







**
标识符规范
**
强类型语言:有具体数据类型。
"a"和’a’不一样
ArrayList是数组型列表
LinkedList是链式列表
有增删改查操作
Collection接口存储一组不唯一(可重复),无序的对象
List接口存储一组有序可重复的对象
Set 接口存储一组无序唯一的对象
Map接口存储一组键值对,提供key到value的映射
Java集合框架collection接口
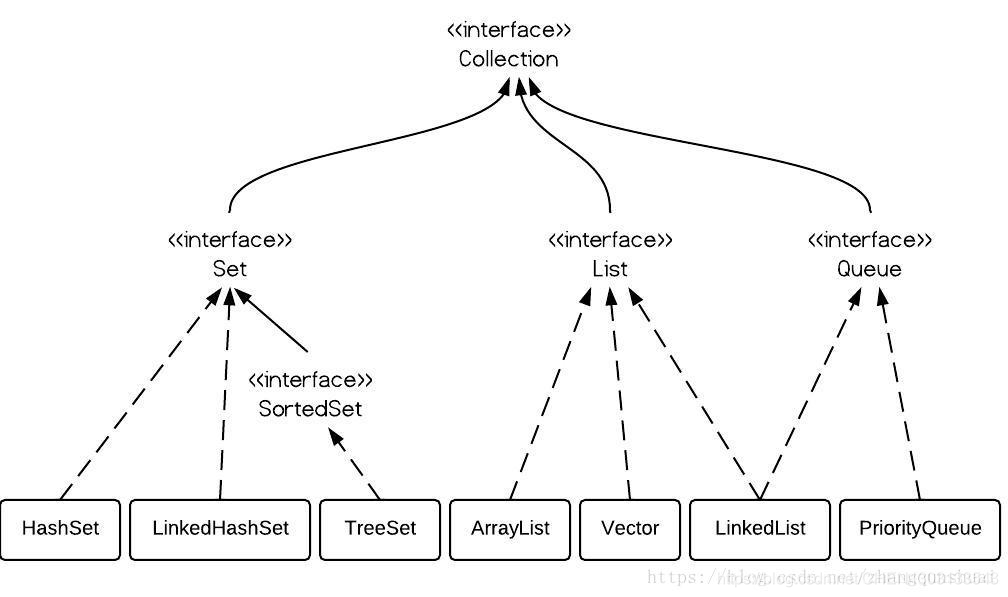
list:有序可重复
ArrayList:底层结构是数组,查询快,增删慢,线程不安全,效率高
LinkedList:双向链表,增删方便,查询慢,线程不安全,效率高
java.Util.Vector
Vector vector = new Vector();
1、Vector是List接口的一个子类实现
2、Vector和ArrayList一样,底层结构都是数组
3、区别:
1》ArrayList、LinkedList线程不安全,效率高,Vector线程安全效率低(synchronized)
2》ArrayList扩容的时候,是扩容1.5倍,Vector扩容到原来的2倍
使用的方法都差不多。
list遍历:
1、for循环
2、iterator迭代器
3、foreach增强for循环
所有集合都默认实现了iterable接口,实现此皆苦意味着具备了增强for循环的能力也就是for-each,
方法:iterator()、foreach()
在iterator方法中要求返回一个Iterator的接口子类实例对象,这个接口包含了hasNext()\next()
set:无序唯一
Set set = new Set();
HashSet:采用Hashtable哈希表存续结构,底层实现是hashmap
优点:curd速度快
缺点:无序
hashset.add(new 自定义对象);此时存入的是对象的地址值,可能会有两个相同值的对象存入(地址不同,对象值相同),不符合预期。
注意:add()的是自定义对象,会查找对象中的equals和hashcode的方法,如果没有就比较对象的地址,地址不同hashseta就认为这两个对象不同。
解决方法:对象类中重写equals和hashcode的方法。(启示:写对象类的时候重写equals和hashcode的方法)
LinkedHashSet:采用哈希表存储结构,同时使用链表维护顺序
TreeSet:采用二叉树(红黑树)存储结构
优点:有序(排序后升序),查询速度比list快
缺点:查询速度比hashset慢。
TreeSet treeSet = new TreeSet();
treeSet添加add数字,内存中会以二叉树形式存储。输出有序数字。
底层实现是treemap,利用红黑树实现
AVL数树:平衡二叉搜索树
红黑树:自平衡二叉查找树
HashSet如何保证元素唯一性?
通过元素的两个方法,equals和hashcode方法,
如果hashcode相同才会判断equals是否为true,
不同就不是相同元素,不调用equals方法。
红黑树怎样排序?
所有可以“排序”的类都实现了java.lang.Comparable接口,
comparable接口只定义了一个方法:compareTo(obj)实现对象的排序。
接口实现:
public int compareTo(Object obj){
if(this > obj){
return 1;
}else if(this <obj){
return -1;
}else{
return 0;
}
}
树中的元素是要默认进行排序操作的,基本数据类型会自动比较,引用类型就需要自己自定义比较器了。
内部比较器:定义在实体类中,实现Comparable接口,@Override int compareTo(引用对象){}方法来实现
外部比较器:定义在需要的类(service业务类)中,实现Comparator接口,@Override int compare(Entity 引用1, Entity 引用2) {}方法来实现,但是需要将该比较器传递到集合中。
注意:外部比较器可以定义成一个工具类,所有需要比较的规则如果一致可以复用,内部比较器只有在存储当前对象的时候才可以使用。
如果两者同时存在,使用外部比较器。
当使用比较器的时候,不会调用equals方法
原compareTo方法,只有声明,没有方法体。因此treeset在比较引用对象的时候会报错ClassCaseException,解决之道就是重写compareTo方法。
底层都是servlet,框架只不过是一层包装。

泛型
List list = new ArrayList();
list.add(123);
list.add(“abc”);
list.add(true);
不加泛型的list可以存入任何数据类型,List加上泛型,只能存入一种数据类型。统一规定操作的数据类型。
统一规定操作的数据类型:
1、数据安全
2、获取数据效率比较高
泛型高阶
1、自定义泛型类:public class MyClass<E>
2、泛型接口interface MyClass<E>
1》子类进行实现的时候可以不写泛型类型,在创建子类对象的时候才决定使用什么类型。
2》子类实现泛型接口的时候,只在实现父类的接口的时候指定父类泛型类型即可,测试方法中的泛型要和子类保持一致。
3、泛型方法,在定义方法的时候,指定方法的返回值和参数是泛型
1》定义方法的时候,指定方法的返回值类型和参数是自定义的占位符(泛型),了解就行
4、泛型上限,如果父类限定了,所有的子类都可以直接使用(工作中不用,只在API中有)
5、泛型下限,如果子类确定了,子类所有的父类都可以直接传递参数(工作中不用,只在API中有)
Map
key-value键值对:map\session\redis\json\
好处:对于大量数据,给数据做一个key值的索引,便于查找,快速查找

list\set接口继承于collection
map是独立接口
key:相当于索引,value是无序的集合,通过key可以快速找到value
hashmap:底层是hash表,数组,数据+链表(1.7)数组+链表+红黑树(1.8)
-key无序 唯一(set集合)
-value无序 不唯一(collection)
linkedhashmap:链式hash表
-有序的hashmap 速度快
treemap:红黑树
-有序 速度没有hash快
set和map采用了相同的数据结构,只用于map的key存储数据
方法:看API文档
增:put(k,v)
查:map.isEmpty()\map.size()
map.get(k)\map.containsKey(k)
map.containsValue(v)
删:map.clear()\map.remove(k)
遍历:
1、键集合,遍历key
Set keys = map.ketSet();
for(String key : keys){
syso(map.get(key));
}
2、值集合,遍历value
Collection values = map.value();
for(Integer i : values){
syso(i);
}
3、迭代器
Set keys = map.ketSet();
Iteretor iteretor = keys.iteretor();
while(iteretor.hashNext()){
String key = iterate.next();
syso(key+"="+map.get(key));
}
4、map.Enty
Set<Map.Entry<String,Integer>> entries = map.entrySet();
Iterator<Map.Entry<String,Integer>> iterator = entry.iterator();
while(iterator.hashNext()){
Map.Entry<String,Integer> next = iterator.next();
syso(next.getKey+"–"+next.getValue());
}
hashmap和hashtable的区别?
类似于stringbuff和stringbuilder,线程问题。
hashmap:线程不安全,效率高。hashtable:线程安全,效率低。(synchronized)
hashmap中的key和value都可以为空,hashtable都不允许为空。

















 481
481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









