




 本文介绍了批量感知算法、Ho-Kashyap算法及MSE算法的原理与Python实现。批量感知算法通过梯度下降最小化误分类样本,Ho-Kashyap算法则通过最小化误差平方和来优化权重向量,MSE算法则适用于多分类任务。
本文介绍了批量感知算法、Ho-Kashyap算法及MSE算法的原理与Python实现。批量感知算法通过梯度下降最小化误分类样本,Ho-Kashyap算法则通过最小化误差平方和来优化权重向量,MSE算法则适用于多分类任务。
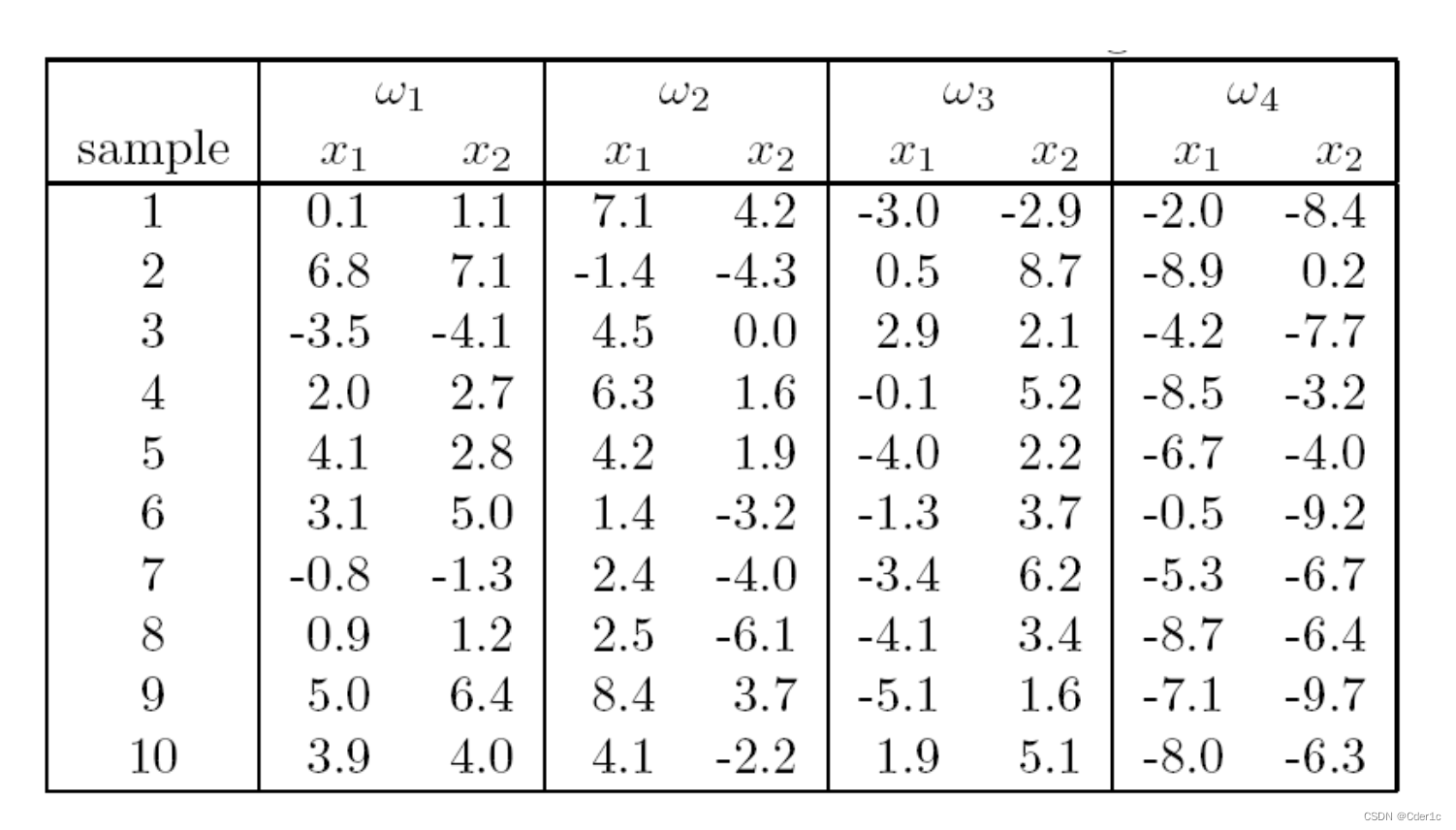
使用数据
Batch Perception算法
原理
设有一组样本 y 1 , y 2 , . . . , y n y_1,y_2,...,y_n y1,y2,...,yn,各样本均规范化表示,我们的目的是找一个解向量 a a a ,使 a T y i > 0 a^T y_i>0 aTyi>0。在线性可分的情况下,满足上式的 a a a是无穷的。所以要引出一个损失函数进行优化。这个准则的基本思想是错分样本最少:
J ( a ) = ∑ y ∈ Y ( − a T y ) J(a)=\sum_{y\in Y}(-a^{T}y) J(a)=∑y∈Y(−aTy)
Y Y Y为错分样本集合。我们采用梯度下降来优化目标函数:
∂ J ∂ a = ∑ y ∈ Y ( − y ) \frac{\partial J}{\partial a}=\sum_{y\in Y}(-y) ∂a∂J=∑y∈Y(−y)
则有:
a k + 1 = a k − η ∑ y ∈ Y ( − y ) a_{k+1}=a_{k}-η\sum_{y\in Y}(-y) ak+1=ak−η∑y∈Y(−y)
代码实现
# Define batch perception algorithm
# Input: w1, w2
# w1: Samples in class 1
# w2: Samples in class 2
# Output: a, n
# a: the parameters
# n: number of iterations
def batch_perception(w1, w2):
# Generate the normalized augmented samples
w = trans_sample(w1, w2)
# Initiation
a = np.zeros_like(w[1])
eta = 1 # Learning rate
theta = np.zeros_like(w[1])+1e-6 # Termination conditions
n = 0 # Number of iterations
# Implement the algorithm
while True:
y = np.zeros_like(w[1])
for sample in w:
if np.matmul(a.T, sample) <= 0:
# the sample is misclassified
y += sample
eta_y = eta * y
if all(np.abs(eta_y)<=theta):
# if the termination conditions are satisfied, terminate the iteration
break
a += eta_y
n += 1
print ("The dicision surface a is {}\nThe number of iterations is {}.".format(a, n))
return a, n
Ho-Kashyap算法
原理
刚才的准则函数都是关注于错分样本,而对正确分类的样本则没有考虑在内。MSE准则函数把求解目标从不等式形式变成了等式形式:求取满足 a T y i = b i a^T y_i=b_i aTyi=bi的权向量。在这里, b i b_i bi是任取的正常数。
如果记矩阵 Y ∈ R n ∗ d Y\in R^{n*d} Y∈Rn∗d且其每行都是一个样本 y T y^T yT,向量 b = [ b 1 , b 2 , . . . , b n ] T b=[b_1,b_2,...,b_n]^T b=[b1,b2,...,bn]T,那么就可以表述为存在 Y a = b > 0 Ya=b>0 Ya=b>0。为了求解这个问题,使用MSE准则函数:
J = ∣ ∣ Y a − b ∣ ∣ 2 = ∑ i = 1 n ( a T y i − b i ) 2 J=||Ya-b||^2=\sum_{i=1}^{n}(a^T y_i-b_i)^2 J=∣∣Ya−b∣∣2=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









