




 本文介绍了一种名为DuoRec的序列推荐算法,它利用对比学习来缓解表征退化问题。通过噪声对比估计和校准性/均匀性概念,DuoRec结合无监督和有监督的增强策略,通过Dropout和正负样本对比,改善模型的表示学习。算法通过Transformer编码用户行为序列并预测未来交互,性能在WSDM'22会议上展示优于主流算法。
本文介绍了一种名为DuoRec的序列推荐算法,它利用对比学习来缓解表征退化问题。通过噪声对比估计和校准性/均匀性概念,DuoRec结合无监督和有监督的增强策略,通过Dropout和正负样本对比,改善模型的表示学习。算法通过Transformer编码用户行为序列并预测未来交互,性能在WSDM'22会议上展示优于主流算法。
#论文题目:DuoRec:Contrastive Learning for Representation Degeneration Problem in Sequential Recommendation(序列推荐:对比学习缓解表征退化问题)
#论文地址:https://arxiv.org/pdf/2110.05730.pdf
#论文发表网站:https://doi.org/10.1145/3488560.3498433
#论文来源:WSDM '22:第十五届 ACM 网络搜索和数据挖掘(顶会)
引言
1. 什么是序列推荐?
序列推荐(sequential recommendation)在推荐系统里是非常重要的任务,它通过对用户(user)行为序列,比如购买商品(item)的序列(sequence)来建模,学到user 兴趣的变化,从而能够对用户下一个行为进行预测。 序列推荐的模型,随着整个CS research(计算机科学 搜索)领域的发展,也是一直在不断变化。从最开始的Markov chain,到后来的RNN,CNN模型,以及现在流行的transformer。每个时期的序列推荐模型,基本上也是对应着该时期用的比较多的NLP模型。
2. 对比学习
2.1 噪声对比估计(NCE)
对比学习是将正样本对拉近,将负样本对推开。具体来说,噪声对比估计 (NCE) 目标通常用于训练编码器(如下所示),其中x和x+是来自正样本分布ppos的样本对,x - 是从数据pdata中随机采样得到,τ\tauτ为温度系数。
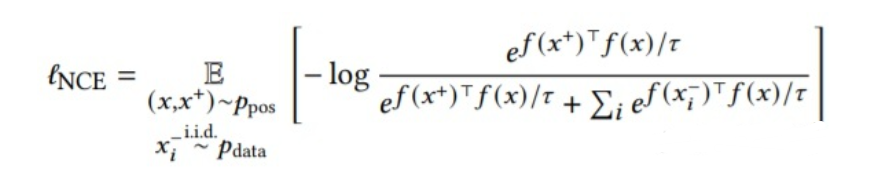
2.2 校准性(Alignment)和均匀性
NCE的损失是根据上式随机的进行增长或者减少。数学角度定义为在向量被归一化的假设下表示的校准性和均匀性,如下所示,其中ppos是正样本对的分布,pdata是独立样本的分布。最小化 lalign等价于使得正样本对更相近,最小化 luniform等价于使得这些样本均匀分布。
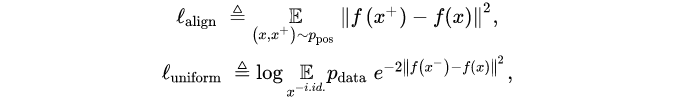
3. 为什么在表征学习模型训练过程中会出现“表征退化”问题?
首先,在进行梯度下降时候,目标项和非目标项都进行统一的训练,而不是具有指向性的训练,这就会导致原本表示准确的向量迭代时候产生偏差。其次,所训练的向量最后都在一个潜在的空间中表示,导致一些不相似的商品的embedding很集中。
4. 文章中的符号表示
商品集合表示为V,用户交互序列表示为s = [υ\upsilonυ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 825
825

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









