参考链接
libswscale的sws_scale()
- FFmpeg的图像处理(缩放,YUV/RGB格式转换)类库libswsscale中的sws_scale()函数。
- libswscale是一个主要用于处理图片像素数据的类库。可以完成图片像素格式的转换,图片的拉伸等工作。
- 该类库常用的函数数量很少,一般情况下就3个:
- sws_getContext():初始化一个SwsContext。
- sws_scale():处理图像数据。
- sws_freeContext():释放一个SwsContext。
Libswscale处理数据流程
- Libswscale处理像素数据的流程可以概括为下图
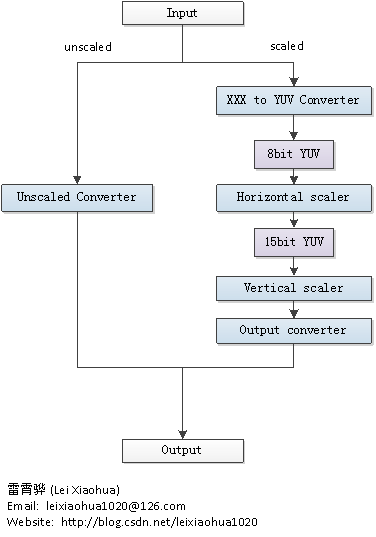
- 从图中可以看出,libswscale处理数据有两条最主要的方式:unscaled和scaled。
- unscaled用于处理不需要拉伸的像素数据(属于比较特殊的情况),scaled用于处理需要拉伸的像素数据。
- Unscaled只需要对图像像素格式进行转换;而Scaled则除了对像素格式进行转换之外,还需要对图像进行缩放。
- Scaled方式可以分成以下几个步骤:
- XXX to YUV Converter:首先将数据像素数据转换为8bitYUV格式;
- Horizontal scaler:水平拉伸图像,并且转换为15bitYUV;
- Vertical scaler:垂直拉伸图像;
- Output converter:转换为输出像素格式。
sws_scale()
- sws_scale()是用于转换像素的函数。它的声明位于libswscale\swscale.h,如下所示。
/**
* Scale the image slice in srcSlice and put the resulting scaled
* slice in the image in dst. A slice is a sequence of consecutive
* rows in an image.
*
* Slices have to be provided in sequential order, either in
* top-bottom or bottom-top order. If slices are provided in
* non-sequential order the behavior of the function is undefined.
*
* @param c the scaling context previously created with
* sws_getContext()
* @param srcSlice the array containing the pointers to the planes of
* the source slice
* @param srcStride the array containing the strides for each plane of
* the source image
* @param srcSliceY the position in the source image of the slice to
* process, that is the number (counted starting from
* zero) in the image of the first row of the slice
* @param srcSliceH the height of the source slice, that is the number
* of rows in the slice
* @param dst the array containing the pointers to the planes of
* the destination image
* @param dstStride the array containing the strides for each plane of
* the destination image
* @return the height of the output slice
*/
int sws_scale(struct SwsContext *c, const uint8_t *const srcSlice[],
const int srcStride[], int srcSliceY, int srcSliceH,
uint8_t *const dst[], const int dstStride[]);
- sws_scale()的定义位于libswscale\swscale.c,如下所示。
/**
* swscale wrapper, so we don't need to export the SwsContext.
* Assumes planar YUV to be in YUV order instead of YVU.
*/
int attribute_align_arg sws_scale(struct SwsContext *c,
const uint8_t * const srcSlice[],
const int srcStride[], int srcSliceY,
int srcSliceH, uint8_t *const dst[],
const int dstStride[])
{
if (c->nb_slice_ctx)
c = c->slice_ctx[0];
return scale_internal(c, srcSlice, srcStride, srcSliceY, srcSliceH,
dst, dstStride, 0, c->dstH);
}
- sws_scale内部调用了scale_internal,scale_internal函数封装了sws_scale的大多数代码
static int scale_internal(SwsContext *c,
const uint8_t * const srcSlice[], const int srcStride[],
int srcSliceY, int srcSliceH,
uint8_t *const dstSlice[], const int dstStride[],
int dstSliceY, int dstSliceH)
{
const int scale_dst = dstSliceY > 0 || dstSliceH < c->dstH;
const int frame_start = scale_dst || !c->sliceDir;
int i, ret;
const uint8_t *src2[4];
uint8_t *dst2[4];
int macro_height_src = isBayer(c->srcFormat) ? 2 : (1 << c->chrSrcVSubSample);
int macro_height_dst = isBayer(c->dstFormat) ? 2 : (1 << c->chrDstVSubSample);
// copy strides, so they can safely be modified
int srcStride2[4];
int dstStride2[4];
int srcSliceY_internal = srcSliceY;
if (!srcStride || !dstStride || !dstSlice || !srcSlice) {
av_log(c, AV_LOG_ERROR, "One of the input parameters to sws_scale() is NULL, please check the calling code\n");
return AVERROR(EINVAL);
}
if ((srcSliceY & (macro_height_src - 1)) ||
((srcSliceH & (macro_height_src - 1)) && srcSliceY + srcSliceH != c->srcH) ||
srcSliceY + srcSliceH > c->srcH) {
av_log(c, AV_LOG_ERROR, "Slice parameters %d, %d are invalid\n", srcSliceY, srcSliceH);
return AVERROR(EINVAL);
}
if ((dstSliceY & (macro_height_dst - 1)) ||
((dstSliceH & (macro_height_dst - 1)) && dstSliceY + dstSliceH != c->dstH) ||
dstSliceY + dstSliceH > c->dstH) {
av_log(c, AV_LOG_ERROR, "Slice parameters %d, %d are invalid\n", dstSliceY, dstSliceH);
return AVERROR(EINVAL);
}
if (!check_image_pointers(srcSlice, c->srcFormat, srcStride)) {
av_log(c, AV_LOG_ERROR, "bad src image pointers\n");
return AVERROR(EINVAL);
}
if (!check_image_pointers((const uint8_t* const*)dstSlice, c->dstFormat, dstStride)) {
av_log(c, AV_LOG_ERROR, "bad dst image pointers\n");
return AVERROR(EINVAL);
}
// do not mess up sliceDir if we have a "trailing" 0-size slice
if (srcSliceH == 0)
return 0;
if (c->gamma_flag && c->cascaded_context[0])
return scale_gamma(c, srcSlice, srcStride, srcSliceY, srcSliceH,
dstSlice, dstStride, dstSliceY, dstSliceH);
if (c->cascaded_context[0] && srcSliceY == 0 && srcSliceH == c->cascaded_context[0]->srcH)
return scale_cascaded(c, srcSlice, srcStride, srcSliceY, srcSliceH,
dstSlice, dstStride, dstSliceY, dstSliceH);
if (!srcSliceY && (c->flags & SWS_BITEXACT) && c->dither == SWS_DITHER_ED && c->dither_error[0])
for (i = 0; i < 4; i++)
memset(c->dither_error[i], 0, sizeof(c->dither_error[0][0]) * (c->dstW+2));
if (usePal(c->srcFormat))
update_palette(c, (const uint32_t *)srcSlice[1]);
memcpy(src2, srcSlice, sizeof(src2));
memcpy(dst2, dstSlice, sizeof(dst2));
memcpy(srcStride2, srcStride, sizeof(srcStride2));
memcpy(dstStride2, dstStride, sizeof(dstStride2));
if (frame_start && !scale_dst) {
if (srcSliceY != 0 && srcSliceY + srcSliceH != c->srcH) {
av_log(c, AV_LOG_ERROR, "Slices start in the middle!\n");
return AVERROR(EINVAL);
}
c->sliceDir = (srcSliceY == 0) ? 1 : -1;
} else if (scale_dst)
c->sliceDir = 1;
if (c->src0Alpha && !c->dst0Alpha && isALPHA(c->dstFormat)) {
uint8_t *base;
int x,y;
av_fast_malloc(&c->rgb0_scratch, &c->rgb0_scratch_allocated,
FFABS(srcStride[0]) * srcSliceH + 32);
if (!c->rgb0_scratch)
return AVERROR(ENOMEM);
base = srcStride[0] < 0 ? c->rgb0_scratch - srcStride[0] * (srcSliceH-1) :
c->rgb0_scratch;
for (y=0; y<srcSliceH; y++){
memcpy(base + srcStride[0]*y, src2[0] + srcStride[0]*y, 4*c->srcW);
for (x=c->src0Alpha-1; x<4*c->srcW; x+=4) {
base[ srcStride[0]*y + x] = 0xFF;
}
}
src2[0] = base;
}
if (c->srcXYZ && !(c->dstXYZ && c->srcW==c->dstW && c->srcH==c->dstH)) {
uint8_t *base;
av_fast_malloc(&c->xyz_scratch, &c->xyz_scratch_allocated,
FFABS(srcStride[0]) * srcSliceH + 32);
if (!c->xyz_scratch)
return AVERROR(ENOMEM);
base = srcStride[0] < 0 ? c->xyz_scratch - srcStride[0] * (srcSliceH-1) :
c->xyz_scratch;
xyz12Torgb48(c, (uint16_t*)base, (const uint16_t*)src2[0], srcStride[0]/2, srcSliceH);
src2[0] = base;
}
if (c->sliceDir != 1) {
// slices go from bottom to top => we flip the image internally
for (i=0; i<4; i++) {
srcStride2[i] *= -1;
dstStride2[i] *= -1;
}
src2[0] += (srcSliceH - 1) * srcStride[0];
if (!usePal(c->srcFormat))
src2[1] += ((srcSliceH >> c->chrSrcVSubSample) - 1) * srcStride[1];
src2[2] += ((srcSliceH >> c->chrSrcVSubSample) - 1) * srcStride[2];
src2[3] += (srcSliceH - 1) * srcStride[3];
dst2[0] += ( c->dstH - 1) * dstStride[0];
dst2[1] += ((c->dstH >> c->chrDstVSubSample) - 1) * dstStride[1];
dst2[2] += ((c->dstH >> c->chrDstVSubSample) - 1) * dstStride[2];
dst2[3] += ( c->dstH - 1) * dstStride[3];
srcSliceY_internal = c->srcH-srcSliceY-srcSliceH;
}
reset_ptr(src2, c->srcFormat);
reset_ptr((void*)dst2, c->dstFormat);
if (c->convert_unscaled) {
int offset = srcSliceY_internal;
int slice_h = srcSliceH;
// for dst slice scaling, offset the pointers to match the unscaled API
if (scale_dst) {
av_assert0(offset == 0);
for (i = 0; i < 4 && src2[i]; i++) {
if (!src2[i] || (i > 0 && usePal(c->srcFormat)))
break;
src2[i] += (dstSliceY >> ((i == 1 || i == 2) ? c->chrSrcVSubSample : 0)) * srcStride2[i];
}
for (i = 0; i < 4 && dst2[i]; i++) {
if (!dst2[i] || (i > 0 && usePal(c->dstFormat)))
break;
dst2[i] -= (dstSliceY >> ((i == 1 || i == 2) ? c->chrDstVSubSample : 0)) * dstStride2[i];
}
offset = dstSliceY;
slice_h = dstSliceH;
}
ret = c->convert_unscaled(c, src2, srcStride2, offset, slice_h,
dst2, dstStride2);
if (scale_dst)
dst2[0] += dstSliceY * dstStride2[0];
} else {
ret = swscale(c, src2, srcStride2, srcSliceY_internal, srcSliceH,
dst2, dstStride2, dstSliceY, dstSliceH);
}
if (c->dstXYZ && !(c->srcXYZ && c->srcW==c->dstW && c->srcH==c->dstH)) {
uint16_t *dst16;
if (scale_dst) {
dst16 = (uint16_t *)dst2[0];
} else {
int dstY = c->dstY ? c->dstY : srcSliceY + srcSliceH;
av_assert0(dstY >= ret);
av_assert0(ret >= 0);
av_assert0(c->dstH >= dstY);
dst16 = (uint16_t*)(dst2[0] + (dstY - ret) * dstStride2[0]);
}
/* replace on the same data */
rgb48Toxyz12(c, dst16, dst16, dstStride2[0]/2, ret);
}
/* reset slice direction at end of frame */
if ((srcSliceY_internal + srcSliceH == c->srcH) || scale_dst)
c->sliceDir = 0;
return ret;
}
- 从sws_scale()的定义可以看出,它封装了SwsContext中的swscale()(注意这个函数中间没有“_”)。函数最重要的一句代码就是“swscale()”。
- 除此之外,函数还做了一些增加“兼容性”的一些处理。
- 函数的主要步骤如下所示。
1.检查输入的图像参数的合理性。
- 这一步骤首先检查输入输出的参数是否为空,然后通过调用check_image_pointers()检查输入输出图像的内存是否正确分配。
- check_image_pointers()的定义如下所示。
static int check_image_pointers(const uint8_t * const data[4], enum AVPixelFormat pix_fmt,
const int linesizes[4])
{
const AVPixFmtDescriptor *desc = av_pix_fmt_desc_get(pix_fmt);
int i;
av_assert2(desc);
for (i = 0; i < 4; i++) {
int plane = desc->comp[i].plane;
if (!data[plane] || !linesizes[plane])
return 0;
}
return 1;
}
- 从check_image_pointers()的定义可以看出,在特定像素格式前提下,如果该像素格式应该包含像素的分量为空,就返回0,否则返回1。
2.如果输入像素数据中使用了“调色板”(palette),则进行一些相应的处理。
- 这一步通过函数usePal()来判定。
- usePal()的定义如下。
static av_always_inline int usePal(enum AVPixelFormat pix_fmt)
{
switch (pix_fmt) {
case AV_PIX_FMT_PAL8:
case AV_PIX_FMT_BGR4_BYTE:
case AV_PIX_FMT_BGR8:
case AV_PIX_FMT_GRAY8:
case AV_PIX_FMT_RGB4_BYTE:
case AV_PIX_FMT_RGB8:
return 1;
default:
return 0;
}
}
3.其它一些特殊格式的处理,比如说Alpha,XYZ等的处理(这方面没有研究过)。
4.如果输入的图像的扫描方式是从底部到顶部的(一般情况下是从顶部到底部),则将图像进行反转。
5.调用SwsContext中的swscale()。
SwsContext中的swscale()
- swscale这个变量的类型是SwsFunc,实际上就是一个函数指针。它是整个类库的核心。当我们从外部调用swscale()函数的时候,实际上就是调用了SwsContext中的这个名称为swscale的变量(注意外部函数接口和这个内部函数指针的名字是一样的,但不是一回事)。
- 可以看一下SwsFunc这个类型的定义:
typedef int (*SwsFunc)(struct SwsContext *context, const uint8_t *src[],
int srcStride[], int srcSliceY, int srcSliceH,
uint8_t *dst[], int dstStride[]);
- 可以看出SwsFunc的定义的参数类型和libswscale类库外部接口函数swscale()的参数类型一模一样。
- 在libswscale中,该指针的指向可以分成2种情况:
- 1.图像没有伸缩的时候,指向专有的像素转换函数
- 2.图像有伸缩的时候,指向swscale()函数。
- 在调用sws_getContext()初始化SwsContext的时候,会在其子函数sws_init_context()中对swscale指针进行赋值。如果图像没有进行拉伸,则会调用ff_get_unscaled_swscale()对其进行赋值;如果图像进行了拉伸,则会调用ff_getSwsFunc()对其进行赋值。
- 下面分别看一下这2种情况。
没有拉伸--专有的像素转换函数
- 如果图像没有进行拉伸,则会调用ff_get_unscaled_swscale()对SwsContext的swscale进行赋值。
- 上篇文章中记录了这个函数,在这里回顾一下。
ff_get_unscaled_swscale()
- ff_get_unscaled_swscale()的定义如下。
void ff_get_unscaled_swscale(SwsContext *c)
{
const enum AVPixelFormat srcFormat = c->srcFormat;
const enum AVPixelFormat dstFormat = c->dstFormat;
const int flags = c->flags;
const int dstH = c->dstH;
const int dstW = c->dstW;
int needsDither;
needsDither = isAnyRGB(dstFormat) &&
c->dstFormatBpp < 24 &&
(c->dstFormatBpp < c->srcFormatBpp || (!isAnyRGB(srcFormat)));
/* yv12_to_nv12 */
if ((srcFormat == AV_PIX_FMT_YUV420P || srcFormat == AV_PIX_FMT_YUVA420P) &&
(dstFormat == AV_PIX_FMT_NV12 || dstFormat == AV_PIX_FMT_NV21)) {
c->convert_unscaled = planarToNv12Wrapper;
}
/* yv24_to_nv24 */
if ((srcFormat == AV_PIX_FMT_YUV444P || srcFormat == AV_PIX_FMT_YUVA444P) &&
(dstFormat == AV_PIX_FMT_NV24 || dstFormat == AV_PIX_FMT_NV42)) {
c->convert_unscaled = planarToNv24Wrapper;
}
/* nv12_to_yv12 */
if (dstFormat == AV_PIX_FMT_YUV420P &&
(srcFormat == AV_PIX_FMT_NV12 || srcFormat == AV_PIX_FMT_NV21)) {
c->convert_unscaled = nv12ToPlanarWrapper;
}
/* nv24_to_yv24 */
if (dstFormat == AV_PIX_FMT_YUV444P &&
(srcFormat == AV_PIX_FMT_NV24 || srcFormat == AV_PIX_FMT_NV42)) {
c->convert_unscaled = nv24ToPlanarWrapper;
}
/* yuv2bgr */
if ((srcFormat == AV_PIX_FMT_YUV420P || srcFormat == AV_PIX_FMT_YUV422P ||
srcFormat == AV_PIX_FMT_YUVA420P) && isAnyRGB(dstFormat) &&
!(flags & SWS_ACCURATE_RND) && (c->dither == SWS_DITHER_BAYER || c->dither == SWS_DITHER_AUTO) && !(dstH & 1)) {
c->convert_unscaled = ff_yuv2rgb_get_func_ptr(c);
c->dst_slice_align = 2;
}
/* yuv420p1x_to_p01x */
if ((srcFormat == AV_PIX_FMT_YUV420P10 || srcFormat == AV_PIX_FMT_YUVA420P10 ||
srcFormat == AV_PIX_FMT_YUV420P12 ||
srcFormat == AV_PIX_FMT_YUV420P14 ||
srcFormat == AV_PIX_FMT_YUV420P16 || srcFormat == AV_PIX_FMT_YUVA420P16) &&
(dstFormat == AV_PIX_FMT_P010 || dstFormat == AV_PIX_FMT_P016)) {
c->convert_unscaled = planarToP01xWrapper;
}
/* yuv420p_to_p01xle */
if ((srcFormat == AV_PIX_FMT_YUV420P || srcFormat == AV_PIX_FMT_YUVA420P) &&
(dstFormat == AV_PIX_FMT_P010LE || dstFormat == AV_PIX_FMT_P016LE)) {
c->convert_unscaled = planar8ToP01xleWrapper;
}
if (srcFormat == AV_PIX_FMT_YUV410P && !(dstH & 3) &&
(dstFormat == AV_PIX_FMT_YUV420P || dstFormat == AV_PIX_FMT_YUVA420P) &&
!(flags & SWS_BITEXACT)) {
c->convert_unscaled = yvu9ToYv12Wrapper;
c->dst_slice_align = 4;
}
/* bgr24toYV12 */
if (srcFormat == AV_PIX_FMT_BGR24 &&
(dstFormat == AV_PIX_FMT_YUV420P || dstFormat == AV_PIX_FMT_YUVA420P) &&
!(flags & SWS_ACCURATE_RND) && !(dstW&1))
c->convert_unscaled = bgr24ToYv12Wrapper;
/* RGB/BGR -> RGB/BGR (no dither needed forms) */
if (isAnyRGB(srcFormat) && isAnyRGB(dstFormat) && findRgbConvFn(c)
&& (!needsDither || (c->flags&(SWS_FAST_BILINEAR|SWS_POINT))))
c->convert_unscaled = rgbToRgbWrapper;
/* RGB to planar RGB */
if ((srcFormat == AV_PIX_FMT_GBRP && dstFormat == AV_PIX_FMT_GBRAP) ||
(srcFormat == AV_PIX_FMT_GBRAP && dstFormat == AV_PIX_FMT_GBRP))
c->convert_unscaled = planarRgbToplanarRgbWrapper;
#define isByteRGB(f) ( \
f == AV_PIX_FMT_RGB32 || \
f == AV_PIX_FMT_RGB32_1 || \
f == AV_PIX_FMT_RGB24 || \
f == AV_PIX_FMT_BGR32 || \
f == AV_PIX_FMT_BGR32_1 || \
f == AV_PIX_FMT_BGR24)
if (srcFormat == AV_PIX_FMT_GBRP && isPlanar(srcFormat) && isByteRGB(dstFormat))
c->convert_unscaled = planarRgbToRgbWrapper;
if (srcFormat == AV_PIX_FMT_GBRAP && isByteRGB(dstFormat))
c->convert_unscaled = planarRgbaToRgbWrapper;
if ((srcFormat == AV_PIX_FMT_RGB48LE || srcFormat == AV_PIX_FMT_RGB48BE ||
srcFormat == AV_PIX_FMT_BGR48LE || srcFormat == AV_PIX_FMT_BGR48BE ||
srcFormat == AV_PIX_FMT_RGBA64LE || srcFormat == AV_PIX_FMT_RGBA64BE ||
srcFormat == AV_PIX_FMT_BGRA64LE || srcFormat == AV_PIX_FMT_BGRA64BE) &&
(dstFormat == AV_PIX_FMT_GBRP9LE || dstFormat == AV_PIX_FMT_GBRP9BE ||
dstFormat == AV_PIX_FMT_GBRP10LE || dstFormat == AV_PIX_FMT_GBRP10BE ||
dstFormat == AV_PIX_FMT_GBRP12LE || dstFormat == AV_PIX_FMT_GBRP12BE ||
dstFormat == AV_PIX_FMT_GBRP14LE || dstFormat == AV_PIX_FMT_GBRP14BE ||
dstFormat == AV_PIX_FMT_GBRP16LE || dstFormat == AV_PIX_FMT_GBRP16BE ||
dstFormat == AV_PIX_FMT_GBRAP10LE || dstFormat == AV_PIX_FMT_GBRAP10BE ||
dstFormat == AV_PIX_FMT_GBRAP12LE || dstFormat == AV_PIX_FMT_GBRAP12BE ||
dstFormat == AV_PIX_FMT_GBRAP16LE || dstFormat == AV_PIX_FMT_GBRAP16BE ))
c->convert_unscaled = Rgb16ToPlanarRgb16Wrapper;
if ((srcFormat == AV_PIX_FMT_GBRP9LE || srcFormat == AV_PIX_FMT_GBRP9BE ||
srcFormat == AV_PIX_FMT_GBRP16LE || srcFormat == AV_PIX_FMT_GBRP16BE ||
srcFormat == AV_PIX_FMT_GBRP10LE || srcFormat == AV_PIX_FMT_GBRP10BE ||
srcFormat == AV_PIX_FMT_GBRP12LE || srcFormat == AV_PIX_FMT_GBRP12BE ||
srcFormat == AV_PIX_FMT_GBRP14LE || srcFormat == AV_PIX_FMT_GBRP14BE ||
srcFormat == AV_PIX_FMT_GBRAP10LE || srcFormat == AV_PIX_FMT_GBRAP10BE ||
srcFormat == AV_PIX_FMT_GBRAP12LE || srcFormat == AV_PIX_FMT_GBRAP12BE ||
srcFormat == AV_PIX_FMT_GBRAP16LE || srcFormat == AV_PIX_FMT_GBRAP16BE) &&
(dstFormat == AV_PIX_FMT_RGB48LE || dstFormat == AV_PIX_FMT_RGB48BE ||
dstFormat == AV_PIX_FMT_BGR48LE || dstFormat == AV_PIX_FMT_BGR48BE ||
dstFormat == AV_PIX_FMT_RGBA64LE || dstFormat == AV_PIX_FMT_RGBA64BE ||
dstFormat == AV_PIX_FMT_BGRA64LE || dstFormat == AV_PIX_FMT_BGRA64BE))
c->convert_unscaled = planarRgb16ToRgb16Wrapper;
if (av_pix_fmt_desc_get(srcFormat)->comp[0].depth == 8 &&
isPackedRGB(srcFormat) && dstFormat == AV_PIX_FMT_GBRP)
c->convert_unscaled = rgbToPlanarRgbWrapper;
if (isBayer(srcFormat)) {
if (dstFormat == AV_PIX_FMT_RGB24)
c->convert_unscaled = bayer_to_rgb24_wrapper;
else if (dstFormat == AV_PIX_FMT_RGB48)
c->convert_unscaled = bayer_to_rgb48_wrapper;
else if (dstFormat == AV_PIX_FMT_YUV420P)
c->convert_unscaled = bayer_to_yv12_wrapper;
else if (!isBayer(dstFormat)) {
av_log(c, AV_LOG_ERROR, "unsupported bayer conversion\n");
av_assert0(0);
}
}
/* bswap 16 bits per pixel/component packed formats */
if (IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_BAYER_BGGR16) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_BAYER_RGGB16) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_BAYER_GBRG16) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_BAYER_GRBG16) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_BGR444) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_BGR48) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_BGR555) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_BGR565) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_BGRA64) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_GRAY9) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_GRAY10) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_GRAY12) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_GRAY14) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_GRAY16) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_YA16) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_AYUV64) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_GBRP9) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_GBRP10) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_GBRP12) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_GBRP14) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_GBRP16) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_GBRAP10) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_GBRAP12) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_GBRAP16) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_RGB444) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_RGB48) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_RGB555) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_RGB565) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_RGBA64) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_XYZ12) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_YUV420P9) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_YUV420P10) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_YUV420P12) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_YUV420P14) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_YUV420P16) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_YUV422P9) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_YUV422P10) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_YUV422P12) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_YUV422P14) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_YUV422P16) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_YUV440P10) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_YUV440P12) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_YUV444P9) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_YUV444P10) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_YUV444P12) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_YUV444P14) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_YUV444P16))
c->convert_unscaled = bswap_16bpc;
/* bswap 32 bits per pixel/component formats */
if (IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_GBRPF32) ||
IS_DIFFERENT_ENDIANESS(srcFormat, dstFormat, AV_PIX_FMT_GBRAPF32))
c->convert_unscaled = bswap_32bpc;
if (usePal(srcFormat) && isByteRGB(dstFormat))
c->convert_unscaled = palToRgbWrapper;
if (srcFormat == AV_PIX_FMT_YUV422P) {
if (dstFormat == AV_PIX_FMT_YUYV422)
c->convert_unscaled = yuv422pToYuy2Wrapper;
else if (dstFormat == AV_PIX_FMT_UYVY422)
c->convert_unscaled = yuv422pToUyvyWrapper;
}
/* uint Y to float Y */
if (srcFormat == AV_PIX_FMT_GRAY8 && dstFormat == AV_PIX_FMT_GRAYF32){
c->convert_unscaled = uint_y_to_float_y_wrapper;
}
/* float Y to uint Y */
if (srcFormat == AV_PIX_FMT_GRAYF32 && dstFormat == AV_PIX_FMT_GRAY8){
c->convert_unscaled = float_y_to_uint_y_wrapper;
}
/* LQ converters if -sws 0 or -sws 4*/
if (c->flags&(SWS_FAST_BILINEAR|SWS_POINT)) {
/* yv12_to_yuy2 */
if (srcFormat == AV_PIX_FMT_YUV420P || srcFormat == AV_PIX_FMT_YUVA420P) {
if (dstFormat == AV_PIX_FMT_YUYV422)
c->convert_unscaled = planarToYuy2Wrapper;
else if (dstFormat == AV_PIX_FMT_UYVY422)
c->convert_unscaled = planarToUyvyWrapper;
}
}
if (srcFormat == AV_PIX_FMT_YUYV422 &&
(dstFormat == AV_PIX_FMT_YUV420P || dstFormat == AV_PIX_FMT_YUVA420P))
c->convert_unscaled = yuyvToYuv420Wrapper;
if (srcFormat == AV_PIX_FMT_UYVY422 &&
(dstFormat == AV_PIX_FMT_YUV420P || dstFormat == AV_PIX_FMT_YUVA420P))
c->convert_unscaled = uyvyToYuv420Wrapper;
if (srcFormat == AV_PIX_FMT_YUYV422 && dstFormat == AV_PIX_FMT_YUV422P)
c->convert_unscaled = yuyvToYuv422Wrapper;
if (srcFormat == AV_PIX_FMT_UYVY422 && dstFormat == AV_PIX_FMT_YUV422P)
c->convert_unscaled = uyvyToYuv422Wrapper;
#define isPlanarGray(x) (isGray(x) && (x) != AV_PIX_FMT_YA8 && (x) != AV_PIX_FMT_YA16LE && (x) != AV_PIX_FMT_YA16BE)
/* simple copy */
if ( srcFormat == dstFormat ||
(srcFormat == AV_PIX_FMT_YUVA420P && dstFormat == AV_PIX_FMT_YUV420P) ||
(srcFormat == AV_PIX_FMT_YUV420P && dstFormat == AV_PIX_FMT_YUVA420P) ||
(isFloat(srcFormat) == isFloat(dstFormat)) && ((isPlanarYUV(srcFormat) && isPlanarGray(dstFormat)) ||
(isPlanarYUV(dstFormat) && isPlanarGray(srcFormat)) ||
(isPlanarGray(dstFormat) && isPlanarGray(srcFormat)) ||
(isPlanarYUV(srcFormat) && isPlanarYUV(dstFormat) &&
c->chrDstHSubSample == c->chrSrcHSubSample &&
c->chrDstVSubSample == c->chrSrcVSubSample &&
!isSemiPlanarYUV(srcFormat) && !isSemiPlanarYUV(dstFormat))))
{
if (isPacked(c->srcFormat))
c->convert_unscaled = packedCopyWrapper;
else /* Planar YUV or gray */
c->convert_unscaled = planarCopyWrapper;
}
if (ARCH_PPC)
ff_get_unscaled_swscale_ppc(c);
if (ARCH_ARM)
ff_get_unscaled_swscale_arm(c);
if (ARCH_AARCH64)
ff_get_unscaled_swscale_aarch64(c);
}
- 从代码中可以看出,它根据输入输出像素格式的不同,选择了不同的转换函数。
- 例如YUV420P转换NV12的时候,就会将planarToNv12Wrapper()赋值给SwsContext的swscale指针。
有拉伸--swscale()
void ff_sws_init_scale(SwsContext *c)
{
sws_init_swscale(c);
if (ARCH_PPC)
ff_sws_init_swscale_ppc(c);
if (ARCH_X86)
ff_sws_init_swscale_x86(c);
if (ARCH_AARCH64)
ff_sws_init_swscale_aarch64(c);
if (ARCH_ARM)
ff_sws_init_swscale_arm(c);
}
static av_cold void sws_init_swscale(SwsContext *c)
{
enum AVPixelFormat srcFormat = c->srcFormat;
ff_sws_init_output_funcs(c, &c->yuv2plane1, &c->yuv2planeX,
&c->yuv2nv12cX, &c->yuv2packed1,
&c->yuv2packed2, &c->yuv2packedX, &c->yuv2anyX);
ff_sws_init_input_funcs(c);
if (c->srcBpc == 8) {
if (c->dstBpc <= 14) {
c->hyScale = c->hcScale = hScale8To15_c;
if (c->flags & SWS_FAST_BILINEAR) {
c->hyscale_fast = ff_hyscale_fast_c;
c->hcscale_fast = ff_hcscale_fast_c;
}
} else {
c->hyScale = c->hcScale = hScale8To19_c;
}
} else {
c->hyScale = c->hcScale = c->dstBpc > 14 ? hScale16To19_c
: hScale16To15_c;
}
ff_sws_init_range_convert(c);
if (!(isGray(srcFormat) || isGray(c->dstFormat) ||
srcFormat == AV_PIX_FMT_MONOBLACK || srcFormat == AV_PIX_FMT_MONOWHITE))
c->needs_hcscale = 1;
}
- 注意,sws_init_context()对SwsContext的swscale进行赋值的语句是:
- c->swscale = ff_getSwsFunc(c);
- 即把ff_getSwsFunc()的返回值赋值给SwsContext的swscale指针;而ff_getSwsFunc()的返回值是一个静态函数,名称就叫做“swscale”。
- 下面我们看一下这个swscale()静态函数的定义。
static int swscale(SwsContext *c, const uint8_t *src[],
int srcStride[], int srcSliceY, int srcSliceH,
uint8_t *dst[], int dstStride[],
int dstSliceY, int dstSliceH)
{
const int scale_dst = dstSliceY > 0 || dstSliceH < c->dstH;
/* load a few things into local vars to make the code more readable?
* and faster */
const int dstW = c->dstW;
int dstH = c->dstH;
const enum AVPixelFormat dstFormat = c->dstFormat;
const int flags = c->flags;
int32_t *vLumFilterPos = c->vLumFilterPos;
int32_t *vChrFilterPos = c->vChrFilterPos;
const int vLumFilterSize = c->vLumFilterSize;
const int vChrFilterSize = c->vChrFilterSize;
yuv2planar1_fn yuv2plane1 = c->yuv2plane1;
yuv2planarX_fn yuv2planeX = c->yuv2planeX;
yuv2interleavedX_fn yuv2nv12cX = c->yuv2nv12cX;
yuv2packed1_fn yuv2packed1 = c->yuv2packed1;
yuv2packed2_fn yuv2packed2 = c->yuv2packed2;
yuv2packedX_fn yuv2packedX = c->yuv2packedX;
yuv2anyX_fn yuv2anyX = c->yuv2anyX;
const int chrSrcSliceY = srcSliceY >> c->chrSrcVSubSample;
const int chrSrcSliceH = AV_CEIL_RSHIFT(srcSliceH, c->chrSrcVSubSample);
int should_dither = isNBPS(c->srcFormat) ||
is16BPS(c->srcFormat);
int lastDstY;
/* vars which will change and which we need to store back in the context */
int dstY = c->dstY;
int lastInLumBuf = c->lastInLumBuf;
int lastInChrBuf = c->lastInChrBuf;
int lumStart = 0;
int lumEnd = c->descIndex[0];
int chrStart = lumEnd;
int chrEnd = c->descIndex[1];
int vStart = chrEnd;
int vEnd = c->numDesc;
SwsSlice *src_slice = &c->slice[lumStart];
SwsSlice *hout_slice = &c->slice[c->numSlice-2];
SwsSlice *vout_slice = &c->slice[c->numSlice-1];
SwsFilterDescriptor *desc = c->desc;
int needAlpha = c->needAlpha;
int hasLumHoles = 1;
int hasChrHoles = 1;
if (isPacked(c->srcFormat)) {
src[1] =
src[2] =
src[3] = src[0];
srcStride[1] =
srcStride[2] =
srcStride[3] = srcStride[0];
}
srcStride[1] *= 1 << c->vChrDrop;
srcStride[2] *= 1 << c->vChrDrop;
DEBUG_BUFFERS("swscale() %p[%d] %p[%d] %p[%d] %p[%d] -> %p[%d] %p[%d] %p[%d] %p[%d]\n",
src[0], srcStride[0], src[1], srcStride[1],
src[2], srcStride[2], src[3], srcStride[3],
dst[0], dstStride[0], dst[1], dstStride[1],
dst[2], dstStride[2], dst[3], dstStride[3]);
DEBUG_BUFFERS("srcSliceY: %d srcSliceH: %d dstY: %d dstH: %d\n",
srcSliceY, srcSliceH, dstY, dstH);
DEBUG_BUFFERS("vLumFilterSize: %d vChrFilterSize: %d\n",
vLumFilterSize, vChrFilterSize);
if (dstStride[0]&15 || dstStride[1]&15 ||
dstStride[2]&15 || dstStride[3]&15) {
SwsContext *const ctx = c->parent ? c->parent : c;
if (flags & SWS_PRINT_INFO &&
!atomic_exchange_explicit(&ctx->stride_unaligned_warned, 1, memory_order_relaxed)) {
av_log(c, AV_LOG_WARNING,
"Warning: dstStride is not aligned!\n"
" ->cannot do aligned memory accesses anymore\n");
}
}
#if ARCH_X86
if ( (uintptr_t)dst[0]&15 || (uintptr_t)dst[1]&15 || (uintptr_t)dst[2]&15
|| (uintptr_t)src[0]&15 || (uintptr_t)src[1]&15 || (uintptr_t)src[2]&15
|| dstStride[0]&15 || dstStride[1]&15 || dstStride[2]&15 || dstStride[3]&15
|| srcStride[0]&15 || srcStride[1]&15 || srcStride[2]&15 || srcStride[3]&15
) {
SwsContext *const ctx = c->parent ? c->parent : c;
int cpu_flags = av_get_cpu_flags();
if (flags & SWS_PRINT_INFO && HAVE_MMXEXT && (cpu_flags & AV_CPU_FLAG_SSE2) &&
!atomic_exchange_explicit(&ctx->stride_unaligned_warned,1, memory_order_relaxed)) {
av_log(c, AV_LOG_WARNING, "Warning: data is not aligned! This can lead to a speed loss\n");
}
}
#endif
if (scale_dst) {
dstY = dstSliceY;
dstH = dstY + dstSliceH;
lastInLumBuf = -1;
lastInChrBuf = -1;
} else if (srcSliceY == 0) {
/* Note the user might start scaling the picture in the middle so this
* will not get executed. This is not really intended but works
* currently, so people might do it. */
dstY = 0;
lastInLumBuf = -1;
lastInChrBuf = -1;
}
if (!should_dither) {
c->chrDither8 = c->lumDither8 = sws_pb_64;
}
lastDstY = dstY;
ff_init_vscale_pfn(c, yuv2plane1, yuv2planeX, yuv2nv12cX,
yuv2packed1, yuv2packed2, yuv2packedX, yuv2anyX, c->use_mmx_vfilter);
ff_init_slice_from_src(src_slice, (uint8_t**)src, srcStride, c->srcW,
srcSliceY, srcSliceH, chrSrcSliceY, chrSrcSliceH, 1);
ff_init_slice_from_src(vout_slice, (uint8_t**)dst, dstStride, c->dstW,
dstY, dstSliceH, dstY >> c->chrDstVSubSample,
AV_CEIL_RSHIFT(dstSliceH, c->chrDstVSubSample), scale_dst);
if (srcSliceY == 0) {
hout_slice->plane[0].sliceY = lastInLumBuf + 1;
hout_slice->plane[1].sliceY = lastInChrBuf + 1;
hout_slice->plane[2].sliceY = lastInChrBuf + 1;
hout_slice->plane[3].sliceY = lastInLumBuf + 1;
hout_slice->plane[0].sliceH =
hout_slice->plane[1].sliceH =
hout_slice->plane[2].sliceH =
hout_slice->plane[3].sliceH = 0;
hout_slice->width = dstW;
}
for (; dstY < dstH; dstY++) {
const int chrDstY = dstY >> c->chrDstVSubSample;
int use_mmx_vfilter= c->use_mmx_vfilter;
// First line needed as input
const int firstLumSrcY = FFMAX(1 - vLumFilterSize, vLumFilterPos[dstY]);
const int firstLumSrcY2 = FFMAX(1 - vLumFilterSize, vLumFilterPos[FFMIN(dstY | ((1 << c->chrDstVSubSample) - 1), c->dstH - 1)]);
// First line needed as input
const int firstChrSrcY = FFMAX(1 - vChrFilterSize, vChrFilterPos[chrDstY]);
// Last line needed as input
int lastLumSrcY = FFMIN(c->srcH, firstLumSrcY + vLumFilterSize) - 1;
int lastLumSrcY2 = FFMIN(c->srcH, firstLumSrcY2 + vLumFilterSize) - 1;
int lastChrSrcY = FFMIN(c->chrSrcH, firstChrSrcY + vChrFilterSize) - 1;
int enough_lines;
int i;
int posY, cPosY, firstPosY, lastPosY, firstCPosY, lastCPosY;
// handle holes (FAST_BILINEAR & weird filters)
if (firstLumSrcY > lastInLumBuf) {
hasLumHoles = lastInLumBuf != firstLumSrcY - 1;
if (hasLumHoles) {
hout_slice->plane[0].sliceY = firstLumSrcY;
hout_slice->plane[3].sliceY = firstLumSrcY;
hout_slice->plane[0].sliceH =
hout_slice->plane[3].sliceH = 0;
}
lastInLumBuf = firstLumSrcY - 1;
}
if (firstChrSrcY > lastInChrBuf) {
hasChrHoles = lastInChrBuf != firstChrSrcY - 1;
if (hasChrHoles) {
hout_slice->plane[1].sliceY = firstChrSrcY;
hout_slice->plane[2].sliceY = firstChrSrcY;
hout_slice->plane[1].sliceH =
hout_slice->plane[2].sliceH = 0;
}
lastInChrBuf = firstChrSrcY - 1;
}
DEBUG_BUFFERS("dstY: %d\n", dstY);
DEBUG_BUFFERS("\tfirstLumSrcY: %d lastLumSrcY: %d lastInLumBuf: %d\n",
firstLumSrcY, lastLumSrcY, lastInLumBuf);
DEBUG_BUFFERS("\tfirstChrSrcY: %d lastChrSrcY: %d lastInChrBuf: %d\n",
firstChrSrcY, lastChrSrcY, lastInChrBuf);
// Do we have enough lines in this slice to output the dstY line
enough_lines = lastLumSrcY2 < srcSliceY + srcSliceH &&
lastChrSrcY < AV_CEIL_RSHIFT(srcSliceY + srcSliceH, c->chrSrcVSubSample);
if (!enough_lines) {
lastLumSrcY = srcSliceY + srcSliceH - 1;
lastChrSrcY = chrSrcSliceY + chrSrcSliceH - 1;
DEBUG_BUFFERS("buffering slice: lastLumSrcY %d lastChrSrcY %d\n",
lastLumSrcY, lastChrSrcY);
}
av_assert0((lastLumSrcY - firstLumSrcY + 1) <= hout_slice->plane[0].available_lines);
av_assert0((lastChrSrcY - firstChrSrcY + 1) <= hout_slice->plane[1].available_lines);
posY = hout_slice->plane[0].sliceY + hout_slice->plane[0].sliceH;
if (posY <= lastLumSrcY && !hasLumHoles) {
firstPosY = FFMAX(firstLumSrcY, posY);
lastPosY = FFMIN(firstLumSrcY + hout_slice->plane[0].available_lines - 1, srcSliceY + srcSliceH - 1);
} else {
firstPosY = posY;
lastPosY = lastLumSrcY;
}
cPosY = hout_slice->plane[1].sliceY + hout_slice->plane[1].sliceH;
if (cPosY <= lastChrSrcY && !hasChrHoles) {
firstCPosY = FFMAX(firstChrSrcY, cPosY);
lastCPosY = FFMIN(firstChrSrcY + hout_slice->plane[1].available_lines - 1, AV_CEIL_RSHIFT(srcSliceY + srcSliceH, c->chrSrcVSubSample) - 1);
} else {
firstCPosY = cPosY;
lastCPosY = lastChrSrcY;
}
ff_rotate_slice(hout_slice, lastPosY, lastCPosY);
if (posY < lastLumSrcY + 1) {
for (i = lumStart; i < lumEnd; ++i)
desc[i].process(c, &desc[i], firstPosY, lastPosY - firstPosY + 1);
}
lastInLumBuf = lastLumSrcY;
if (cPosY < lastChrSrcY + 1) {
for (i = chrStart; i < chrEnd; ++i)
desc[i].process(c, &desc[i], firstCPosY, lastCPosY - firstCPosY + 1);
}
lastInChrBuf = lastChrSrcY;
if (!enough_lines)
break; // we can't output a dstY line so let's try with the next slice
#if HAVE_MMX_INLINE
ff_updateMMXDitherTables(c, dstY);
#endif
if (should_dither) {
c->chrDither8 = ff_dither_8x8_128[chrDstY & 7];
c->lumDither8 = ff_dither_8x8_128[dstY & 7];
}
if (dstY >= c->dstH - 2) {
/* hmm looks like we can't use MMX here without overwriting
* this array's tail */
ff_sws_init_output_funcs(c, &yuv2plane1, &yuv2planeX, &yuv2nv12cX,
&yuv2packed1, &yuv2packed2, &yuv2packedX, &yuv2anyX);
use_mmx_vfilter= 0;
ff_init_vscale_pfn(c, yuv2plane1, yuv2planeX, yuv2nv12cX,
yuv2packed1, yuv2packed2, yuv2packedX, yuv2anyX, use_mmx_vfilter);
}
for (i = vStart; i < vEnd; ++i)
desc[i].process(c, &desc[i], dstY, 1);
}
if (isPlanar(dstFormat) && isALPHA(dstFormat) && !needAlpha) {
int offset = lastDstY - dstSliceY;
int length = dstW;
int height = dstY - lastDstY;
if (is16BPS(dstFormat) || isNBPS(dstFormat)) {
const AVPixFmtDescriptor *desc = av_pix_fmt_desc_get(dstFormat);
fillPlane16(dst[3], dstStride[3], length, height, offset,
1, desc->comp[3].depth,
isBE(dstFormat));
} else if (is32BPS(dstFormat)) {
const AVPixFmtDescriptor *desc = av_pix_fmt_desc_get(dstFormat);
fillPlane32(dst[3], dstStride[3], length, height, offset,
1, desc->comp[3].depth,
isBE(dstFormat), desc->flags & AV_PIX_FMT_FLAG_FLOAT);
} else
fillPlane(dst[3], dstStride[3], length, height, offset, 255);
}
#if HAVE_MMXEXT_INLINE
if (av_get_cpu_flags() & AV_CPU_FLAG_MMXEXT)
__asm__ volatile ("sfence" ::: "memory");
#endif
emms_c();
/* store changed local vars back in the context */
c->dstY = dstY;
c->lastInLumBuf = lastInLumBuf;
c->lastInChrBuf = lastInChrBuf;
return dstY - lastDstY;
}
- 可以看出swscale()是一行一行的进行图像缩放工作的。其中每行数据的处理按照“先水平拉伸,然后垂直拉伸”的方式进行处理。
- 具体的实现函数如下所示:
- 1. 水平拉伸
- a) 亮度水平拉伸:hyscale()
- b) 色度水平拉伸:hcscale()
- 2. 垂直拉伸
- a) Planar
- i. 亮度垂直拉伸-不拉伸:yuv2plane1()
- ii. 亮度垂直拉伸-拉伸:yuv2planeX()
- iii. 色度垂直拉伸-不拉伸:yuv2plane1()
- iv. 色度垂直拉伸-拉伸:yuv2planeX()
- b) Packed
- i. 垂直拉伸-不拉伸:yuv2packed1()
- ii. 垂直拉伸-拉伸:yuv2packedX()
- 下面具体看看这几个函数的定义。
hyscale()
- 水平亮度拉伸函数hyscale()的定义位于libswscale\swscale.c,如下所示。 并不存在
/**
* Scale one horizontal line of input data using a filter over the input
* lines, to produce one (differently sized) line of output data.
*
* @param dst pointer to destination buffer for horizontally scaled
* data. If the number of bits per component of one
* destination pixel (SwsContext->dstBpc) is <= 10, data
* will be 15 bpc in 16 bits (int16_t) width. Else (i.e.
* SwsContext->dstBpc == 16), data will be 19bpc in
* 32 bits (int32_t) width.
* @param dstW width of destination image
* @param src pointer to source data to be scaled. If the number of
* bits per component of a source pixel (SwsContext->srcBpc)
* is 8, this is 8bpc in 8 bits (uint8_t) width. Else
* (i.e. SwsContext->dstBpc > 8), this is native depth
* in 16 bits (uint16_t) width. In other words, for 9-bit
* YUV input, this is 9bpc, for 10-bit YUV input, this is
* 10bpc, and for 16-bit RGB or YUV, this is 16bpc.
* @param filter filter coefficients to be used per output pixel for
* scaling. This contains 14bpp filtering coefficients.
* Guaranteed to contain dstW * filterSize entries.
* @param filterPos position of the first input pixel to be used for
* each output pixel during scaling. Guaranteed to
* contain dstW entries.
* @param filterSize the number of input coefficients to be used (and
* thus the number of input pixels to be used) for
* creating a single output pixel. Is aligned to 4
* (and input coefficients thus padded with zeroes)
* to simplify creating SIMD code.
*/
/** @{ */
void (*hyScale)(struct SwsContext *c, int16_t *dst, int dstW,
const uint8_t *src, const int16_t *filter,
const int32_t *filterPos, int filterSize);
void (*hcScale)(struct SwsContext *c, int16_t *dst, int dstW,
const uint8_t *src, const int16_t *filter,
const int32_t *filterPos, int filterSize);
缺失内容


























 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









