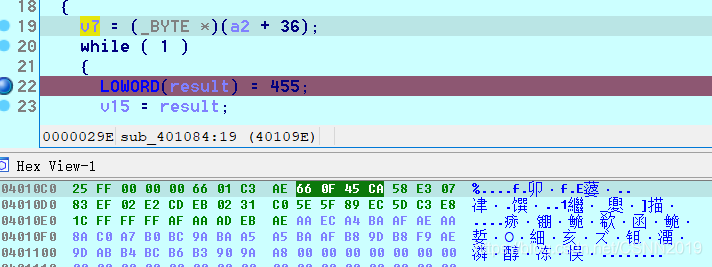
A8是字符串最后一个,它从最后一个开始判断,我一直以为A8是第一个,它是慢慢填充的,结果………………一直忽视了那个+36
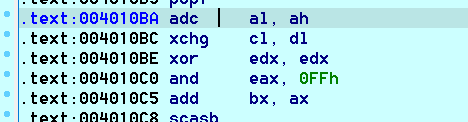
这里也就是对输入字符进行一些字符操作,然后进行和已知字符数组判断是否相同喽,分析完毕,开写脚本
脚本
a=[0xAA,0xEC,0xA4,0xBA,0xAF,0xAE,0xAA,0x8A,0xC0,0xA7,0xB0,0xBC,0x9A,0xBA,0xA5,0xA5,0xBA,0xAF,0xB8,0x9D,0xB8,0xF9,0xAE
,0x9D,0xAB,0xB4,0xBC,0xB6,0xB3,0x90,0x9A,0xA8]
a=a[::-1]
flag=""
v4=0
for i in range(len(a)):
tmp=(1<<(v4&0x3))
flag+=chr((a[i]-tmp-1)^0xc7)
v4+=a[i]
print(flag)
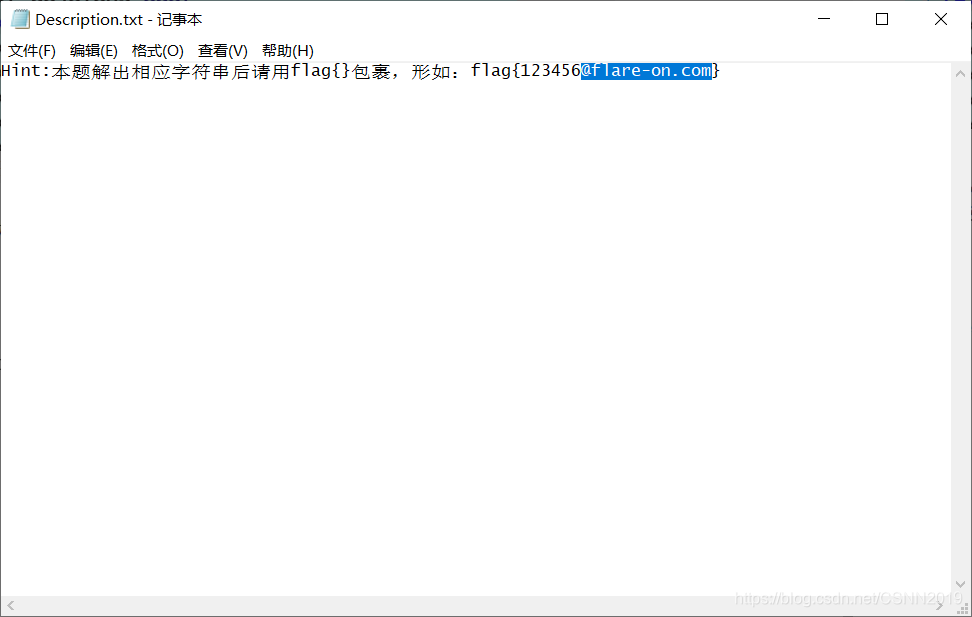
flag{a_Little_b1t_harder_plez@flare-on.com}
贴一下其它博主的学习一下:
def rol(value, count):
temp=((value>>(8-count))&0xFF)|((value<<count)& 0xFF)
return temp
v7=[0xAA, 0xEC, 0xA4, 0xBA, 0xAF, 0xAE, 0xAA, 0x8A, 0xC0, 0xA7,0xB0, 0xBC, 0x9A, 0xBA, 0xA5, 0xA5, 0xBA, 0xAF, 0xB8, 0x9D,0xB8, 0xF9, 0xAE, 0x9D, 0xAB, 0xB4, 0xBC, 0xB6, 0xB3, 0x90,0x9A, 0xA8]
flag=''
v4=0
for i in range(len(v7)):
flag+=chr((v7[len(v7)-i-1]-rol(1,v4&3)-1)^0xC7)
v4+=v7[len(v7)-i-1]
print('flag{'+flag+'n.com}')
sumv = 0
lenv = 37
rolv = 1
flag = 1
result = ''
values = [0xa8,0x9a,0x90,0xb3,0xb6,0xbc,0xb4,0xab,0x9d,0xae,0xf9,0xb8,0x9d,0xb8,0xaf,0xba,0xa5,0xa5,0xba,0x9a,0xbc,0xb0,0xa7,0xc0,0x8a,0xaa,0xae,0xaf,0xba,0xa4,0xec,0xaa,0xae,0xeb,0xad,0xaa,0xaf,]
for i in range(37):
rolv = (1 << (sumv & 3)) % 256
code = (455 ^ (values[i] - rolv - flag)% 256) %256
result = result + chr(code)
sumv = sumv + values[i]
print result
[FlareOn3]Challenge1
拖进ida
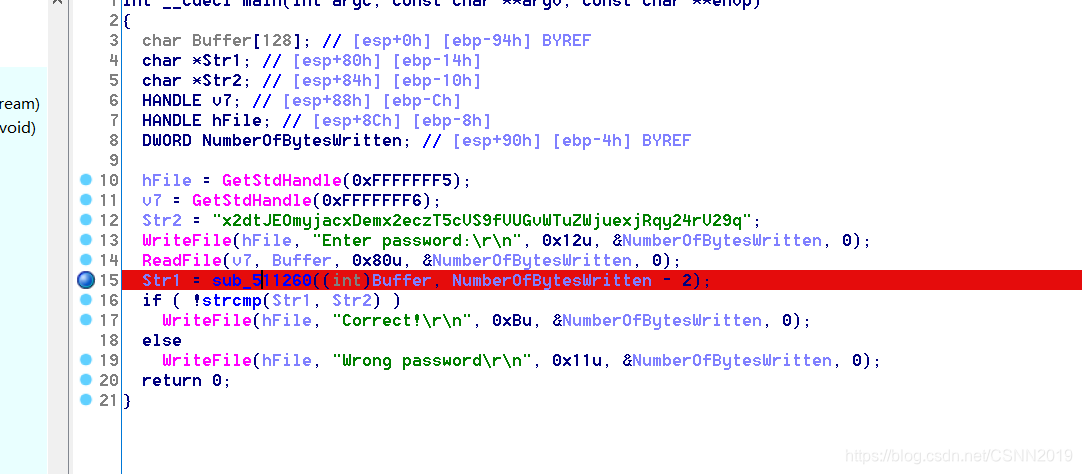
主要函数sub_511260((int)Buffer, NumberOfBytesWritten - 2)
sub_511260((int)Buffer, NumberOfBytesWritten - 2)
_BYTE *__cdecl sub_511260(int a1, unsigned int a2)
{
int v3; // [esp+Ch] [ebp-24h]
int v4; // [esp+10h] [ebp-20h]
int v5; // [esp+14h] [ebp-1Ch]
int i; // [esp+1Ch] [ebp-14h]
unsigned int v7; // [esp+20h] [ebp-10h]
_BYTE *v8; // [esp+24h] [ebp-Ch]
int v9; // [esp+28h] [ebp-8h]
int v10; // [esp+28h] [ebp-8h]
unsigned int v11; // [esp+2Ch] [ebp-4h]
v8 = malloc(4 * ((a2 + 2) / 3) + 1);
if ( !v8 )
return 0;
v11 = 0;
v9 = 0;
while ( v11 < a2 )
{
v5 = *(unsigned __int8 *)(v11 + a1);
if ( ++v11 >= a2 )
{
v4 = 0;
}
else
{
v4 = *(unsigned __int8 *)(v11 + a1);
++v11;
}
if ( v11 >= a2 )
{
v3 = 0;
}
else
{
v3 = *(unsigned __int8 *)(v11 + a1);
++v11;
}
v7 = v3 + (v5 << 16) + (v4 << 8);
v8[v9] = byte_523000[(v7 >> 18) & 0x3F];
v10 = v9 + 1;
v8[v10] = byte_523000[(v7 >> 12) & 0x3F];
v8[++v10] = byte_523000[(v7 >> 6) & 0x3F];
v8[++v10] = byte_523000[v3 & 0x3F];
v9 = v10 + 1;
}
for ( i = 0; i < byte_523040[a2 % 3]; ++i )
v8[4 * ((a2 + 2) / 3) - i - 1] = '=';
v8[4 * ((a2 + 2) / 3)] = 0;
return v8;
}
三个一组,进行变换,而且还涉及到能不能被3整除,一看 就是base64,先找码表
码表
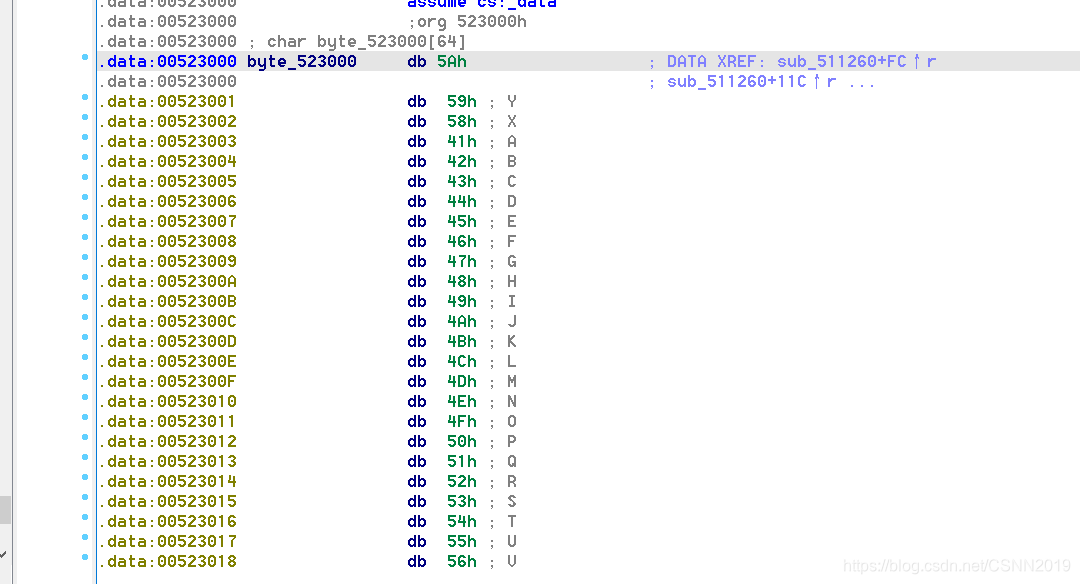
ZYXABCDEFGHIJKLMNOPQRSTUVWzyxabcdefghijklmnopqrstuvw0123456789+/
刚开始我还一直在算这里
v7 = v3 + (v5 << 16) + (v4 << 8);
v8[v9] = byte_523000[(v7 >> 18) & 0x3F];
v10 = v9 + 1;
v8[v10] = byte_523000[(v7 >> 12) & 0x3F];
v8[++v10] = byte_523000[(v7 >> 6) & 0x3F];
v8[++v10] = byte_523000[v3 & 0x3F];
v9 = v10 + 1;
后来忽然看到码表。。不淡定了。。
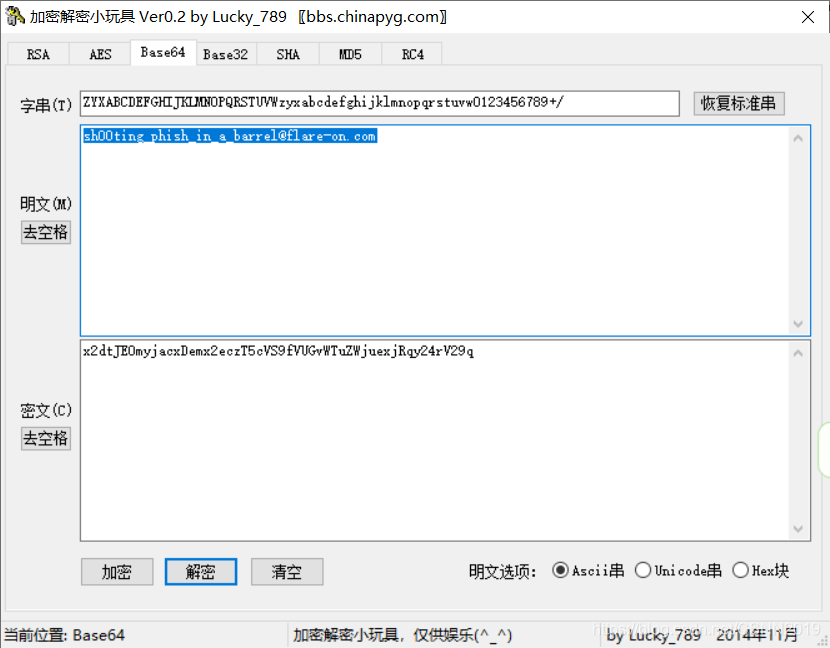
sh00ting_phish_in_a_barrel@flare-on.com



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











