







点击卡片“大数据实战演练”,选择“设为星标”或“置顶”
回复“资料”可领取独家整理的大数据学习资料!
回复“Ambari知识库”可领取独家整理的Ambari学习资料!

大家好,我是 create17,见字如面。今天给大家推荐一个大数据平台产品,它的名字就是 EDP,由我们团队精心打造而成。能通过 Ambari 快速可视化部署新版 Apache Hadoop,跟随 Apache 各社区版本,适配了各种国产化系统,持续迭代更新,强烈推荐!
EDP 知识库:
https://www.yuque.com/create17/edp
"当你的监控系统成为被监控的对象时,你就知道是时候改变了。"
引言:一场迫在眉睫的变革
在大数据领域,Apache Ambari 作为一款成熟的集群管理工具已服务多年。然而,随着时间推移,它内置的监控系统—— Ambari Metrics System (AMS)——却逐渐成为了运维团队的"心头痛"。
在 EDP,我们管理着数百个 Hadoop 集群,每天面对的不仅是海量数据,还有来自 AMS 的各种"小情绪":时不时的服务宕机、莫名其妙的数据丢失、以及那令人抓狂的查询延迟,GC…
"这不是一个监控系统应有的表现," 我们的首席架构师在一次深夜故障排查后说道,"它应该是解决问题的工具,而不是制造问题的源头。"
这就是我们决定彻底重构 Ambari 监控系统的起点。在这个系列文章中,我将分享我们的经验——从认识问题,到设计方案,再到最终实现。今天,让我们先来了解 AMS 的前世今生,以及它为何需要一场彻底的革新。
什么是Ambari Metrics System?从设计初衷说起
Ambari Metrics System (简称AMS) 诞生于大数据技术的早期阶段,是 Apache Ambari 提供的一个专为 Hadoop 集群设计的监控系统。它的核心目标是帮助用户实时了解集群的运行状况,及时发现并解决潜在问题。
从架构上看,AMS 由四个主要层次组成:
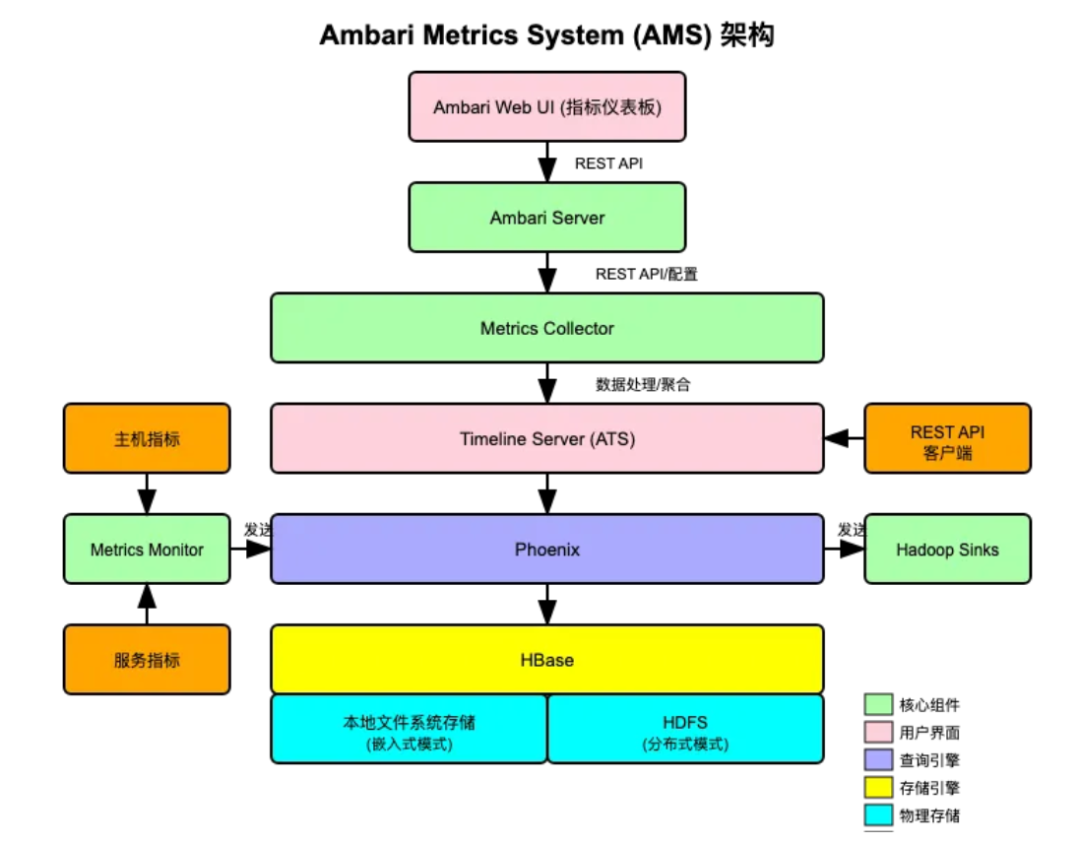
- 数据采集层
通过 Metrics Monitor 和 各种Hadoop Sinks 收集主机和服务指标
- Metrics Monitor:部署在集群的每个节点上,负责收集主机级别的指标(如 CPU 使用率、内存使用情况、磁盘 I/O 等)
- Hadoop Sinks:集成在各个 Hadoop 服务内部的插件,负责收集服务特定的指标数据
由 Metrics Collector 和 Timeline Server 处理时间序列数据
- Metrics Collector:AMS 的核心组件,接收来自 Metrics Monitor 和 Hadoop Sinks 的所有指标数据
- Timeline Server (ATS):处理时间序列数据,提供数据聚合和查询功能
使用 Phoenix 和 HBase 存储指标数据
- 嵌入式模式:使用本地文件系统存储数据(适用于小型集群)
- 分布式模式:使用 HDFS 存储数据(实际不能扩展,仅仅是数据丢在 HDFS 上,内置监控 HBase 的 RegionServer 和 Master 还是只有一个)
- Phoenix:SQL 查询引擎,将 SQL 查询转换为 HBase 扫描操作
- HBase:底层存储引擎,专为存储和快速检索时间序列数据而优化
存储选项:
:通过 Ambari Web UI 和 REST API 展示监控数据
- Ambari Web UI:提供图形化界面,展示各种指标的趋势图和仪表板
- REST API:允许外部应用程序访问指标数据,实现自定义监控和告警
这个设计在当时看来是合理的,但随着技术的发展和需求的变化,它的局限性逐渐显现…
当"古董"遇上现代需求:AMS的七宗"罪"
1. 单机版HBase:一个不该有的"单点"
想象一下,在一个拥有数百个节点的分布式集群中,监控系统的核心存储却是一个单机版的 HBase。这就像用一个小水桶去接一场暴雨——迟早会溢出。
"我们有一个客户,他们的集群有300多个节点,AMS的HBase几乎每周都会因为存储压力过大而崩溃一次。" — EDP资深运维工程师
单机 HBase 不仅存在存储容量瓶颈,还带来了单点故障风险 —— 一旦 HBase 服务出现问题,整个监控系统将无法正常工作。
2. 运维管理:一个被"遗忘"的组件
虽然 AMS 是 Ambari 的一部分,但讽刺的是,它的核心存储 HBase 却没有被纳入 Ambari 的管理界面。这意味着运维团队需要单独维护这个组件,而且没有统一的管理界面。
当出现问题时,排查过程就像在黑暗中摸索——日志分散,错误信息不直观,修改复杂的 HBase 配置,重启服务。升级过程更是充满风险,需要额外的步骤和注意事项,稍有不慎就可能导致数据丢失。
3. 性能瓶颈:越用越慢的"定时炸弹"
随着监控数据的积累,AMS 的查询性能会明显下降。对于需要查看长时间窗口历史数据的用户来说,这简直是一种折磨。
系统运行还需要消耗大量内存资源,在资源受限环境中表现不佳。数据模型的简单设计也限制了数据分析的灵活性,无法满足复杂的分析需求。
4. 自定义监控:一道难以逾越的"高墙"
在现代IT环境中,快速添加自定义监控指标是基本需求。然而,在 AMS 中,这却是一项复杂且耗时的任务。
"我们客户曾经花了一周时间,仅仅为了添加几个自定义JVM指标。这在Prometheus中可能只需要几分钟。" — EDP开发团队
缺乏便捷的自定义监控指标添加机制,使得扩展新的监控项目变得异常复杂。这严重限制了团队对特定服务和应用的监控能力。
5. 数据查询:被"束缚"的数据价值
AMS 的 API 设计较为刻板,难以实现复杂的条件组合查询和数据聚合。查询语言能力有限,不如 PromQL 灵活强大,无法支持丰富的函数和表达式。
数据导出选项也非常有限,难以将监控数据导出到其他分析工具进行深度分析。这使得监控数据的价值大打折扣,无法充分发挥其在问题诊断和性能优化中的作用。
6. 用户体验:停留在"上个时代"的界面
与现代监控系统相比,AMS 的界面设计显得过于基础,缺乏灵活的定制能力和直观的数据可视化。
仪表盘功能和视觉呈现相对简单,难以根据特定需求灵活调整监控视图。告警机制也比较基础,缺乏高级告警功能,如动态阈值、模式识别等。
7. 生态隔离:一个"孤岛"式的存在
AMS 缺乏与现代监控和可视化工具的集成能力,无法融入当前的监控生态系统。
缺乏丰富的插件和扩展组件,社区活跃度低,更新频率较低,新功能开发缓慢。在大规模环境下扩展能力有限,难以满足不断增长的监控需求。
变革的契机:为什么是现在?
面对这些问题,我们不禁要问:为什么要现在重构 AMS ?答案很简单:
- 技术债务积累到临界点
:随着集群规模的扩大,AMS 的问题变得越来越明显
- 现代监控技术的成熟
:Prometheus 等开源监控系统已经非常成熟
- 用户需求的变化
:客户需要更灵活、更强大的监控能力
- 运维成本的考量
:维护老旧系统的成本越来越高
下一步:现代化监控的新篇章
在接下来的文章中,我们将详细分享 EDP 团队如何彻底重构 Ambari 监控系统,打造一个真正现代化的监控解决方案。我们将重点探讨:
新一代监控系统的架构设计
- 我们如何设计全新的监控架构
- 核心组件的功能定位与交互方式
技术选型与决策过程
- 为什么我们选择了特定的技术栈
- 开源组件的评估与比较
- 自研与开源的平衡策略
痛点解决方案
- 如何解决存储瓶颈的问题
- 如何简化运维管理流程
- 如何提供灵活的自定义监控能力
- 如何增强数据查询与分析能力
- 如何解决监控指标的可读性问题
实际应用效果
- 性能提升的量化指标
- 用户反馈与案例分享
敬请期待下一篇:《架构重生:我们如何设计新一代 Ambari 监控系统》
作者简介:EDP技术团队核心成员,负责大数据平台架构设计与优化。拥有多年 Hadoop 生态系统开发经验,专注于提升大数据平台的可靠性、性能和用户体验。
Ending
基于Ambari的大数据平台解决方案:EDP,闪亮登场!✌️


一个人可以走得很快,但一群人才能走得更远。EDP 为我们提供了不更新的 HDP、价格高昂的 CDH 平替方案,支持各种国产操作系统,集成了 30+ 组件,形成了大数据平台解决方案。欢迎大家点击左下角阅读原文了解 EDP,与我们取得联系,希望 EDP 提供的服务可以帮助到你。
 最后,把我的座右铭送给大家:
执行是消除焦虑的有效办法,明确并拆解自己的目标,一直行动,剩下的交给时间。
共勉 💪。
最后,把我的座右铭送给大家:
执行是消除焦虑的有效办法,明确并拆解自己的目标,一直行动,剩下的交给时间。
共勉 💪。
戳“阅读原文”,查看EDP最新内容


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









