



一、安装python
可参考安装步骤:
python学习笔记 - python安装与环境变量配置_python环境变量-优快云博客
二、安装Gradio
在cmd执行以下命令。Gradio封装了功能丰富的前端用户界面,一会儿用来写demo。
命令行执行:pip install gradio
命令行更新:pip install --upgrade pip三、添加镜像加速
修改python默认的镜像加速,可增加pip命令下载速度。这里使用了aliyun的镜像。
Windows:
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
Linux:
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
四、运行字符串倒叙demo
启动后用浏览器访问,简单测试一下Gradio基础界面功能。
import gradio as gr
# 这是修改后的函数
def reverse_and_count(text):
reversed_text = text[::-1]
length = len(text)
return reversed_text, length
demo = gr.Interface(
fn=reverse_and_count,
inputs="text",
# flagging_mode="never",
outputs=["text", "number"], # 第一个输出是文本,第二个输出是一个数字
title="文本处理工具", # 设置页面标题
description="输入一段文字,查看其倒序形式及字符数。", # 添加简短说明
examples=[["你好,世界"], ["Hello World"]]
)
demo.launch()五、运行绘图demo
import gradio as gr
import numpy as np
import matplotlib.pyplot as plt
def plot_function(x_min, x_max, n_points):
x = np.linspace(x_min, x_max, n_points)
y = np.sin(x)
plt.figure()
plt.plot(x, y)
plt.title("Sine Wave")
plt.xlabel("x")
plt.ylabel("sin(x)")
return plt
demo = gr.Interface(
fn=plot_function,
inputs=[
gr.Number(label="X Min"),
gr.Number(label="X Max"),
gr.Number(label="Number of Points")
],
outputs=[gr.Plot()],
title="Function Plotter",
description="Plot a sine wave function based on the given parameters."
)
demo.launch()六、安装常用软件包和库
# 更新 pip 到最新版本
python -m pip install --upgrade pip
# 安装深度学习框架 (选择其中一个)
pip install torch torchvision torchaudio # PyTorch 和相关工具
# 或者
pip install tensorflow # TensorFlow
# 安装 Hugging Face Transformers 库
pip install transformers
# 安装 scikit-learn
pip install scikit-learn
# 安装 Pandas 和 NumPy
pip install pandas numpy
# 安装 Matplotlib 和 Seaborn
pip install matplotlib seaborn
# 安装超参数优化工具 (选择其中一个)
pip install optuna # Optuna
# 或者
pip install ray[tune] # Ray Tune
# 安装 MLflow
pip install mlflow
# 安装分布式计算框架 (选择其中一个)
pip install dask[complete] # Dask
# 或者
pip install pyspark # Apache Spark
# 安装 TensorBoard (通常与 TensorFlow 一起安装)
pip install tensorboard
# 安装 Jupyter Notebook 或 JupyterLab
pip install notebook jupyterlab
# 安装 Git (不是 Python 包,但非常重要)
# 这个需要从官网下载并安装: https://git-scm.com/
# 如果使用 GPU 加速,安装 CUDA 和 cuDNN (需要根据你的硬件和操作系统选择合适的版本)
# 这些通常需要从 NVIDIA 官网下载安装: https://developer.nvidia.com/cuda-toolkit-archive七、我目前使用的软件包和库简介
涵盖了构建和训练视频审核模型所需的主要工具和库。
这些库能够支持从数据处理、模型训练到超参数优化以及实验跟踪的完整流程。
以下是对每个部分的简要评估:
7.1. 更新 pip 到最新版本
python -m pip install --upgrade pip评估:确保你使用的是最新版本的 `pip`,这有助于避免安装过程中遇到的问题。
7.2. 深度学习框架
pip install torch torchvision torchaudio评估:PyTorch 是一个非常强大的深度学习框架,特别适合快速原型设计和研究。`torchvision` 和 `torchaudio` 提供了丰富的预训练模型和工具,非常适合计算机视觉和音频处理任务。
7.3. 自然语言处理(NLP)库
pip install transformers评估:Hugging Face 的 `transformers` 库提供了大量的预训练模型,可以用于文本分类、情感分析等任务。如果你的视频审核业务涉及字幕或评论的文本分析,这个库会非常有用。
7.4. 机器学习库
pip install scikit-learn评估:`scikit-learn` 是一个经典的机器学习库,提供了许多常用的算法和工具,适用于特征选择、模型评估等任务。它与 PyTorch 结合使用时,可以帮助进行数据预处理和评估。
7.5. 数据处理和分析库
pip install pandas numpy评估:`pandas` 和 `numpy` 是数据处理和科学计算的核心库,对于处理结构化数据和执行数值计算非常有帮助。
7.6. 可视化库
pip install matplotlib seaborn评估:`matplotlib` 和 `seaborn` 是优秀的可视化库,可以帮助你更好地理解和展示数据及模型结果。
7.7. 超参数优化工具
pip install optuna评估:Optuna 是一个灵活且易于使用的超参数优化工具,可以帮助你找到最优的模型配置。这对于提高模型性能非常重要。
7.8. 实验跟踪工具
pip install mlflow评估:MLflow 是一个流行的实验管理平台,可以帮助你跟踪实验、记录参数和指标、管理模型版本等。这对于团队协作和模型迭代非常有用。
7.9. 分布式计算框架
pip install dask[complete] 评估:Dask 是一个灵活的并行计算库,特别适合处理大规模数据集和并行化任务。它可以简化复杂的数据处理流程,并加速模型推理。
7.10. Jupyter Notebook 或 JupyterLab
pip install notebook jupyterlab评估:Jupyter Notebook 和 JupyterLab 提供了一个交互式的开发环境,非常适合探索性数据分析和模型开发。它们也方便分享代码和结果。
7.11.安装addict
pip install addict评估:modelscope 在导入过程中找不到名为 addict 的模块。这表明 addict 库未安装在你的环境中。addict 是一个 Python 库,它允许你使用点符号访问字典中的键,类似于 JavaScript 对象的属性访问方式。
7.12.安装datasets
pip install datasets评估:datasets 库,它是 Hugging Face 提供的一个非常流行的库,用于处理和加载各种机器学习数据集。
7.13.安装 opencv-python 库
pip install opencv-python评估:opencv-python 是一个强大而灵活的库,适用于广泛的计算机视觉应用,从简单的图像编辑到复杂的视频分析和机器学习项目。如果你刚开始接触计算机视觉领域,这是一个非常好的起点。
7.14.安装 ModelScope
pip install modelscope评估:ModelScope 是一个由阿里云开发的模型即服务平台(Model as a Service, MaaS),旨在简化和加速机器学习模型的使用、共享和部署。它提供了一个集中的平台,让用户可以轻松访问、训练、评估和部署各种预训练模型。
vsCode执行py脚本,检查是否安装成功:
import modelscope
print(f"ModelScope version: {modelscope.__version__}")返回版本即为成功:ModelScope version: 1.22.3
PS:若执行的Model缺少某些库,可根据控制台提示内容,使用pip命令进行补充下载。
八、文字生成图片AI模型demo
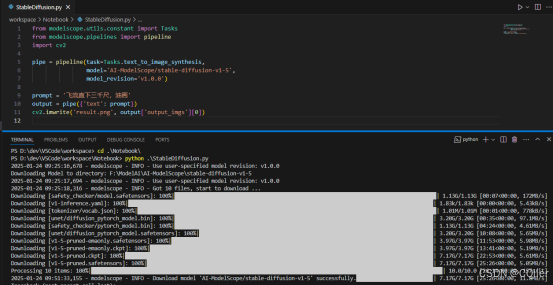
执行python命令启动,会使用modelScope自动下载模型,下载完成后会加载本地模型,调用本地CPU或GPU算力计算。
AI-ModelScope/stable-diffusion-xl-base-1.0生成图片:
from modelscope.utils.constant import Tasks
from modelscope.pipelines import pipeline
from PIL import Image
import numpy as np
# 创建pipeline,使用新的模型
pipe = pipeline(task=Tasks.text_to_image_synthesis,
model='AI-ModelScope/stable-diffusion-xl-base-1.0',
use_safetensors=True,
model_revision='v1.0.0')
# 设置文本提示
prompt = 'a dog'
# 执行pipeline并获得输出
output = pipe({'text': prompt})
# 将生成的图像保存到文件
output_image = output['output_imgs'][0]
# 如果output_image是numpy数组,则需要转换为PIL图像
if isinstance(output_image, np.ndarray):
output_image = Image.fromarray(output_image)
output_image.save('result.png')
# 显示图像
output_image.show()九、文字回复AI模型demo
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "qwen/Qwen2.5-7B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "介绍一下杭州"
messages = [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)以上为本地环境下载Notebook模型执行流程,针对需要下载模型部署到本地的业务。
可根据不同需求,在Notebook社区下载需要的模型进行替换。


















 659
659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









