







sqoop
1.什么是sqoop
sqoop 是 apache 旗下一款“Hadoop 和关系数据库服务器之间传送数据”的工具。
sqoop的本质:
将sqoop的迁入 迁出的命令 转换为mapreduce任务
迁入: mysql —》 hdfs|hive|hbase
从mysql读取数据 写出到hdfs上
Mapper 读取数据 从数据库读取 InputFormat–>DBInputFormat
map(){
context.write()
}
定义了mapreduce的 文件输入类 只需要maptask就可以完成
迁出:hdfs|hive|hbase —> mysql
从hdfs读取数据 — 写出mysql中
Mapper端:
从hdfs读取数据
context.write() 写出mysql中 OutputfORMAT–>DBOutputFormat
定义了 mapreduce的输出类 只需要maptask就可以完成
sqoop的本质相当于定制了 mapreduce的输入类 和输出类
2.sqoop的基本的命令
使用sqoop help 可以看到所有的命令(主要掌握两个命令 export import 两个 )
codegen ---------Generate code to interact with database records
create-hive-table ------------Import a table definition into Hive
eval ----------------Evaluate a SQL statement and display the results
export -----------Export an HDFS directory to a database table 输出一个hdfs的文件到数据库
help--------------- List available commands
import ------------Import a table from a database to HDFS 将数据库中的文件输出到hdfs中
import-all-tables------------Import tables from a database to HDFS
import-mainframe------------Import datasets from a mainframe server to HDFS
job---------------Work with saved jobs
list-databases -----------List available databases on a server
list-tables -------------List available tables in a database
merge---------------Merge results of incremental imports
metastore ------------- Run a standalone Sqoop metastore
version ---------------Display version information
如果向查看具体命令的使用方法可以使用如下的命令
比如 import命令的具体使用
sqoop help import
3.数据导入hdfs
3.1
“导入工具”导入单个表从 RDBMS 到 HDFS。表中的每一行被视为 HDFS 的记录。所有记录都存储为文本文件的文本数据(或者 Avro、sequence 文件等二进制数据)
下边用一个例子来实现一下,需求是将mysql数据库中的一张表导入到hdfs中
mysql中的表的格式如下:
输入导入的命令:
将mysql中的 test数据库中的一张student的表插入到hdfs中
sqoop import \
--connect jdbc:mysql://hadoop01:3306/test \
--username root \
--password root \
--table student \
-m 1
导入hdfs中的默认的目录是:/user/hadoop/student(mysql中的表名)
生成的文件的格式如下:
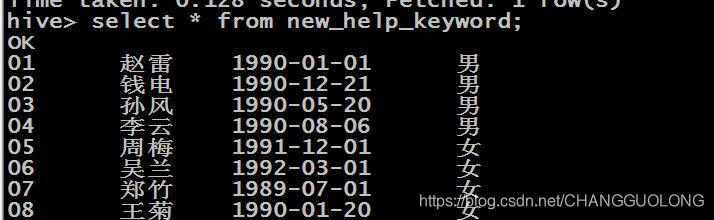
01,赵雷,1990-01-01,男
02,钱电,1990-12-21,男
03,孙风,1990-05-20,男
04,李云,1990-08-06,男
05,周梅,1991-12-01,女
06,吴兰,1992-03-01,女
07,郑竹,1989-07-01,女
08,王菊,1990-01-20,女
从以上结果可以得出一个结论:如果没有指定路径,则会按默认规则生成路径,如果没有
指定分隔符,默认按照逗号分隔
3.2指定路径和指定分隔符进行插入到hdfs中
还是将上边的那张表进行插入
sqoop import \
--connect jdbc:mysql://hadoop01:3306/test \
--username root \
--password root \
--table student \
--target-dir /user/hadoop/student_mysql_test \
--fields-terminated-by '\t' \
-m 1
--target-dir 指定需要导入的hdfs目录
--fields-terminated-by 指定导出文件 列之间的分割符 默认的分割符,
生成的文件的路径是:/user/hadoop/student_mysql_test
生成的文件的格式如下:
01 赵雷 1990-01-01 男
02 钱电 1990-12-21 男
03 孙风 1990-05-20 男
04 李云 1990-08-06 男
05 周梅 1991-12-01 女
06 吴兰 1992-03-01 女
07 郑竹 1989-07-01 女
08 王菊 1990-01-20 女
3.3导入where子句的内容:使用where的过滤条件选择指定的内容进行导入
例如:导入所有的男生的信息到hdfs中
sqoop import \
--connect jdbc:mysql://hadoop01:3306/test \
--username root \
--password root \
--where "s_sex='男'" \
--table student \
--target-dir /user/hadoop/student_mysql_test/man \
--fields-terminated-by '\t' \
-m 1
输出的结果如下:
01 赵雷 1990-01-01 男
02 钱电 1990-12-21 男
03 孙风 1990-05-20 男
04 李云 1990-08-06 男
3.4 导入过程指定查询的语句
例如:查出名字中带"菊"的学生的信息,将此信息插入到hdfs中
sqoop import \
--connect jdbc:mysql://hadoop01:3306/test \
--username root \
--password root \
--query 'SELECT * from student where s_name like "%菊%" and $CONDITIONS' \
--target-dir /user/hadoop/student_mysql_test/query \
--fields-terminated-by '\t' \
-m 1
–split-by 指定每一个maptask切分数据的依据字段 mysql中主键 整型的
多个maptask之间 就会按照指定的字段 切分数据
按照指定的切分字段 (最大值-最小值+1) /4
1 1 1 1 1 2 2 3 4 4 4 4 4
4-1+1 /4 =1
每一个maptask 1个值
maptask0 1 1 1 1 1
maptask1 2 2
maptask3 3
maptask4 4 4 4 4 4
id 201 – 452 452-201+1 /4=63
201-263
264-326
327-389
390-452
1 1 1 4 4 4 6 6 6 6 9 9 9
2maptask 9-1+1/2 =5
maptask0 1-5
maptask1 5-9
这里需要注意:
①查询的语句后边需要加上and $CONDITIONS
②查询的语句的外边使用单引号 里边使用双引号
③必须制定目标文件的位置–target-dir
④你也可以选择使用–split-by分片(分区,结果分成多个小文件,请参考mapreduce分区)
查询的结果如下:
08 王菊 1990-01-20 女
4.数据导入到hive
4.1sqoop数据导入到hive表的过程是需要先将数据导入到hdfs之后将hdfs中的数据load到hive的表中,只不过这个过程自动完成
4.2实例
4.2.1普通的导入
将mysql 中test数据库中的student的表插入到hive表中
sqoop import \
--connect jdbc:mysql://hadoop01:3306/test \
--username root \
--password root \
--table student \
--hive-import \
-m 1
注意:
①此时系统会默认先将文件写入到hdfs中,会默认存在hdfs的/user/hadoop/student(表名)的目录下,所以要保证这个目录不存在的前提下使用
②此时导入到HIVe中的default的数据库中,名字和mysql中表的名字是一样的,采用'\u0001'分隔
4.2.2 指定hive中的数据库和表的名字进行插入
sqoop import \
--connect jdbc:mysql://hadoop01:3306/test \
--username root \
--password root \
--table student \
--fields-terminated-by "\t" \
--lines-terminated-by "\n" \
--hive-import \
--hive-overwrite \
--create-hive-table \
--hive-table mydb_test.new_help_keyword \
--delete-target-dir
注意:表会自动创建,但是库不会。所以在执行该语句之前,一定要确保 hive 的数据库mydb_test 是存在的,否则程序会报错
成功在hive中的指定的数据库中创建了表对表进行查询 查询的结果如下:
4.2.3增量数据的导入
增量导入是仅导入表中新添加的行的技术。
它需要添加 ‘incremental’ , ‘check-column’, 和 ‘last-value’ 选项来执行增量导入。
例子:
在mysql的student的表中新增一些内容,将新增的内容导入到hdfs上
sqoop import \
--connect jdbc:mysql://hadoop01:3306/test \
--username root \
--password root \
--table student \
--target-dir /user/hadoop/myimport3 \
--incremental append \
--check-column s_id \
--last-value '04' \
-m 1
5.将mysql中的数据导入到hbase
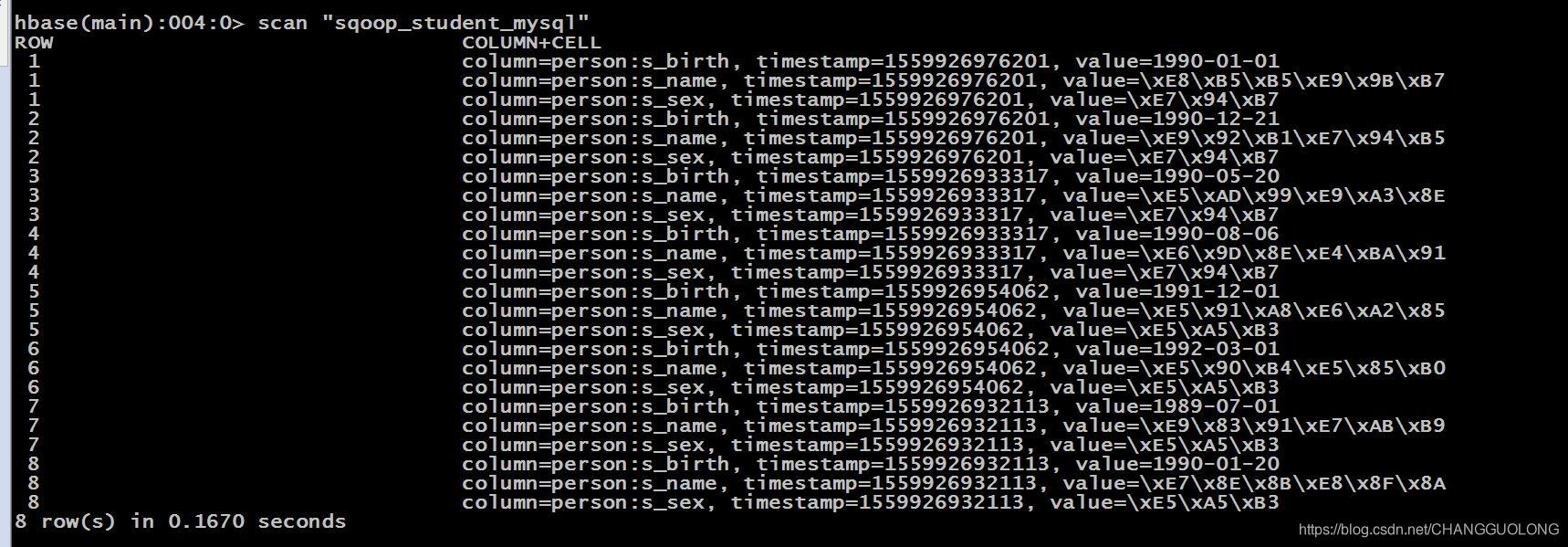
首先在hbase中创建一个"sqoop_student_mysql"的表 指定列簇
sqoop import \
--connect jdbc:mysql://hadoop01:3306/test \
--hbase-table sqoop_student_mysql \
--column-family person \
--hbase-row-key s_id \
--username root \
--password root \
--table student
字段解释
--connect jdbc:mysql://hadoop04:3306/mysql 表示远程或者本地 Mysql 服务的 URI
--hbase-create-table 表示在 HBase 中建立表。
--hbase-table new_help_keyword 表示在 HBase 中建立表 new_help_keyword。
--hbase-row-key help_keyword_id 表示hbase表的rowkey是mysql表的help_keyword_id字段。
--column-family person 表示在表 new_help_keyword 中建立列族 person。
--username 'root' 表示使用用户 root 连接 mysql。
--password 'root' 连接 mysql 的用户密码
--table help_keyword 表示导出 mysql 数据库的 help_keyword 表。
结果展示:
6.sqoop数据导出
6.1将hdfs中的数据导出到mysql
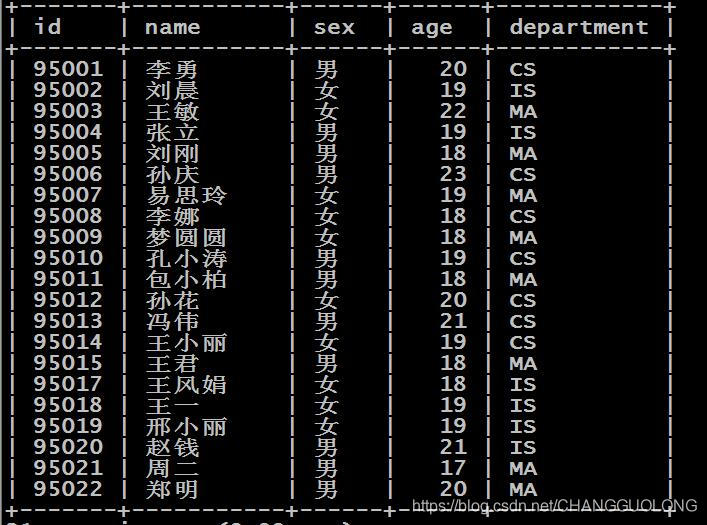
现在/student.txt文件导出到mysql中
源文件如下:
95002,刘晨,女,19,IS
95017,王风娟,女,18,IS
95018,王一,女,19,IS
95013,冯伟,男,21,CS
95014,王小丽,女,19,CS
95019,邢小丽,女,19,IS
95020,赵钱,男,21,IS
95003,王敏,女,22,MA
95004,张立,男,19,IS
在mysql中需要先创建表
create database sqoopdb default character set utf8 COLLATE utf8_general_ci;
use sqoopdb;
CREATE TABLE sqoopstudent (
id INT NOT NULL PRIMARY KEY,
name VARCHAR(20),
sex VARCHAR(20),
age INT,
department VARCHAR(20)
);
执行导出
sqoop export \
--connect jdbc:mysql://hadoop01:3306/sqoopdb \
--username root \
--password root \
--table sqoopstudent \
--export-dir /student.txt \
--fields-terminated-by ','
6.2导出 HIVE 数据到 MySQL
sqoop export \
--connect jdbc:mysql://hadoop02:3306/sqoopdb \
--username root \
--password root \
--table uv_info \
--export-dir /user/hive/warehouse/uv/dt=2011-08-03 \
--input-fields-terminated-by '\t'
直接指定hive在hdfs中存储的文件路径 和将hdfs中的数据导出mysql一样的
6.3导出hbase到mysql
很遗憾,现在还没有直接的命令将 HBase 的数据导出到 MySQL
一般采用如下 3 种方法:
1、将 Hbase 数据,扁平化成 HDFS 文件,然后再由 sqoop 导入
2、将 Hbase 数据导入 Hive 表中,然后再导入 mysql
3、直接使用 Hbase 的 Java API 读取表数据,直接向 mysql 导入,不需要使用 sqoop
7.sqoop的内部原理
7.1导入
从上面的演示例子中,我们大致能得出一个结论,sqoop 工具是通过 MapReduce 进行导入
作业的。总体来说,是把关系型数据库中的某张表的一行行记录都写入到 hdfs
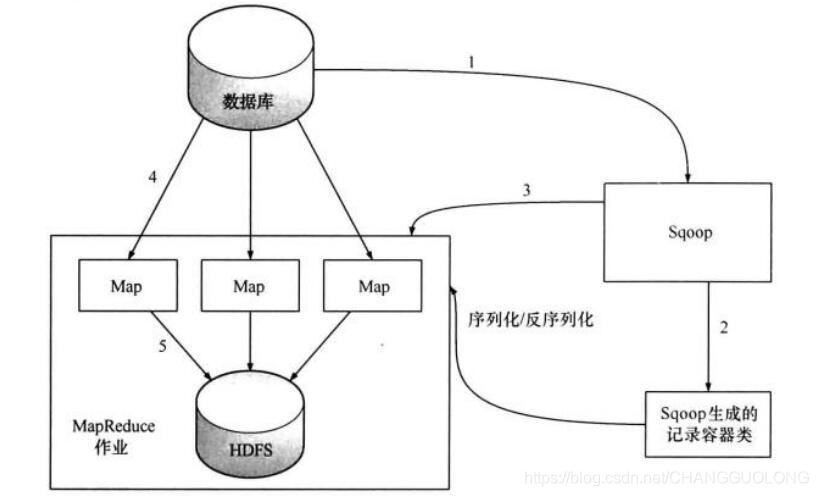
上面这张图大致解释了 sqoop 在进行数据导入工作的大致流程,下面我们用文字来详细描述一下:
1、第一步,Sqoop 会通过 JDBC 来获取所需要的数据库元数据,例如,导入表的列名,数据类型等。
2、第二步,这些数据库的数据类型(varchar, number 等)会被映射成 Java 的数据类型(String, int等),根据这些信息,Sqoop 会生成一个与表名同名的类用来完成序列化工作,保存表中的每一行记录。
3、第三步,Sqoop 启动 MapReducer 作业
4、第四步,启动的作业在 input 的过程中,会通过 JDBC 读取数据表中的内容,这时,会使用 Sqoop 生成的类进行反序列化操作
5、第五步,最后将这些记录写到 HDFS 中,在写入到 HDFS 的过程中,同样会使用 Sqoop 生成的类进行反序列化
7.2导出
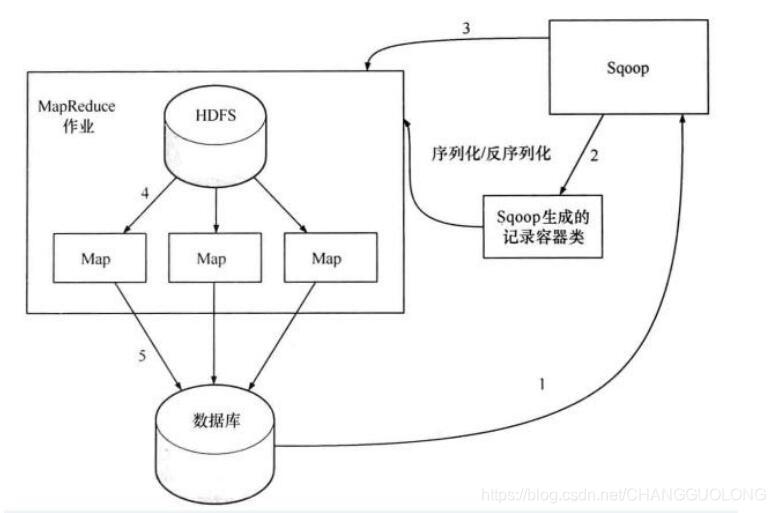
详细文字描述:
1、 第一步,sqoop 依然会通过 JDBC 访问关系型数据库,得到需要导出数据的元数据信息
2、 第二步,根据获取到的元数据的信息,sqoop 生成一个 Java 类,用来进行数据的传输载体。该类必须实现序列化和反序列化
3、 第三步,启动 mapreduce 作业
4、 第四步,sqoop 利用生成的这个 java 类,并行的从 hdfs 中读取数据
5、 第五步,每个 map 作业都会根据读取到的导出表的元数据信息和读取到的数据,生成一批 insert 语句,然后多个 map 作业会并行的向数据库 mysql 中插入数据所以,数据是从 hdfs 中并行的进行读取,也是并行的进入写入,那并行的读取是依赖 hdfs的性能,而并行的写入到 mysql 中,那就要依赖于 mysql 的写入性能嘞。

















 2374
2374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









