





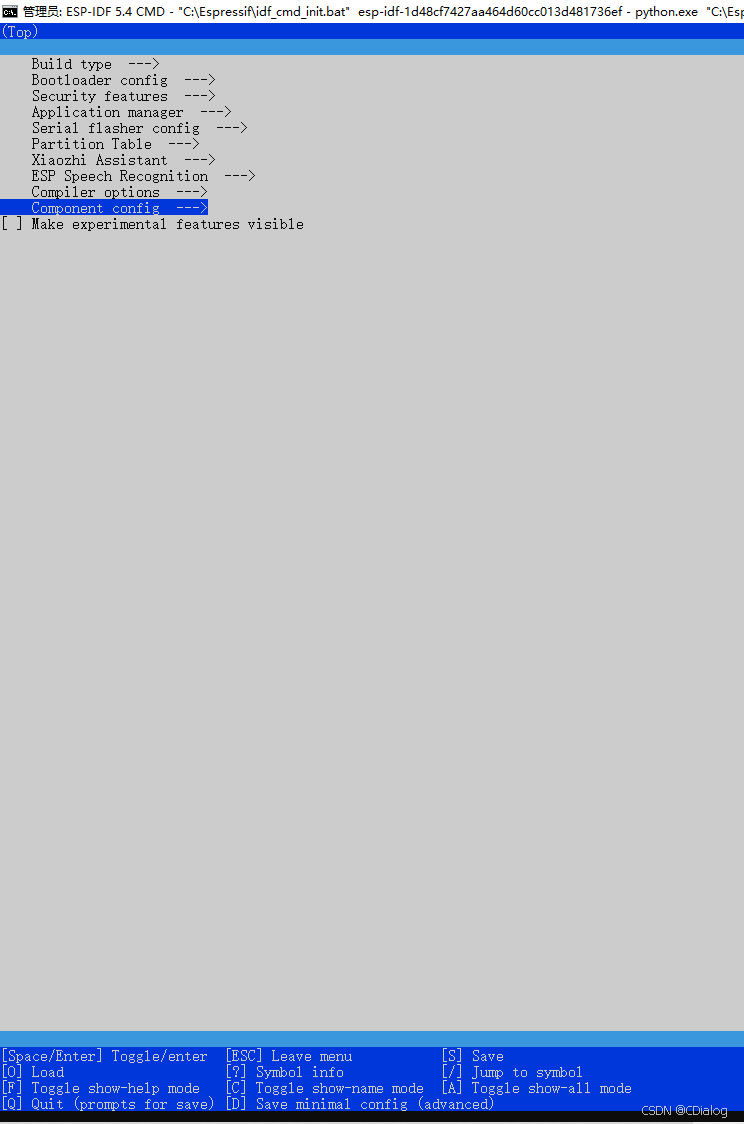
这个是小智机器人的代码中带的menuconfig,用来管理小智芯片,中间有自定义的菜单项目
第一次用这个,一脸的懵逼
然后官方有个文档解释
这里面指的是手工修改sdkconfig的内容,和菜单使用没啥关系,还是自己摸索吧
感谢这个哥们,哈哈哈
下来关于小智机器人代码
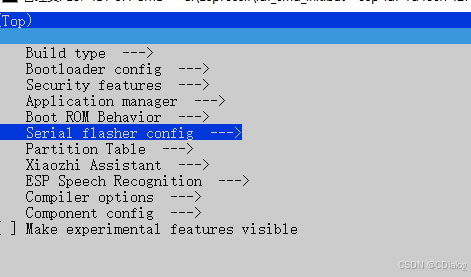
我用的是esp32S3的芯片,然后用的esp-idf命令行,没有用vscode开局就比较辛苦了
这个界面请选择对应的内存,我幸亏买了16M的,太小的话好像编译过来提示内存不够。
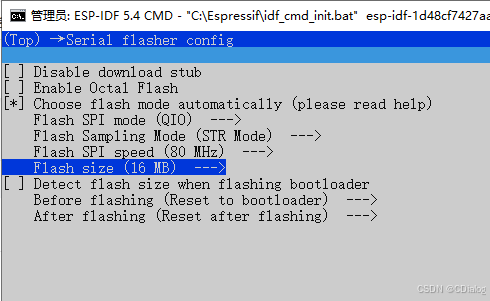
这个位置修改为16M,可以去掉内存不够的编译错误。

很重要的一点,一定要选择目标芯片esp32S3,否则提示
BoxAudioCodec 类的定义与实现不匹配,导致链接器无法找到某些符号(即类的成员函数未正确生成目标文件或未被正确链接)。
我看了代码,注意小智代码里有两个cmakelists.txt

所以必须
idf.py set-target esp32s3才能排除掉这几个音频文件
然后编译就正常了。
另外在menuconfig中也可以改掉几个信息,
#比如改变分区表配置文件,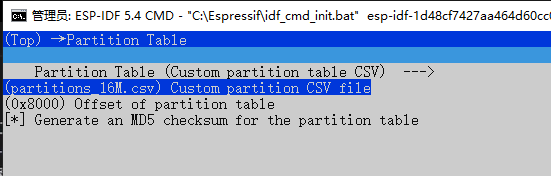
这在小智机器人的默认文件中没有,自己弄一个好了
#比如芯片自带的语音功能要关掉
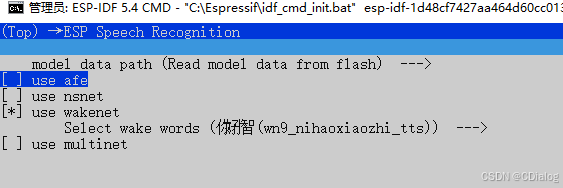
use wakenet这个要不要关掉我还不确定,等烧录后试试。反正use afe是要先关掉

如果烧录后不能唤醒,等后面我再试试打开
#比如关闭PSRAM模组
介绍:ESP32-S3 的 PSRAM(Pseudo Static Random Access Memory,伪静态随机存取存储器)是一种用于扩展运行时内存的存储器,具有以下特点和功能。
说白了,就是加内存用的,关掉
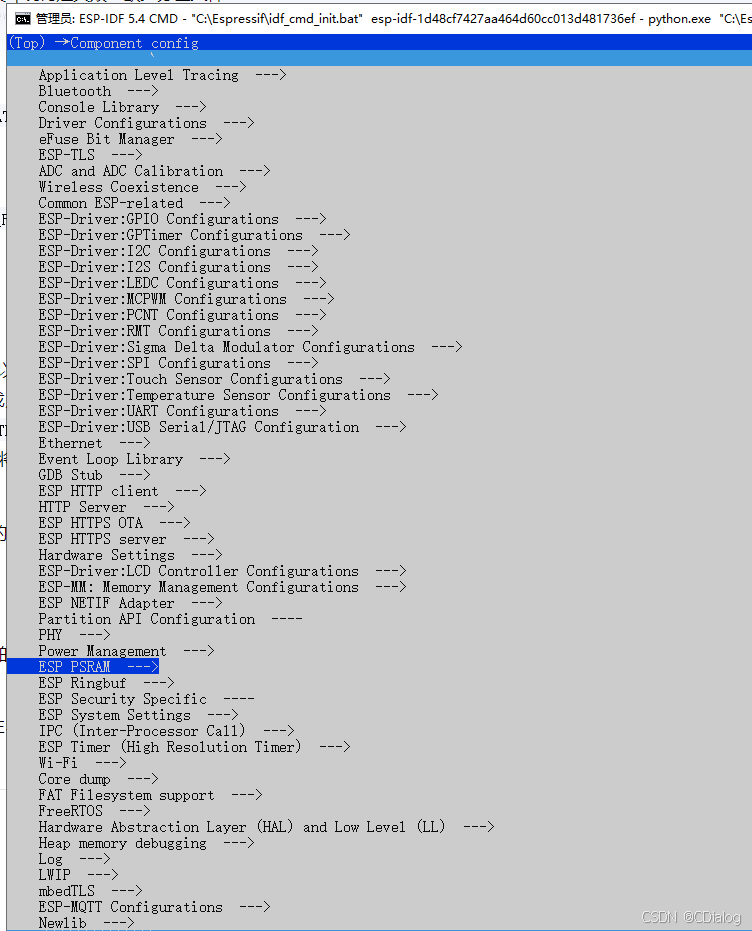
目录有点深
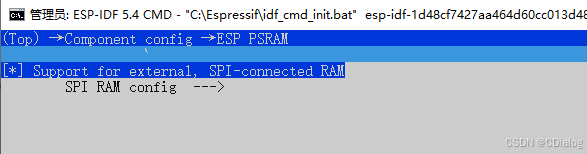
默认是打开的,关掉
==================================================
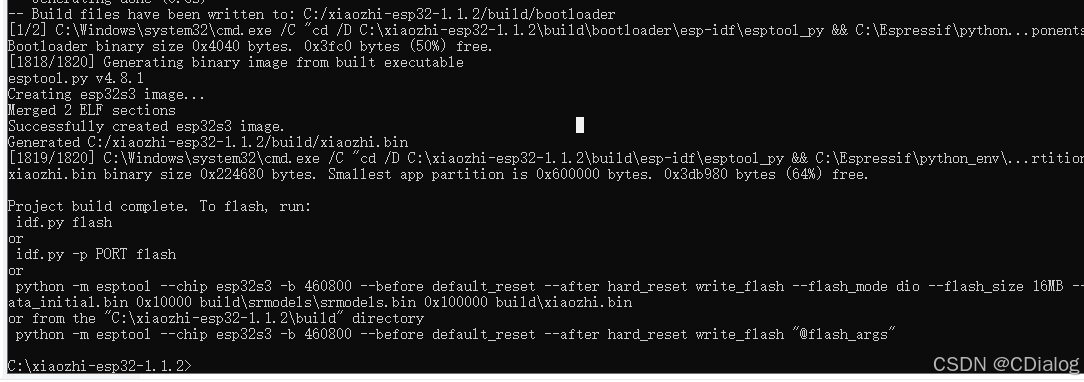
编译,成功


















 8357
8357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











