



 本文分享了Cocos Creator游戏开发中的实用技巧,包括代码优化、资源管理、动作控制、声音播放、事件监听等,帮助开发者提升游戏质量和开发效率。
本文分享了Cocos Creator游戏开发中的实用技巧,包括代码优化、资源管理、动作控制、声音播放、事件监听等,帮助开发者提升游戏质量和开发效率。
项目链接:https://github.com/cocos-creator/tutorial-first-game/tree/master/complete_project
1.this全局变量和let局部变量的使用
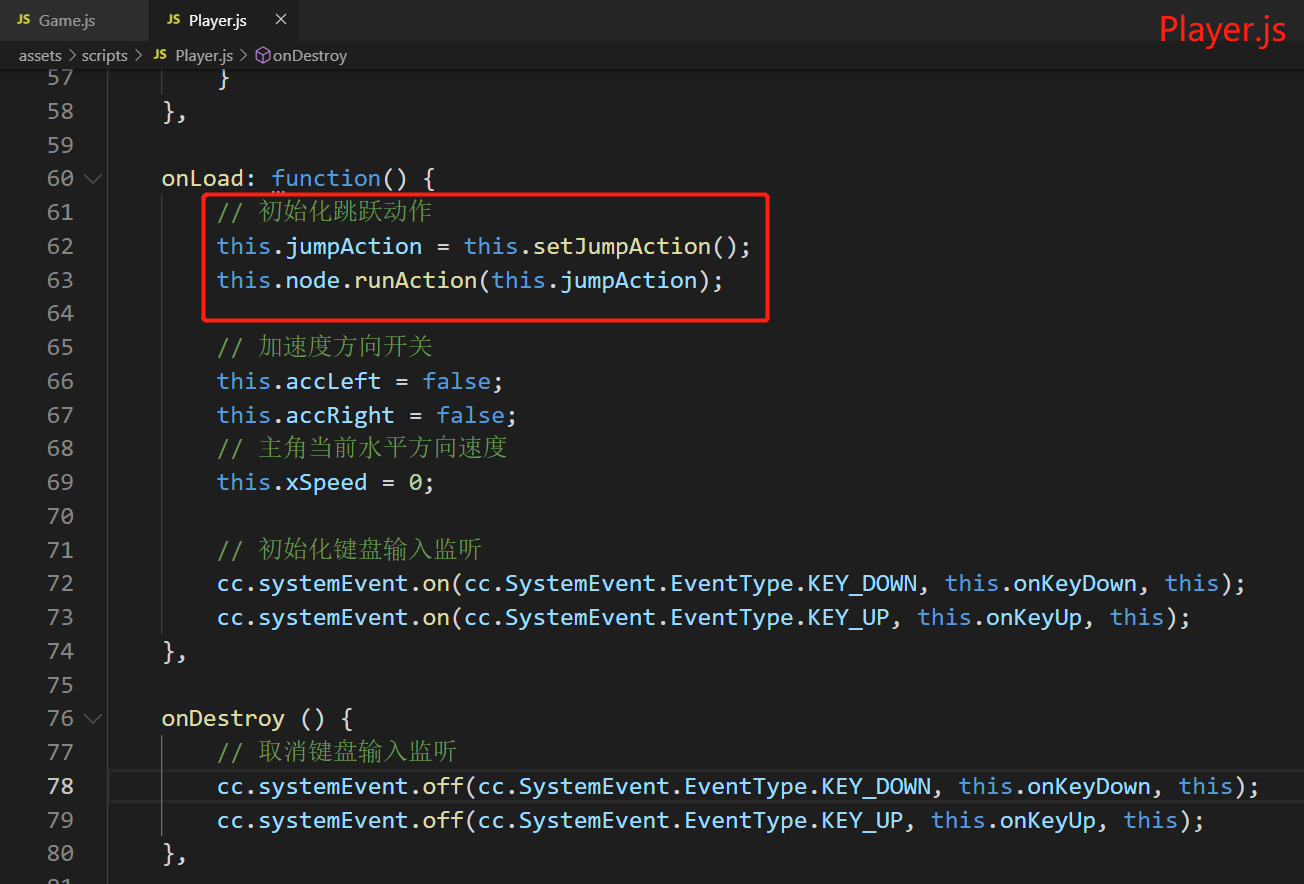
修改后的代码
1 // 使用let局部变量 2 let jumpAction = this.setJumpAction(); 3 this.node.runAction(jumpAction);
2.脚本文件里的属性和方法应该严格地归类好
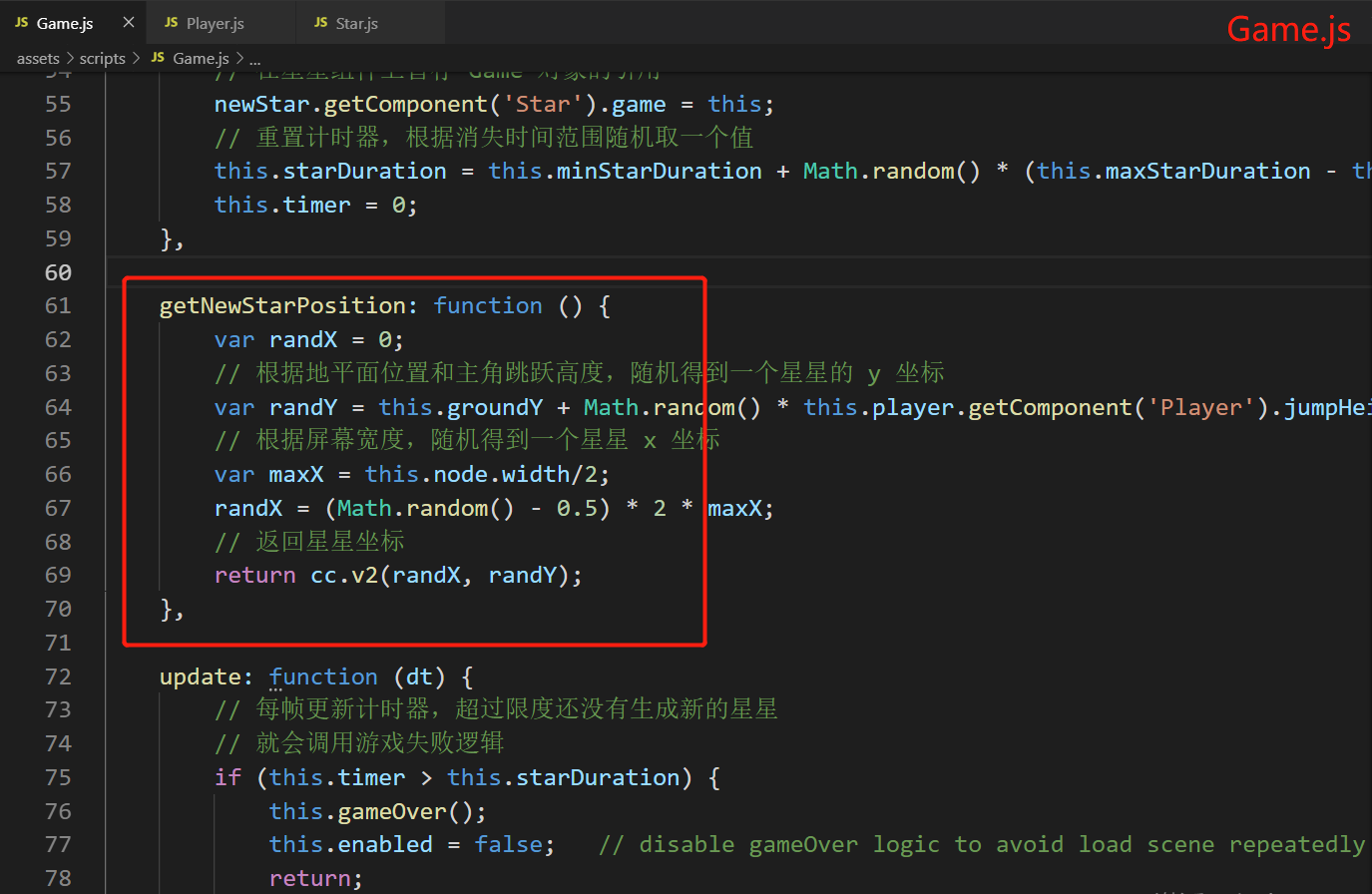
如果把Game.js里面的getNewStarPosition()方法写到Star.js当中,会更好理解以及便于维护
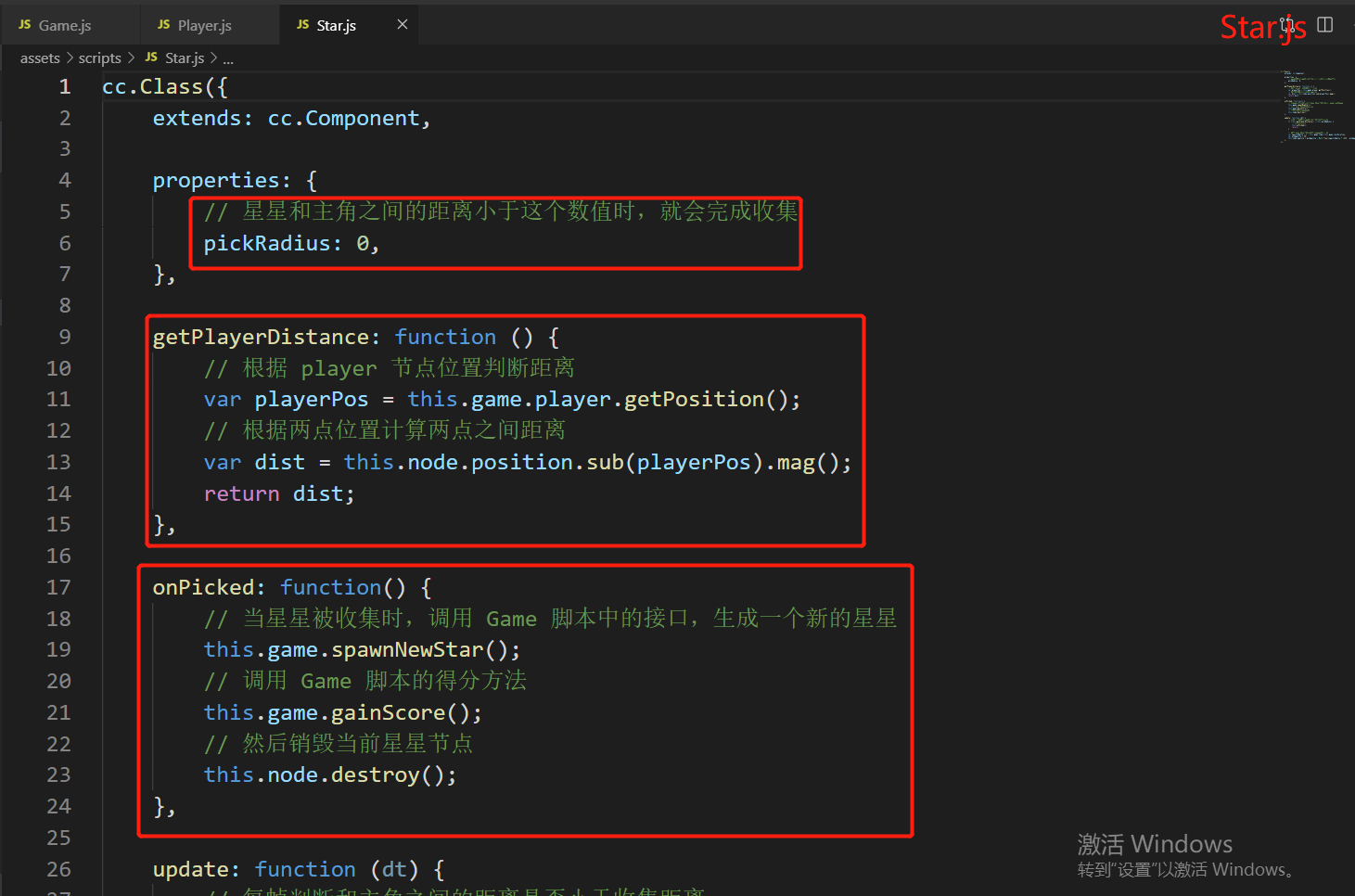
在Star.js当中,按照常理,是主角去捡星星,而不是星星等待主角过来,所以我觉得pickRadius属性以及getPlayerDistance和onPicked方法可以写在Player.js
3.如果不是经常修改的属性,尽量不要显式地暴露出来
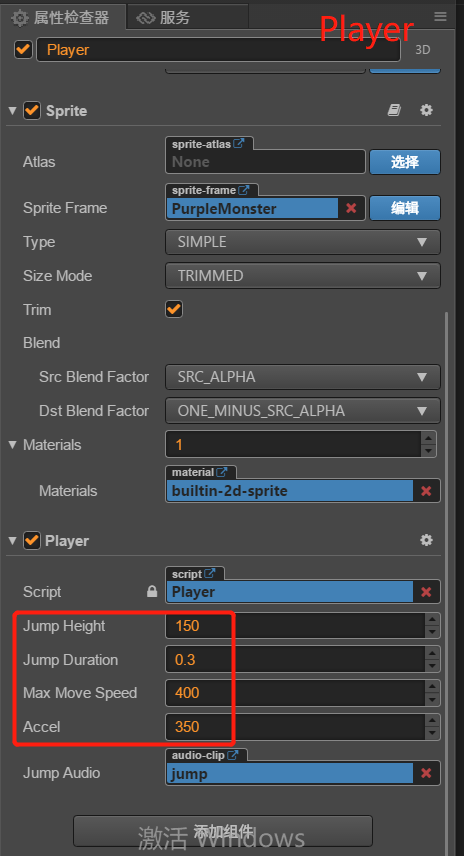
通常数值系统策划好了,就不要随意地更改数值,脚本属性暴露出来,很容易一不小心就随意修改数值,但是写到代码里的数据就不容易被随意修改
4.预制资源使用场合
什么时候会用到预制资源?通常在需要通过程序来动态地生成节点资源时会使用到
5.在星星组件上暂存 Game 对象的引用
1 newStar.getComponent('Star').game = this;
通过Node对象调用getComponent()方法,返回的是一个Component类型的对象,组件对象也称脚本对象。巧妙之处,通过脚本对象调用game属性,从而为Star脚本文件添加了一个全局变量game,使得Star脚本也可以访问Game脚本里面所有的属性和方法
6.停止并且移除所有正在运行的动作列表
1 //停止 player 节点的跳跃动作 2 this.player.stopAllActions();
7.通过回调函数来执行音频播放
1 // 添加一个回调函数,用于在动作结束时调用我们定义的其他方法 2 var callback = cc.callFunc(this.playJumpSound, this); 3 4 // 不断重复,而且每次完成落地动作后调用回调来播放声音 5 cc.repeatForever(cc.sequence(jumpUp, jumpDown, callback));
8.不同脚本组件调用onload方法时互不影响
Game.js执行生成星星操作与Player.js执行主角跳跃动作互补干扰
9.初始化键盘输入监听
1 // 初始化键盘输入监听 2 cc.systemEvent.on(cc.SystemEvent.EventType.KEY_DOWN, this.onKeyDown, this); 3 cc.systemEvent.on(cc.SystemEvent.EventType.KEY_UP, this.onKeyUp, this); 4 5 onDestroy () { 6 // 结束游戏之后,取消键盘输入监听 7 cc.systemEvent.off(cc.SystemEvent.EventType.KEY_DOWN, this.onKeyDown, this); 8 cc.systemEvent.off(cc.SystemEvent.EventType.KEY_UP, this.onKeyUp, this); 9 },
cc.systemEvent.on();注册事件目标的特定事件类型回调
cc.systemEvent.off();删除之前用同类型,回调,目标或 useCapture 注册的事件监听器,如果只传递 type,将会删除 type 类型的所有事件监听器
10.event参数传递
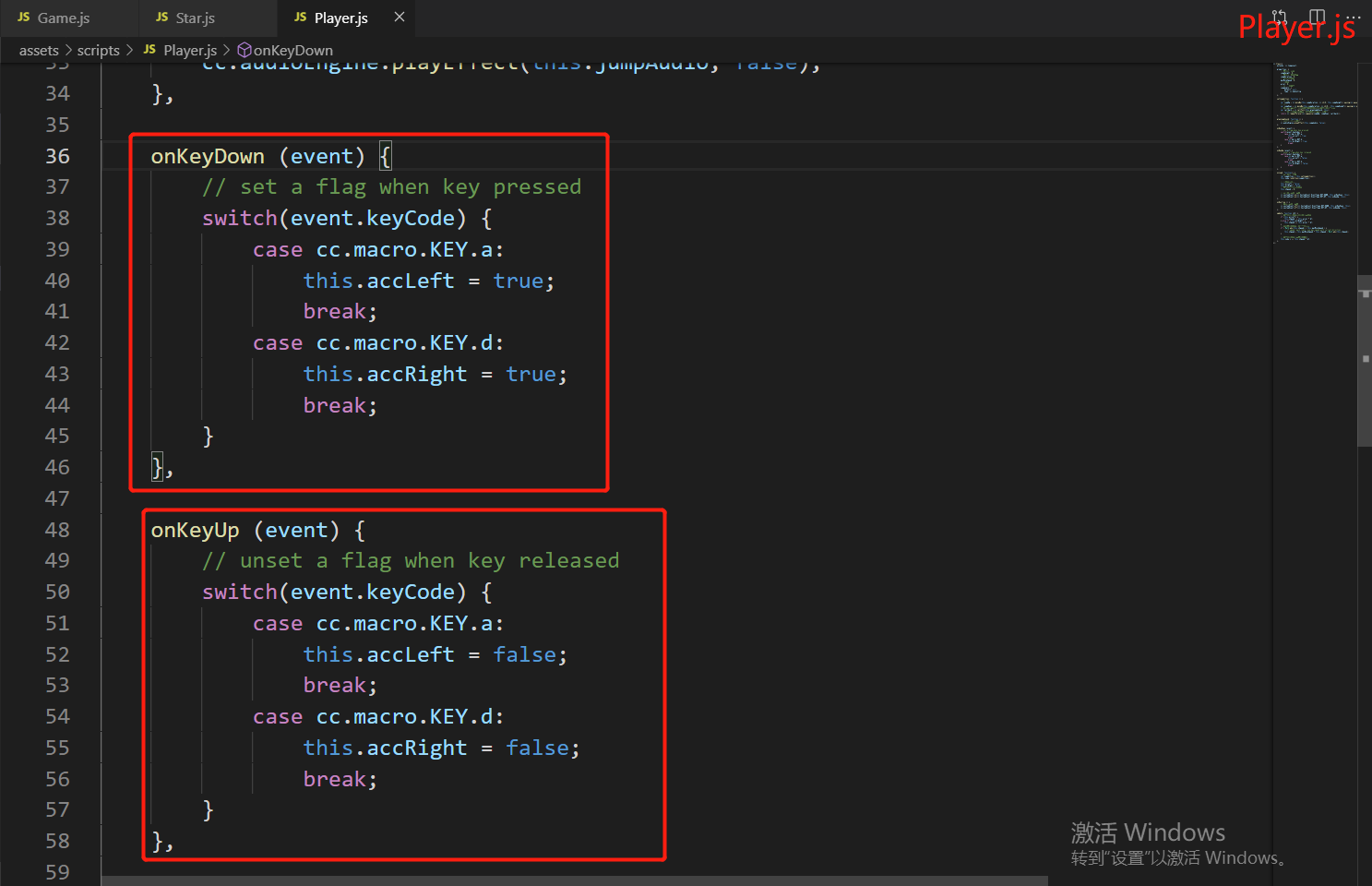
通过event参数传递,可以获得有关键盘相关按键的信息
11.通过数学运算来判断正负值
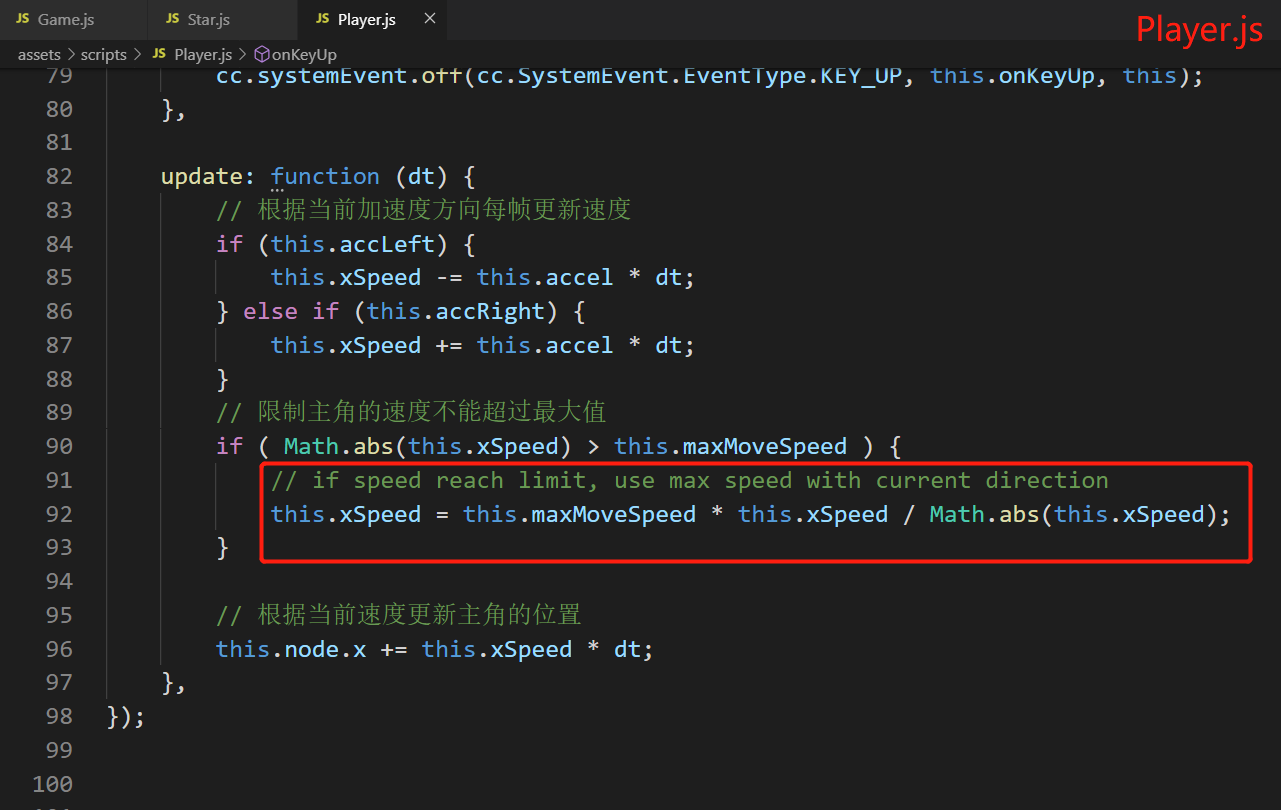
巧妙之处this.xSpeed / Math.abs(this.xSpeed),通过数学运算方法来判断速度为正还是为负,就不需要通过this.accLeft和this.accRight属性来判断速度的正负值,节省代码
12.return的作用
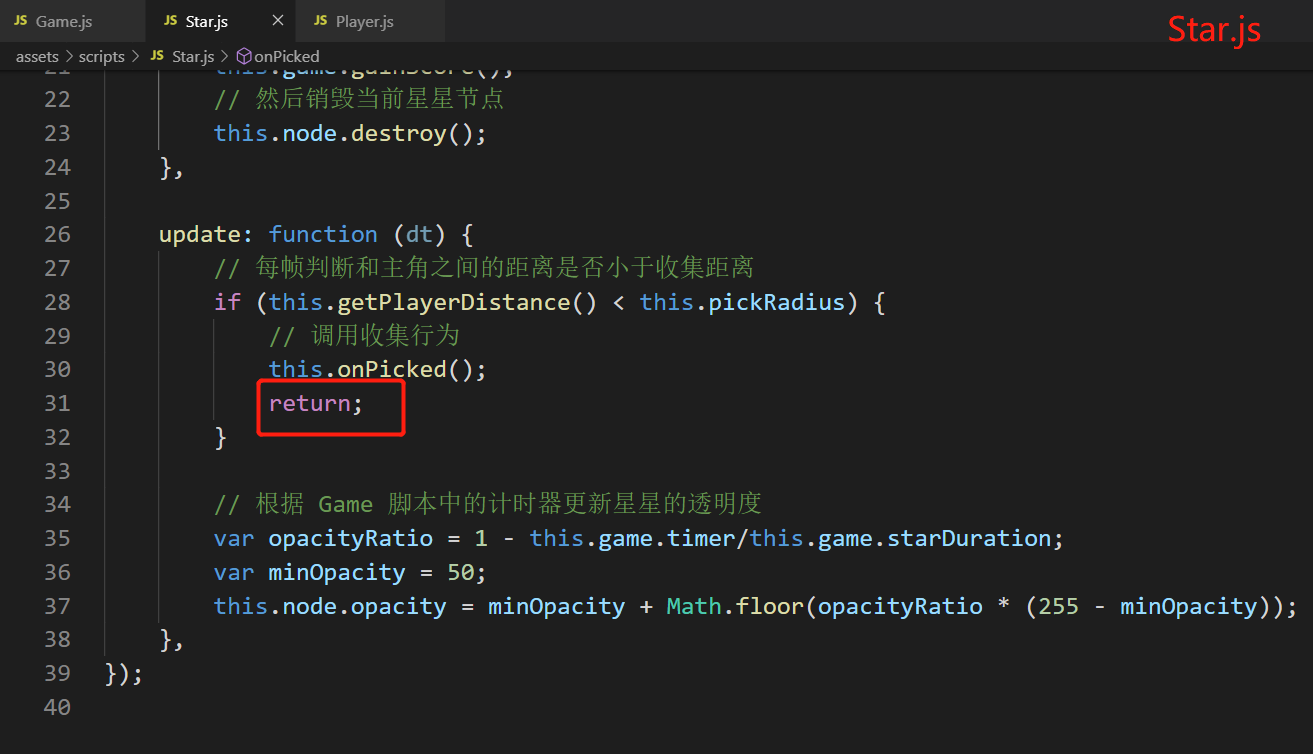
巧妙使用return语句,当if条件成立时,执行return语句,结束当前update操作。return与break的不同之处,break只能结束当前循环,而return结束整个函数,return作用比break更强大些
13.计算两点之间位置的距离
1 // 根据 player 节点位置判断距离 2 var playerPos = this.game.player.getPosition(); 3 // 根据两点位置计算两点之间距离 4 var dist = this.node.position.sub(playerPos).mag();
vec2.sub();向量减法
vec2.mag();返回该向量的长度
通过sub向量减法来计算两点之间位置的距离,比物理碰撞算法还要简单方便
14.cc.repeatForever()、cc.sequence()
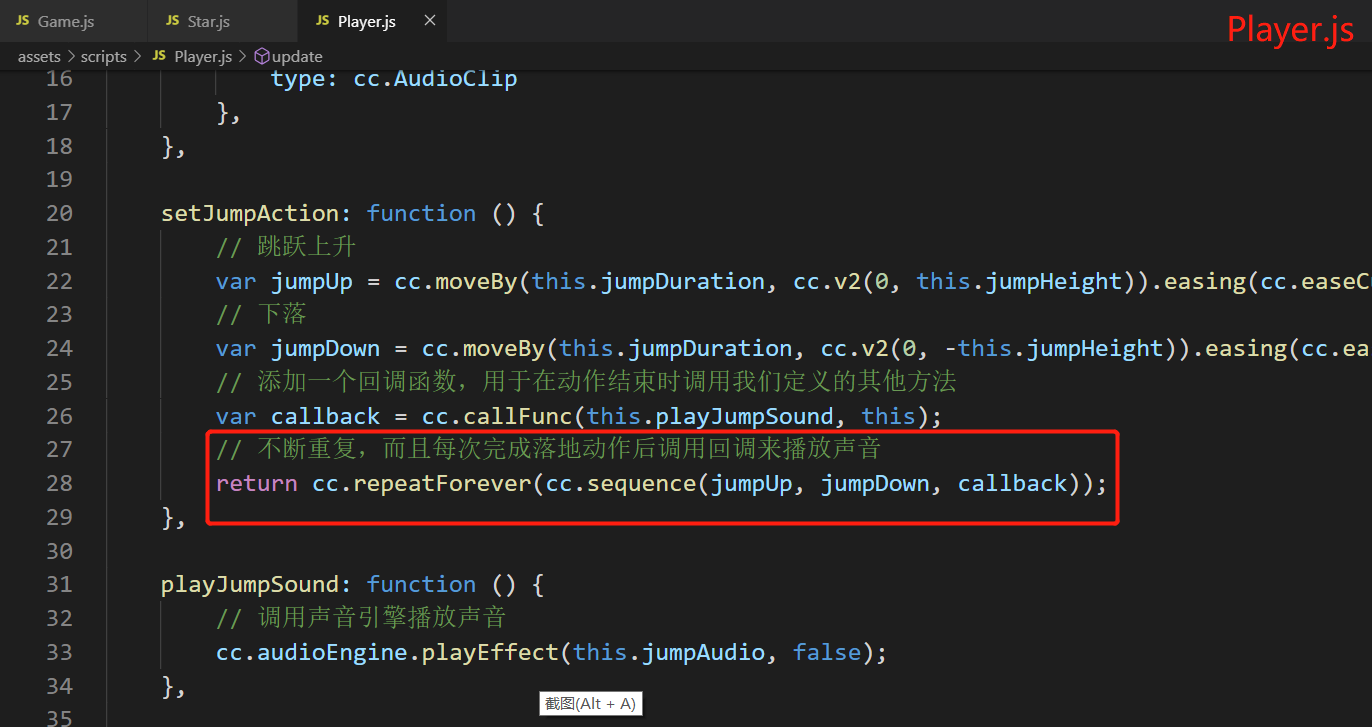
cc.repeatForever();永远地重复一个动作,有限次数内重复一个动作请使用 repeat 动作,由于这个动作不会停止,所以不能被添加到 cc.sequence 或 cc.spawn 中
cc.sequence();顺序执行动作,创建的动作将按顺序依次运行
15.cc.macro.KEY
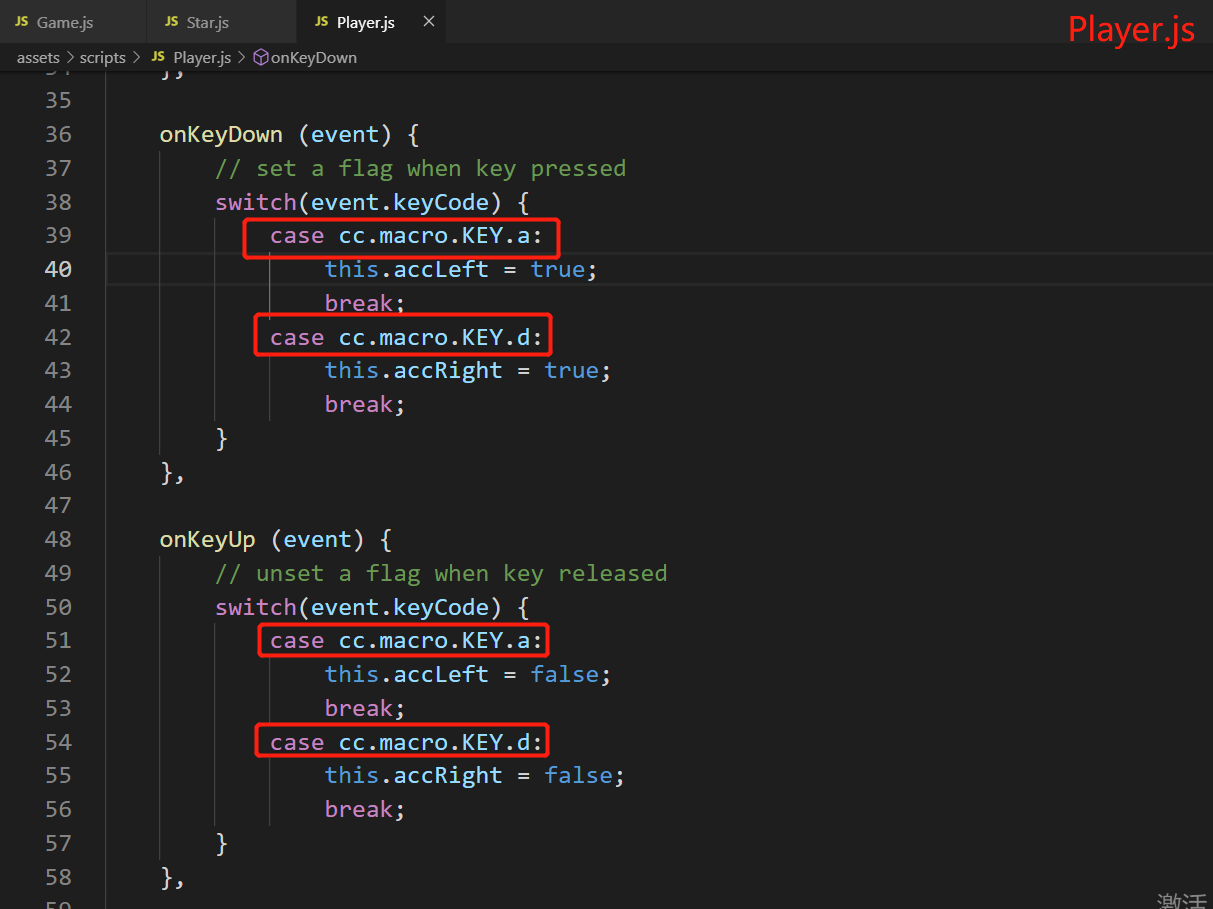
cc.macro.KEY;键盘事件的按键值
16.播放声音
1 // 调用声音引擎播放声音 2 cc.audioEngine.playEffect(this.jumpAudio, false);
17.runAction
1 // 初始化跳跃动作 2 let jumpAction = this.setJumpAction(); 3 this.node.runAction(jumpAction);
node.runAction();执行并返回该执行的动作。该节点将会变成动作的目标。调用 runAction 时,节点自身处于不激活状态将不会有任何效果。
注意:你不应该修改 runAction 后的动作,将无法发挥作用,如果想进行修改,请在定义 action 时加入
18.moveBy和moveTo的区别
你能注意到,每一个动作都会有两个方法 By 和 To。两种方法方便你在不同的情况使用,By 算的是相对于节点对象的当前位置,To 算的是绝对位置,不考虑当前节点对象在哪。如果你想动作的表现是相对于 Node 当前位置的,就用 By,相对的想让动作的表现是按照坐标的绝对位置就用 To

















 1105
1105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









