









由缓存到分布式锁再到缓存一致性问题
写在前面
本文使用Redis做缓存中间件,并以分布式为分析背景,从本文中你可以了解到:
- 从本地缓存到引出分布式缓存
- 高并发下,缓存失效的三大问题:缓存,击穿,雪崩的分析和解决
- 使用分布式锁解决三大问题
- Redisson专业分布式锁框架简化开发
- Spring-cache由Spring整合缓存操作,一键式注解开发
各位看官可以按需所取
缓存的定义与使用
通常存在缓存中的数据要求实时性不高,常用于读多写少的数据,比如地图信息,电商中的三级分类信息等等
-
使用前提:本地缓存本质上是在堆空间中申请空间创建一个Map对象,所以如果缓存数据比较大,会占据服务本身的内存空间,并且如果是单体架构,可以使用本地缓存,
但如果是在分布式系统下,一个模块可能在多台服务器上,每一份服务器都要存一份缓存,大大浪费存储空间,最重要的是无法保证多台服务器上缓存数据的一致性问题 -
本地缓存的简单使用样例
// 根据项目需求设置泛型,或者再使用中使用强转
Map<String,Object> cache = new HashMap<>();
public Object getData(String key){
Object data = cache.get("data");
if(data!=null){
return data;
}
data = getFromDb();
return data;
}
- 所以由于本地缓存的局限性,我们尝试用缓存中间件Redis,这里关于Reids的基本使用以及Springboot整合不作为重点,接下来让我们步入正题:
高并发下,缓存失效的三大问题:缓存,击穿,雪崩的分析和解绝
面试标准八股文:我们先来用最通俗的语言讲解三大问题的定义和解决方案
缓存穿透
- 定义:缓存穿透是指:查询一个缓存中不存在的数据,由于缓存不命中,大量并发请求同时打到数据库上,数据库被击垮,无法正常提供服务,例如:有人利用这个漏洞,恶意攻击去查询不存在的数据
- 解决方案:通常我们将null空查询结果或者标志位比如0,1作为结果放入缓存中,并设置短暂的过期时间,就可防止缓存穿透的问题
缓存雪崩
- 定义:由于我们设置过期时间过于集中,导致缓存中大部分的数据在同一个时间点失效,导致大量请求同时打到数据库,服务崩溃
- 解决方案:在失效时间的基础上增加一个随机值,比如1-5分钟随机时间,这样过期时间不会大量重复,避免集体失效
缓存击穿
- 定义:某一个高频key失效时刚好有大量请求同时进来,所有请求落到数据库上导致服务崩溃
- 解决方案:加锁,大量并发只让一个线程去查数据库,其他线程等待,等线程查到数据后释放锁,其他线程去缓存中查
前两者问题好解决,一个设置标志位即可,一个是设置随机过期时间,对于第三种加锁方式我们来一步步解决
从本地锁到分布式锁解决缓存击穿
本地锁解决击穿
无论是我们熟悉的Sync或者JUC包下的各种锁,我们通常称为本地锁,只能锁住当前服务器的线程,现在我们假设是单体服务,使用Sync初步解决缓存击穿问题:只让一个线程去查数据库,其他线程阻塞等待,等线程查到数据后释放锁,其他线程去查缓存
// 这里假如我们想查询三级目录数据
public Map<String, List<Catelog2Vo>> getCatalog() {
Map<String, List<Catelog2Vo>> catalog = null;
synchronized (this){
ValueOperations<String, String> ops = redisTemplate.opsForValue();
String catalogJson = ops.get("catalogJson");
if(!StringUtils.isEmpty(catalogJson)){
catalog = JSON.parseObject(catalogJson, new TypeReference<Map<String, List<Catelog2Vo>>>() {
});
return catalog;
}
// 从数据读取的方法
catalog = getFromDb();
// 在缓冲中设置
ops.set("catalogJson", JSON.toJSONString(parentCid),1, TimeUnit.DAYS);
}
return catalog;
}
代码中的需要注意的问题:
- spring容器中所有的对象都是单例的,由于springboot容器中所有对象都是单例的,所以this指的impl是同一对象,所以使用this即可锁住
- 同时注意要将查数据库和放缓存加入到同步代码块中,保证原子操作,否则可能造成数据库已经查过一遍还没来得放入缓存,又一个线程拿到锁发现缓存没有再次去数据库查
分布式锁解决击穿
上述代码有一个明显的问题,如果是单体应用,this可以解决问题,如果是分布式下,一个服务可能有多台机器,每台机器都有自己的springboot应用,此时this就失效了,所以我们必须引入分布式锁,简单来说:就是所有的服务去一个公共空间占锁即可,可以是Mysql,redis,zookeeper等,这里我们使用redis实现分布式锁
再redis中,有一个我们熟知的api:setnx(), 命令在指定的 key 不存在时,为 key 设置指定的值。我们可以使用setnx(“lock”,uuid),(lock可以自定是key值,uuid是为当前获取锁的线程分配一个唯一id,后序会用到)设置一条记录,只有设置成功了,才能执行后序操作相当于获取了锁,当我们执行完了业务逻辑再删除
// 还是获取目录的业务代码,代码中一些关键性地方在后文中解释
public Map<String, List<Catelog2Vo>> getCatalog() {
// 1.占分布式锁
ValueOperations<String, String> ops = redisTemplate.opsForValue();
// setnx占锁
String uuid = UUID.randomUUID().toString();
Boolean lock = ops.setIfAbsent("lock", uuid,300,TimeUnit.SECONDS);
if(lock){
Map<String, List<Catelog2Vo>> cateFromDb = null;
try {
// 从数据库获取数据,也包括了将数据存到缓存的操作
cateFromDb = getCateFromDb();
}finally {
// lua脚本,删除key的操作,后文详细解释
String script = "if redis.call(\"get\",KEYS[1]) == ARGV[1]\n" +
"then\n" +
" return redis.call(\"del\",KEYS[1])\n" +
"else\n" +
" return 0\n" +
"end";
redisTemplate.execute(new DefaultRedisScript<Long>(script,Long.class),Arrays.asList("lock"),uuid);
}
return cateFromDb;
}else{
// 加锁失败,自旋重试
// 休眠100ms,防止自选频率过高
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
return getCatalogJsonFromDbWithRedis();
}
}
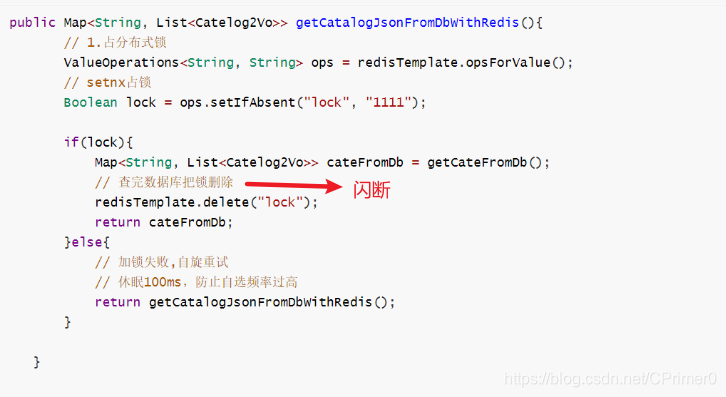
代码中的一些关键性解释
-
为什么设置过期时间:假如我们执行完
getCateFromDb()断电或者宕机了,就异常无法执行到删除逻辑,那么这个锁将永久留在redis服务器中,没有线程能够再去set成功,无法获取锁,图解
-
同时必须使用
setIfAbsent("lock", uuid,300,TimeUnit.SECONDS)保证设置时间和set操作时原子性,否则假如set操作后,还没来的及设置过期时间就闪断,同样造成死锁

-
UUID什么作用?假如我们的业务执行时间过长,导致业务代码还没执行完,锁就过期被删除了会造成:1.当前线程还没执行完,自己的锁就被删除了2.当锁删除后,其他线程会抢占到锁,这时原本的线程执行了删除锁的操作,导致把别人的锁删掉了,
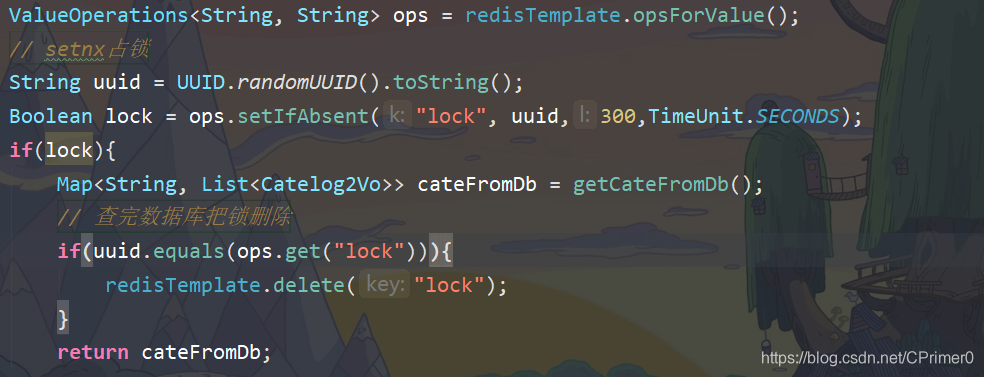
所以我们为每个线程分配一个uuid,却道加锁和删锁的是同一个线程,保证不会误删 -
lua脚本:上述说到setnx操作和设置过期时间必须是原子操作,假设我们使用普通的delete方法,首先去get(“lock”)并且还要
equals进行比较
 此时会产生如下问题:
此时会产生如下问题:
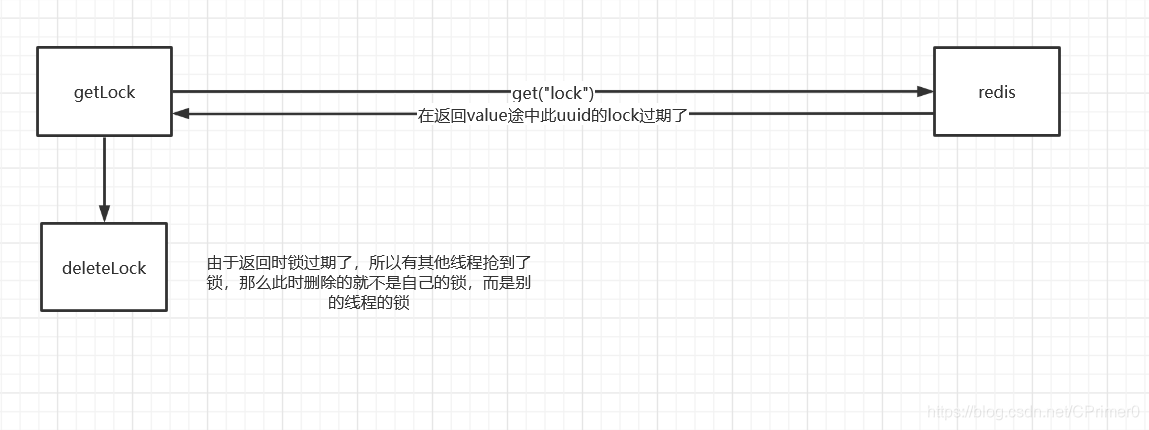 所以lua脚本就是保证了删除锁的原子性操作
所以lua脚本就是保证了删除锁的原子性操作 -
总的来说就是保证加锁和解锁的原子性,前者使用setnx,后者使用lua脚本
Redission专业的人做专业的事
通过前文的分析你会发现,分布式锁的实现过程十分繁琐,同时有许多意想不到的bug,这时我们可以引入Redission专业的分布式锁框架,帮助我们解决分布式锁问题
由于Redission大部分类实现了JUC接口,所以大多数API无缝连接了JUC的操作,如果熟悉JUC操作,Redission也会快速上手
基本的整合与使用
- 引入依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.12.0</version>
</dependency>
- 编写配置类
@Configuration
public class MyRedissonConfig {
/**
* 所有对Redisson地使用都是通过RedissonClient对象
* @return
* @throws IOException
* @throws KrbException
*/
@Bean(destroyMethod = "shutdown")
public RedissonClient redission() throws IOException {
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.28.137:6379");//redis服务地址
return Redisson.create(config);
}
}
- 我们使用Redission简化上述代码
public Map<String, List<Catelog2Vo>> getCatalogJsonFromDbWithRedisson() {
// 拿锁
RLock lock = redissonClient.getLock("Catalog-lock");
Map<String, List<Catelog2Vo>> cateFromDb = null;
try {
lock.lock(3,TimeUnit.SECONDS);
cateFromDb = getCateFromDb();
}catch (Exception e){
}finally {
// 确保能够释放锁
lock.unlock();
}
return cateFromDb;
}
代码中的一些关键性解释:
- Redission底层实现依托于Redis,当我们执行拿锁方法后,我们会发现Redis中存储了"Catalog-lock"的一条记录

- 关于过期时间的设置:当我们不去手动设置过期时间时,业务超长,超过锁的设置时间时,会自动给锁续30s的时间,不用担心业务时长超过设置时间(看门狗机制),只要被加锁的业务执行完毕,即使不手动unlock解锁,锁默认会在30s后过期
- 如果我们执行lock方法时,指定过期时间,redisson无法帮助我们自动延长时间,但在业务开发中,我们仍然推荐使用指定时间的lock方式,省去续期操作带来的性能损耗
缓存一致性问题
一旦我们引入了缓存就要考虑缓存一致性问题,即数据库和缓存的数据一致性问题,通常我们使用以下模式解决一致性问题
双写模式(写数据库同时更新缓存)
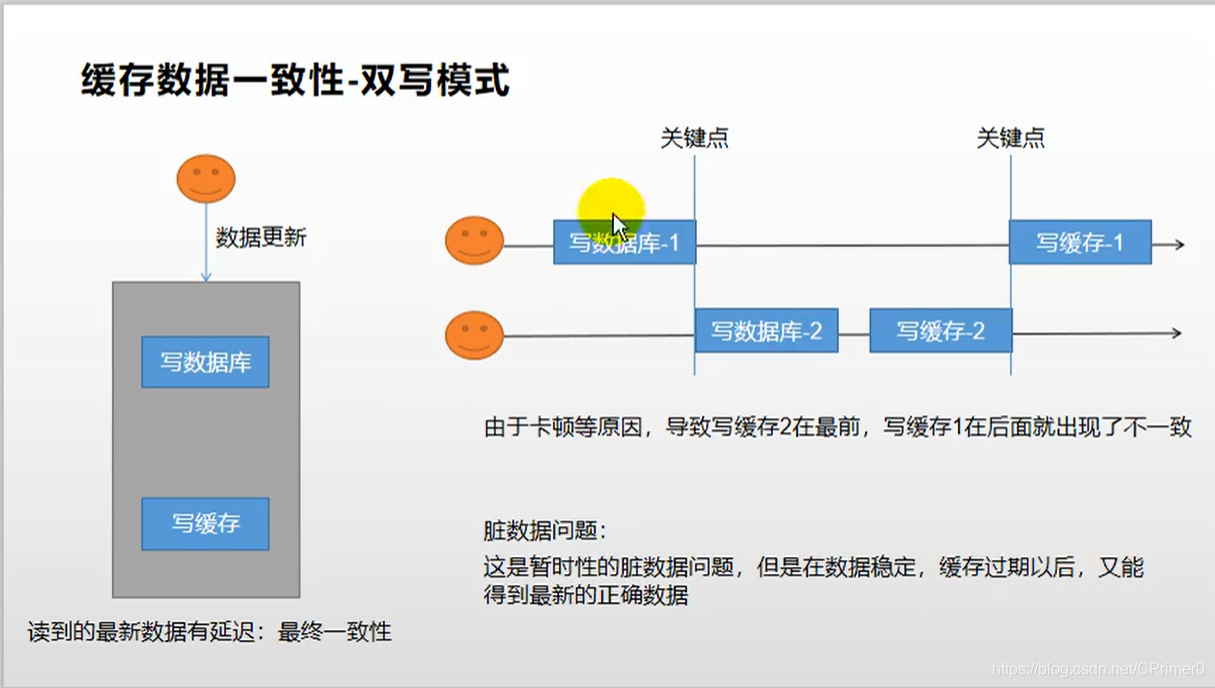
如何解决双写模式的bug:
- 加锁,保证写数据和写缓存为原子操作
- 如果能够容忍一定的一致性误差时间,可以不用操作,等到缓存数据过期时,重新从数据库读取新数据即可,比如目录啊,实时性要求不高
失效模式(写数据库,并删除缓存,等下次读取更新缓存)
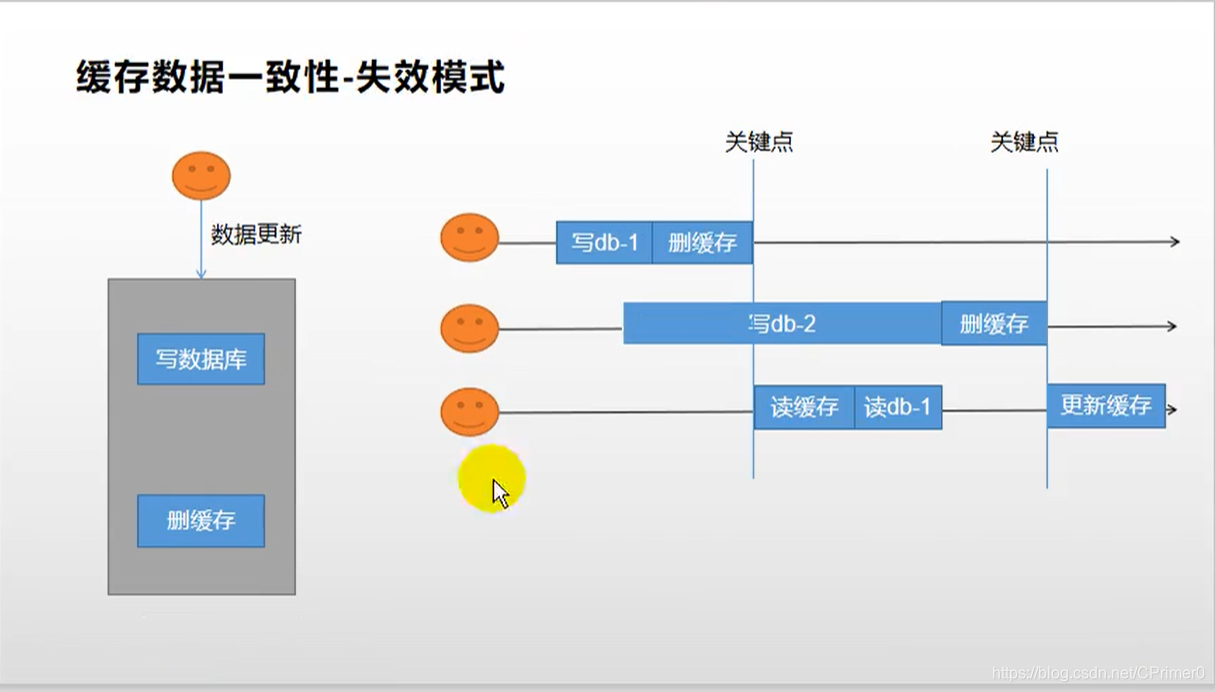 问题在于
问题在于
A:写数据db1,删缓存
B:在A删缓存之前开始写数据db2(卡顿,还没写完)
C:读缓存(db1),B写完数据并且删了缓存,C再更新缓存
此时读到的数据还是db1;
如何解决?
通常使用分布式读写锁实现,写操作加写锁,读操作加读锁,写写的时候排队,读读的时候无所谓
总结
- 我们能放入缓存的数据不应该是实时性的,一致性要求超高的,所以缓存的时候加上过期时间,保证每日按拿到当时最新数据即可
- 我们不应该过度设计,增加系统复杂性,实时数据就去数据库查
- 实在遇到实时性比较高,又要加入缓存:使用失效模式+分布式读写锁解决
SpringCache专业的人做专业的事
简单使用
1.引入依赖(由于SpringCache基于redis所以同时引入redis的依赖)
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
</dependency>
<!-- 为了解决letture底层操作Netty导致的内存溢出,我们排除lettuce,使用Jedis-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<exclusions>
<exclusion>
<groupId>io.letture</groupId>
<artifactId>letture-core</artifactId>
</exclusion>
</exclusions>
2.配置文件中设置缓存基于redis并在启动类上加上注解

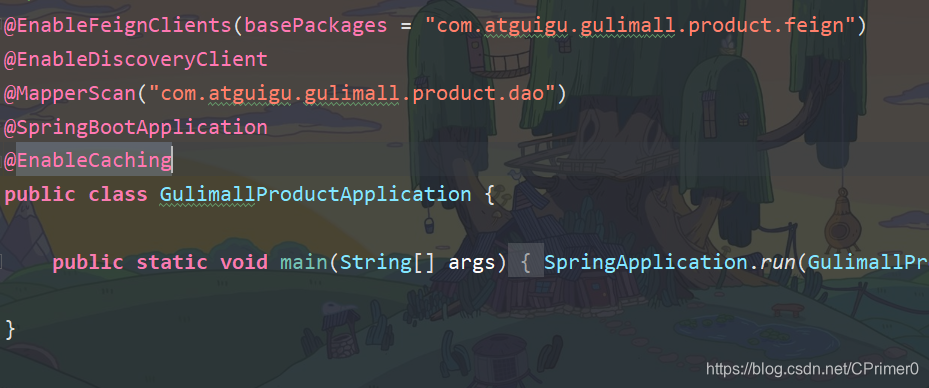
3.使用注解简化开发操作
- @Cacheable:触发将数据保存到缓存的操作,常用到查询操作上
使用@Cacheable注解,指名缓存的分区(value值,可以指名多个分区,也就是分个类,取个名),代表当前方法的结果需要缓存,如果缓存中有,方法不用调用,如果没有则会触发保存到缓存的操作
 当我们第一次调用方法时,Springcache会自动帮我们加入缓存,
当我们第一次调用方法时,Springcache会自动帮我们加入缓存,默认情况下如果缓存对象使用jdk的序列化方式,默认的ttl过期时间为-1

所以我们可以自定义行为
1.使用配置文件在配置文件中设置一些缓存属性,还可以设置前缀,等等

2.使用配置类一旦使用配置类,spring将不会帮我们读取properties配置文件,需要我们手动设置,可以在配置类中配置JSON的序列化方式
@Configuration
@EnableCaching
@EnableConfigurationProperties(CacheProperties.class)
public class MyCacheConfiguration {
@Bean
RedisCacheConfiguration redisCacheConfiguration(CacheProperties cacheProperties){
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig();
// 设置key,value的序列化机制
config = config.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()));
config = config.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()));
CacheProperties.Redis redisProperties = cacheProperties.getRedis();
// 在配置文件中手动设置读取配置文件
if (redisProperties.getTimeToLive() != null) {
config = config.entryTtl(redisProperties.getTimeToLive());
}
// 开启前缀
if (redisProperties.getKeyPrefix() != null) {
config = config.prefixKeysWith(redisProperties.getKeyPrefix());
}
if (!redisProperties.isUseKeyPrefix()) {
config = config.disableKeyPrefix();
}
return config;
}
}
- @CacheEvict:触发将数据从缓存删除的操作,此注解用在更新操作上
key为@Cacheable添加时指定的key
 使用失效模式,缓存中删除,下次查的使用从缓存中读
使用失效模式,缓存中删除,下次查的使用从缓存中读
- @CachePut:也为更新操作的注解,用于有返回值的方法
不同雨@CacheEvict,@CachePut使用双写模式,此次更新后,缓存中就有一份最新的数据,用于有返回值的方法
缺点与不足
上文分析到,缓存中的三大问题:击穿,雪崩,穿透,Springcache能不能帮我们解决呢?
-
缓存击穿有没有解决?默认是无锁的,可以使用sync=true加本地锁,起到一定效果,但无法实现分布式锁的效果

-
缓存雪崩有没有解决?加上过期时间即可
-
缓存穿透有没有解决?可以在配置文件中开启,缓存空值,防止击穿

Springcache总结
常规数据(读多写少,即时性,一致性要求不高的数据完全可以使用spring-cache),写模式只要有过期时间就足够了,特殊数据特殊设计,只能自己使用redisson设计
最后
我们要明白一点,我们不应该过度设计,增加系统复杂性,采用合适的技术帮助我们简化开发,本文带你从缓存到分布式锁到缓存一致性问题,以及常用的框架手段都涉及到,能够带你走进分布式下的一大问题,如果觉得不错,点个免费的赞,就是对博主最大的鼓励


















 1577
1577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









