






 本文介绍了如何在PyTorch1.8.1中使用nn.Linear构建线性模型,并通过实例演示了如何使用Rprop、SGD、Adagrad、Adam、Adamax和ASGD等优化器进行模型训练,展示了不同优化器对损失函数的影响以及模型参数的变化。
本文介绍了如何在PyTorch1.8.1中使用nn.Linear构建线性模型,并通过实例演示了如何使用Rprop、SGD、Adagrad、Adam、Adamax和ASGD等优化器进行模型训练,展示了不同优化器对损失函数的影响以及模型参数的变化。
课堂代码+运行结果
nn.Linear()用法:Linear — PyTorch 1.8.1 documentation
import torch
from torch import nn, Tensor
import matplotlib.pyplot as plt
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])
class LinearModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(1, 1) # 输入一维,输出一维
def forward(self, input: Tensor) -> Tensor:
y_pred = self.linear(input)
return y_pred
model = LinearModel()
criterion = nn.MSELoss(reduction='sum')
# 使用不同的优化器观察图形
# Adagrad Adam Adamax ASGD RMSprop Rprop SGD
optimizer = torch.optim.Rprop(model.parameters(), lr=0.01)
plt.title("Rprop")
epoch_list = []
loss_list = []
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 使用梯度更新参数
epoch_list.append(epoch)
loss_list.append(loss.item())
plt.xlabel("epoch")
plt.ylabel("loss")
plt.plot(epoch_list, loss_list)
plt.show()
print(f"w = {model.linear.weight.item()}")
print(f"b = {model.linear.bias.item()}")
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print(f"y_pred = {y_test.data}")
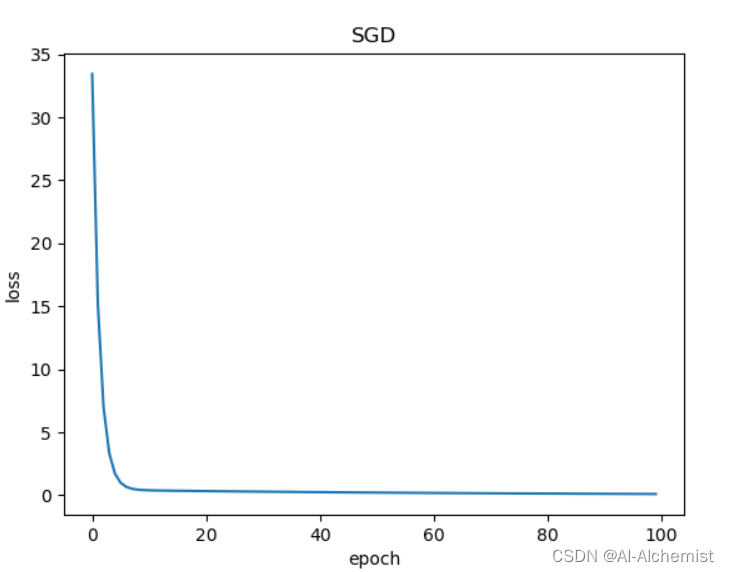
使用SGD:
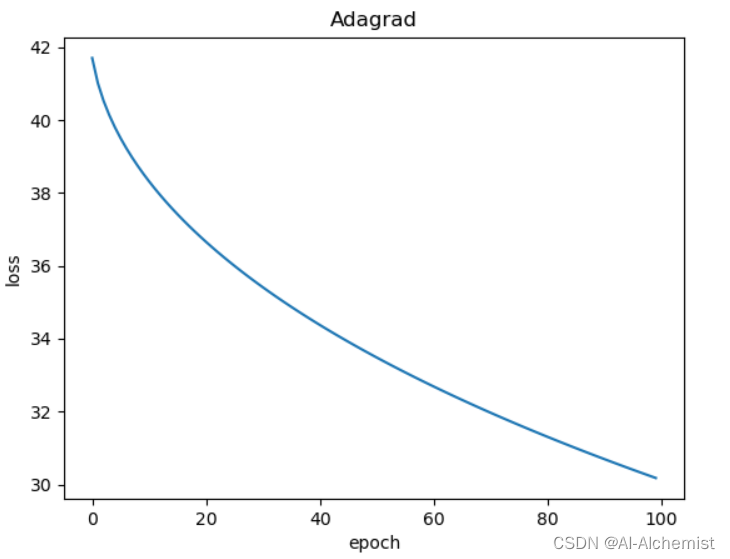
使用Adagrad:
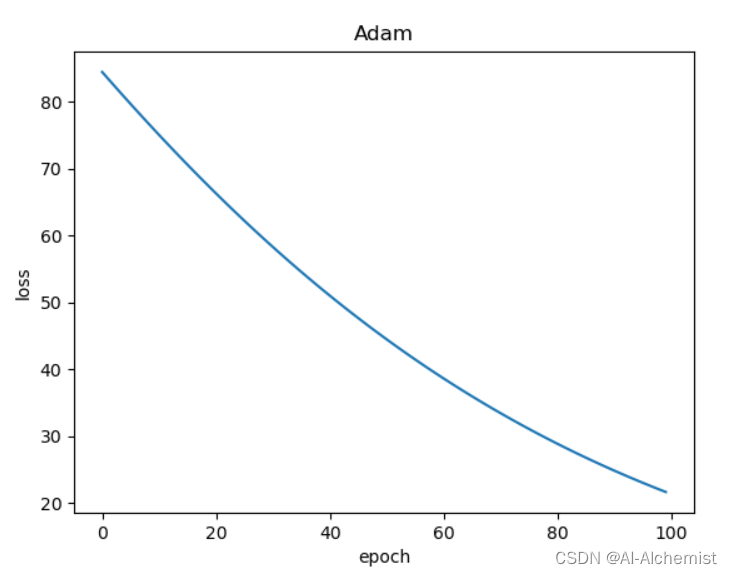
使用 Adam:
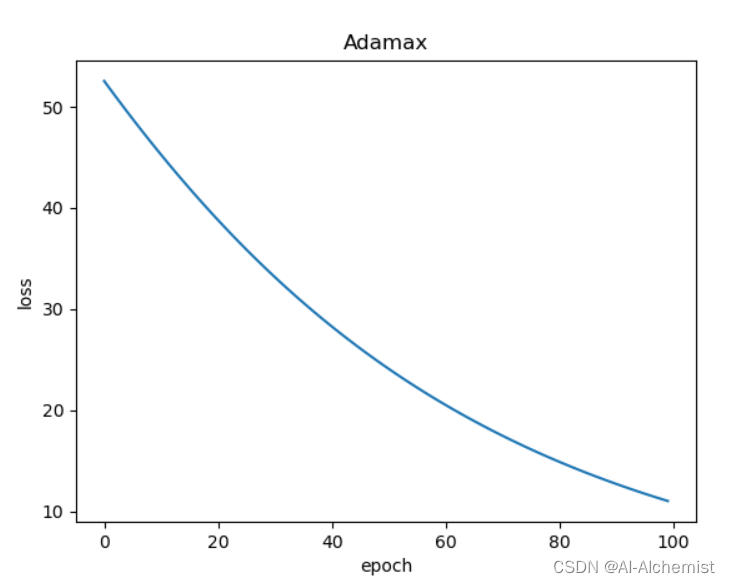
使用Adamax:
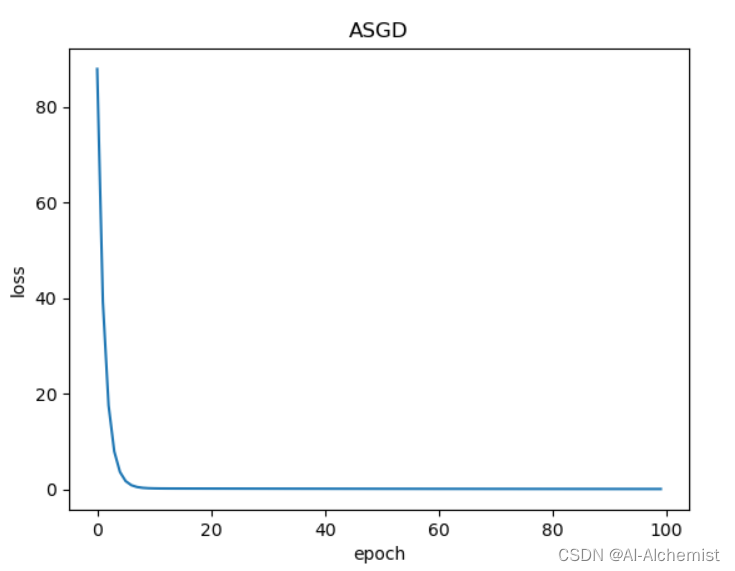
使用ASGD:(与SGD对比来看,效果比SGD好)
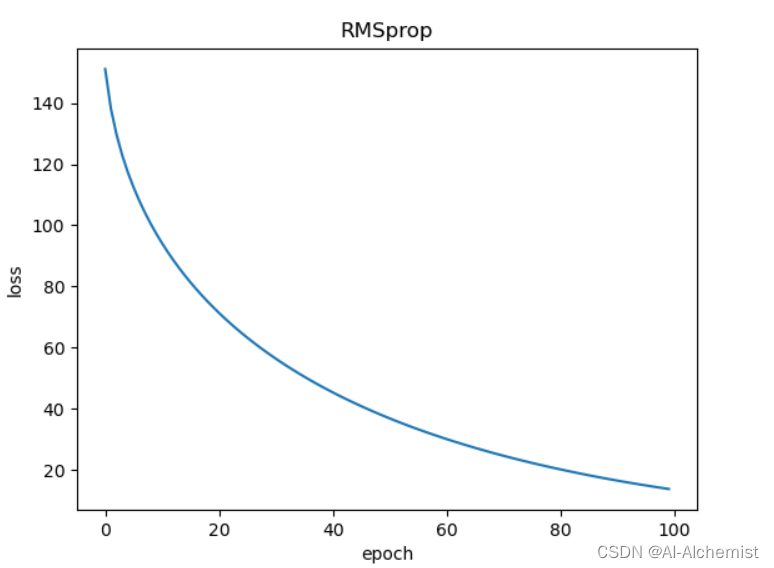
使用RMSprop:
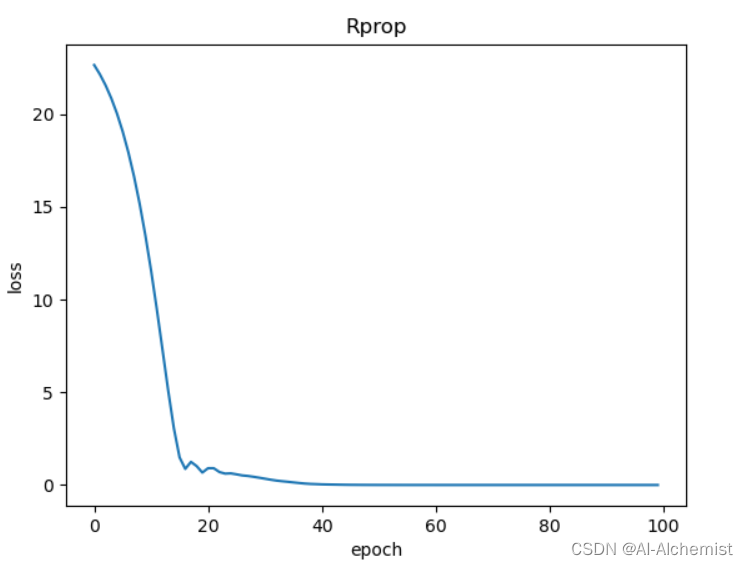
使用Rprop:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









